The Monthly BriefingWe have overcome this December 23th, 2020 | 8' reading time |
|

| |
|---|---|
|
The process of transforming a business need into a data-based product may in some cases look very much like the adventure of playing a video game. The long road is made up of several stages, -or screens, using the gaming terminology-. Screens that one must overcome one by one to finally achieve the final victory, which is none other than having the model productionised. Aspects such as the availability of data and its sources, the data ingestion & preprocessing stage or the model training are key to reach the final screen. However, other issues such as an accurate definition of the problem, a fluid communication between all the members of the team and a general knowledge of the tasks of all the teams involved are equally important to succeed. 
In this talk on December 10th at the SheStartup event, organized by AllWomen, our colleague Clara Higuera, explained how these stages have been overcome in a real use case using NLP techniques: a conversations classifier. Without a doubt, a masterly lesson on the daily work of a team that builds products based on data! Here you can watch the talks of the event. Thanks to AllWomen for inviting us! |
|
|
Further reading +The annual Open Data Maturity Report is now available. (European Data Portal) +Better understanding of how NLP models work. (Adam Geitgey · Medium) + The results of this year’s McKinsey Global Survey on Artificial Intelligence. (McKinsey) 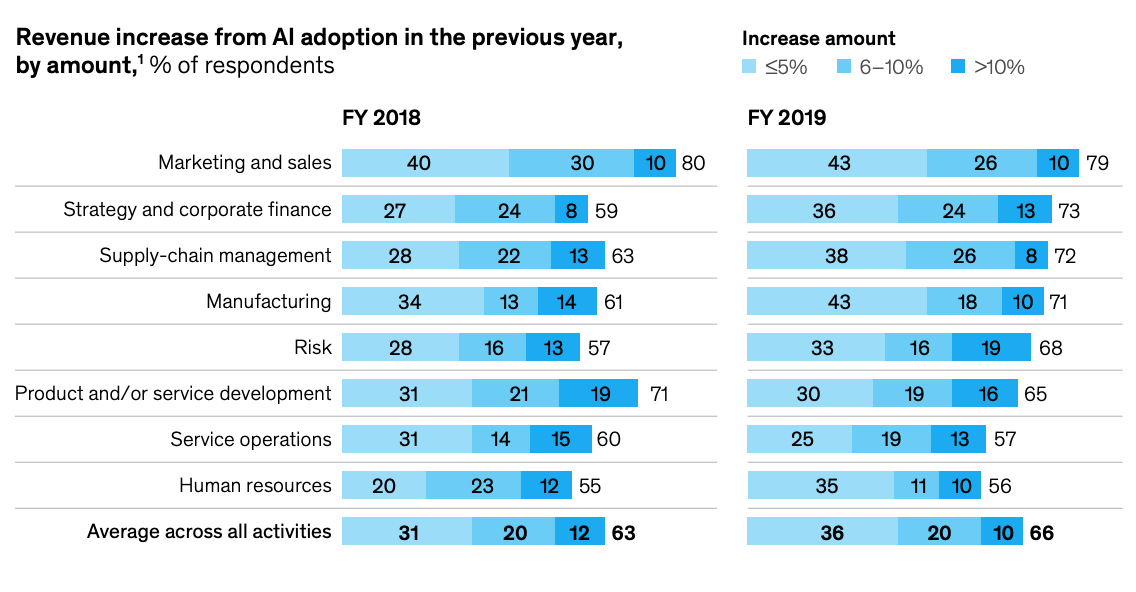
+Another summary of AI top stories of 2020 (a16z) + The EU wants to take control of its own data. (The Wall Street Journal) + A deep learning model to detect oil and gas infrastructure in aerial imagery. (Stanford ML Group) + How many different types of algorithms are trapping people in poverty (MIT Tech Review) + Can we smell data? (Nightingale · Medium) + The future of finance (Bloomberg) + What Spotify does to ensure raw data can be easily understood (Spotify) |
|

Quote of the month "AI is not fully ready to make the kind of decision-making corporates expect it to make and even if it were corporate teams and networks are not fully ready to implement and reap the full benefits of AI." Jennifer Schenker, Founder and Editor-in-Chief at The Innovator. 
The state of AI-decision making was the focus of an October 13 roundtable discussion moderated by The Innovator in partnership with DataSeries, a global network of data leaders led by venture capital firm OpenOcean. In this article, entitled AI Decision-Making: State Of Play And What’s Next, Jennifer Schenker writes a summary of the main ideas discussed in that session. |
|
|
Happy Holidays! All of us at BBVA Data & Analytics wish you a happy holidays and a great start to the new year! 💙 
|
|
For any question or suggestion, you can also write to hello@bbvadata.com You can enjoy much more content related to data science, innovation, new solutions of financial analytics and how we work in our website: bbvadata.com Let's talk about it. Join the conversation on Linkedin. |
|
© 2020 All rights reserved. BBVA Data & Analytics. Avenida de Manoteras, 44, 28050. Madrid. |