The Monthly BriefingKeep learning March 31st, 2021 | 6' reading time |
|

| |
|---|---|
|
It is often said that life is a succession of learnings, and, as a general rule, the older you get the more wisdom and experience you accumulate. Could this concept be applied to the building of AI models? With the emergence in 2018 of self-supervised language models such as BERT (Google) - trained on massive amounts of text - an era is beginning in which Transfer Learning is becoming a reality for Natural Language Processing (NLP), just as it has been for the field of Computer Vision since 2013. To improve the way in which we interact with our clients, at BBVA AI Factory we have experimented with Transfer Learning techniques applied to models in different languages. But, what is Transfer Learning? We refer to Transfer Learning when we reuse knowledge acquired from performing a task to tackle new similar tasks. However, most Machine Learning algorithms can only solve the task for which they were trained. Let's imagine a Chef who has learnt to cook ravioli carbonara. The goal of Transfer Learning is for our Chef to be able to apply what s/he has learnt, - in this case, cooking pasta - to make a decent spaghetti Bolognese. 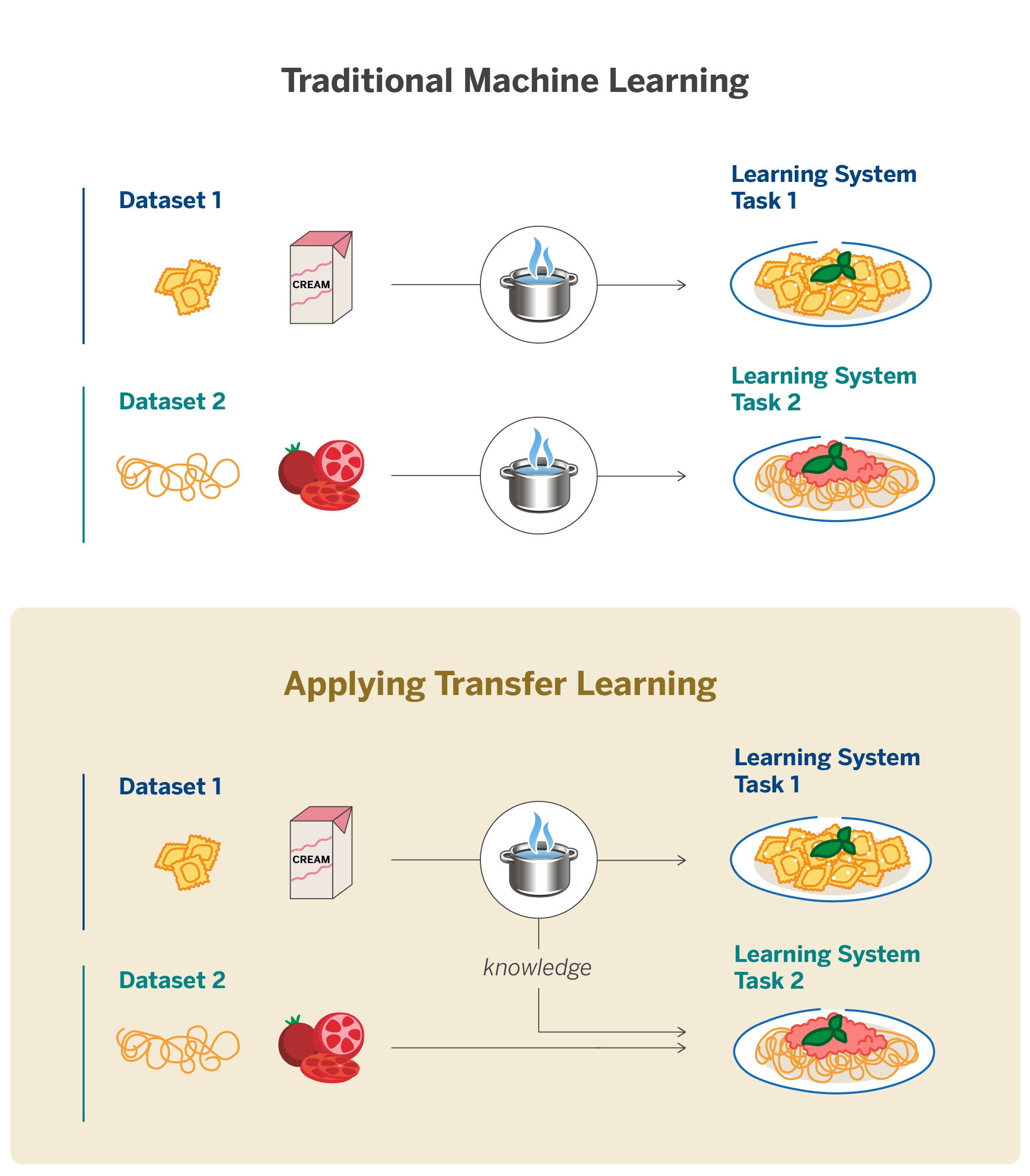
Check out this article on how we applied Transfer Learning in Natural Language Processing, in order to process texts in different languages faster. You can also watch it in this video! |
|
|
A nice chat with BEDROCK Highly recommended this podcast (Spanish: episode 2, season 2) from BEDROCK - Data by Design. Our colleague María Hernandez Rubio talks about the work we do at the AI Factory - no question is too many! 
Maria tells how the work in data science has evolved after years of implementation. From the early more exploratory stages, to productive stages where data models, ML or AI are part of complete data products; where other aspects come into play. Thank you so much both Bedrock Team and María for this conversation! |
|
|
Talking about AI in Playz (RTVE) Playz, RTVE's digital content channel for young people, has recently launched the programme Whaat!?, a space focused on the future of humanity. Our colleague Clara Higuera has participated in the technology-focused episode, in which she talks about what an analytical model does and urges us to think of Artificial Intelligence as a tool for improving our society. Don't miss it! 
|
|
|
Further reading +Which flavor of data professional are you? (Towards Data Science) +Goldman Cleared of Bias in New York Review of Apple Card (Bloomberg) +Data Scientists in Software Teams: State of the Art and Challenges (Microsoft | Miryung Kim, Thomas Zimmermann, Robert DeLine and Andrew Begel) 
+Fireside Chat with Andrew Ng (Royal Statistical Society) +Machine Learning into production (Idealista) +SEPLN (NLP Spanish Society) publishes the Natural Language Processing Strategy. (SEPLN) +How to approach a text classification problem (David Morcuende) +Your AI Model is ‘Wrong’ Yet It Can Transform Your Business (Towards Data Science | Ganes Kesari) |
|

Quote of the month "By itself, petabytes of data is of no consequence to decision making. To inform decisions, data needs to be processed. It needs to be transformed to make it valuable." Fred Senekal, Head Of Research And Development at Learning Machines 
In this article, Fred Senekal writes about the transformation process that data must undergo to become a high-value asset in an organisation. This process is made up of several phases in which data becomes first into information (what happened?), then into knowledge (why did it happen?), insights (what will happen?), and finally into a decision (what should I do?). |
|
|
This makes our days 😊 We are happy to help our customers in their day-to-day! 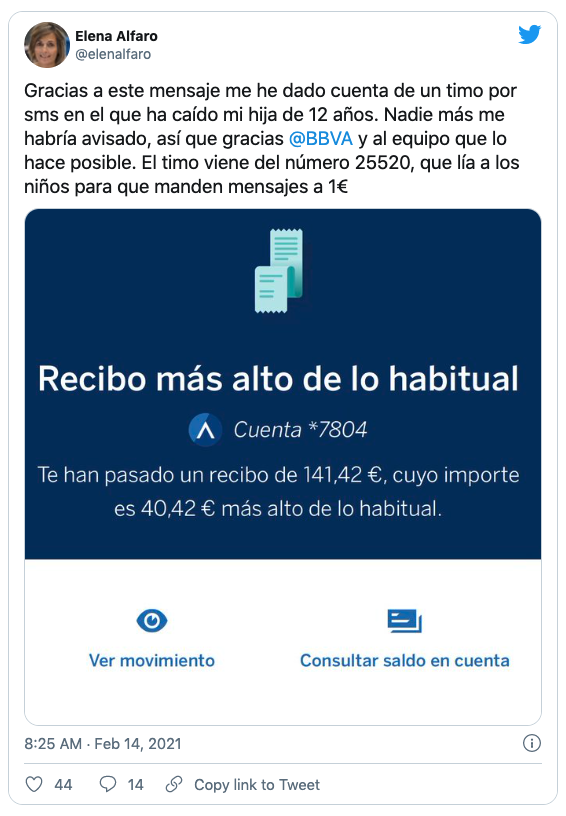
|
|
For any question or suggestion, you can also write to hello@bbvadata.com You can enjoy much more content related to data science, innovation, new solutions of financial analytics and how we work in our website: bbvaaifactory.com Let's talk about it. Join the conversation on Linkedin and Twitter. |
|
© 2021 All rights reserved. BBVA AI Factory. Avenida de Manoteras, 44, 28050. Madrid. |