
Applying Transfer Learning to Natural Language models
Natural Language Processing (NLP) has been one of the key fields of Artificial Intelligence since its inception. After all, language is one of the things that defines human intelligence. In recent years, NLP has undergone a new revolution similar to the one that took place 20 years ago with the introduction of statistical and Machine Learning techniques. This revolution is led by new models based on deep neural networks that facilitate the encoding of linguistic information and its re-use in various applications. With the emergence in 2018 of self-supervised language models such as BERT (Google) – trained on massive amounts of text – an era is beginning in which Transfer Learning is becoming a reality for NLP, just as it has been for the field of Computer Vision since 2013.
The concept of Transfer Learning is based on the idea of re-using knowledge acquired by performing a task to tackle new tasks that are similar. In reality, this is a practice that we humans constantly engage in during our day-to-day lives. Although we face new challenges, our experience allows us to approach problems from a more advanced stage.
Most Machine Learning algorithms, particularly when supervised, can only solve the task for which they have been trained by examples. In the context of the culinary world, for example, the algorithm would be like a super-specialised chef who is trained to make a single recipe. Asking this algorithm for a different recipe can have unintended consequences, such as making incorrect predictions or incorporating biases.
The aim of using Transfer Learning is for our chef – the best at cooking ravioli carbonara – to be able to apply what s/he has learnt in order to make a decent spaghetti bolognese. Even if the sauce is different, the chef can re-use the previously acquired knowledge when cooking pasta (figure 1).

This same concept of knowledge re-use, applied to the development of Natural Language Processing (NLP) models, is what we have explored in collaboration with Vicomtech, a Basque research centre specialised in human-machine interaction techniques based on Artificial Intelligence. Specifically, the aim of this joint work has been to learn about the applications of Transfer Learning and to assess the results offered by these techniques, as we see that they can be applicable to natural language interactions between BBVA clients and managers. After all, the purpose of this work is none other than to improve the way in which we interact with our clients.
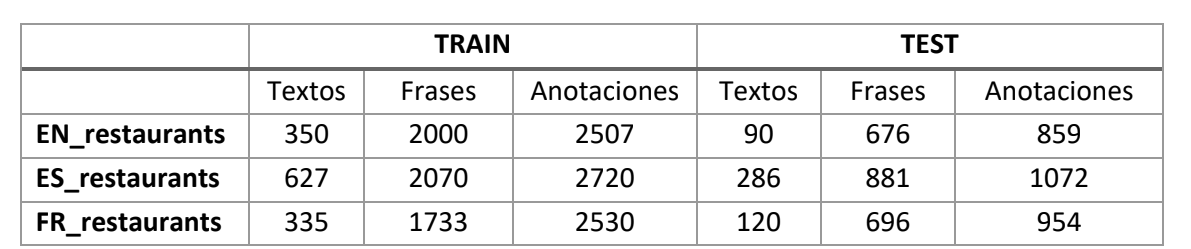
One of the tasks we have tackled has been the processing of textual information in different languages. For this purpose, we have used public domain datasets. This is the case of a dataset of restaurant reviews, generated for the Semeval 2016 academic competition, which includes reviews in English, Spanish, French, Russian, Turkish, Arabic and Chinese. The aim has been to identify the different aspects or characteristics mentioned (food, ambience or customer service, among others), in English, Spanish and French (Table 1).
With this exercise we wanted to validate whether Transfer Learning techniques based on the use of BERT models were appropriate for adapting a multi-class classifier to detect aspects or characteristics in different languages. In contrast to this approach, there are alternatives based on translating the text to adapt it to a single language. We can do this by translating the information we will use to train the model, on the one hand, or by directly translating the conversations of the clients we want to classify. However, there are also problems and inefficiencies with these alternatives.
Taking the culinary example we mentioned at the beginning of this article, in our case we could consider the texts as representing the ingredients of the recipe. These datasets of information differ from one language to another (just as the ingredients vary according to the recipe). On the other hand, the ability acquired by the model to classify texts is knowledge that we can re-use in several languages; in the same way that we re-use the knowledge about how to cook pasta with different recipes.
In this experiment we have started from a pre-trained multilingual BERT model in the public domain, and we have performed fine tuning on the restaurant dataset. The following figure shows the procedure (figure 2).
The results obtained by adapting this model, trained with generic data, to the dataset of reviews in each language, were similar to those reported in 2016 for the task in English, French and Spanish by more specialised models. This is consistent with the results of a variety of research on the ability of this type of model to achieve very good results.
Once a classifier for an English text has been tuned, the Transfer Learning process is carried out by performing a second stage of fine tuning with the second language dataset (Figure 3).
To measure the effectiveness of the process, we compare the behaviour of this classifier with the behaviour resulting from performing a single fine tuning stage starting from the multilingual base model.
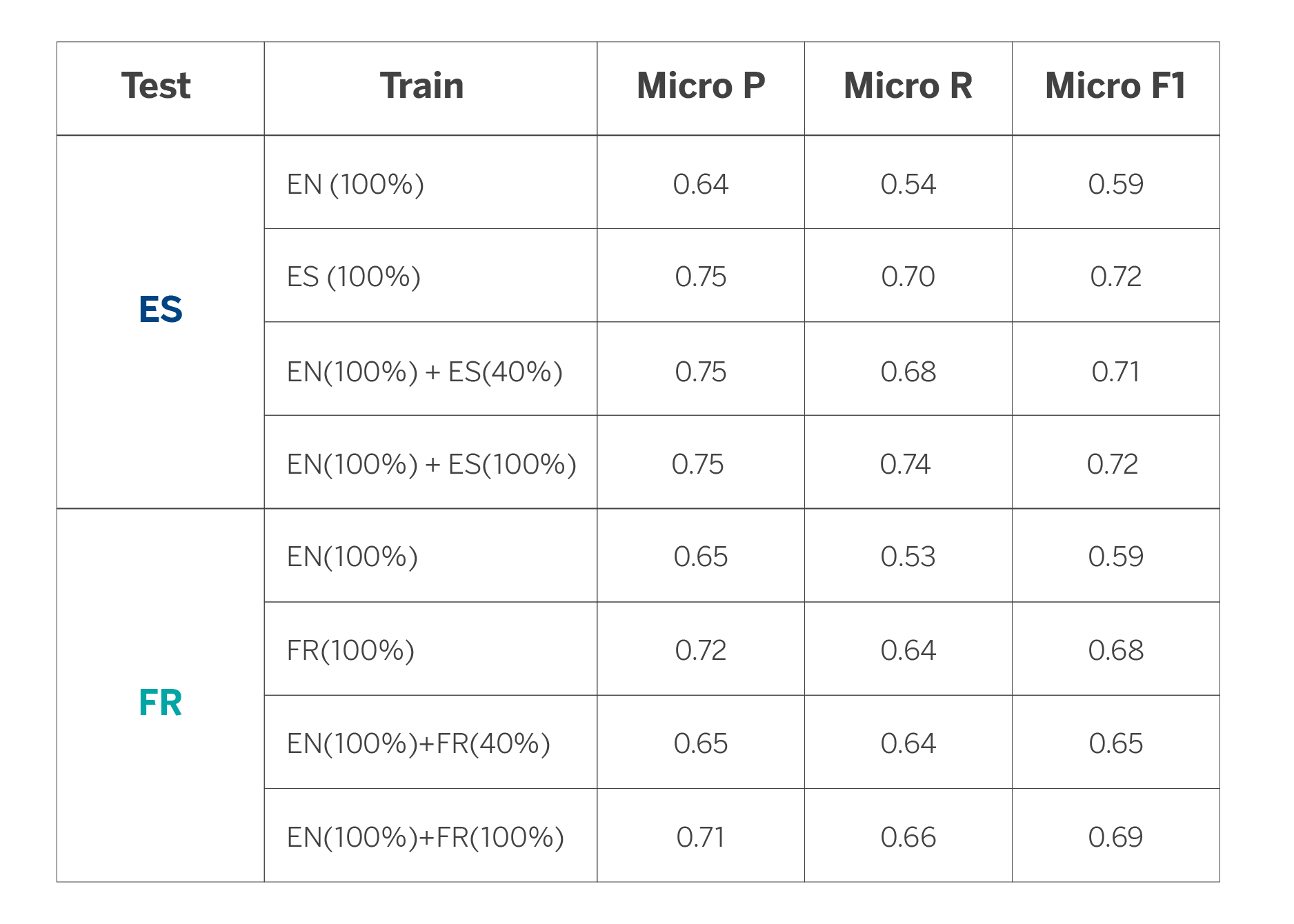
The results show us (see Table 2) that by starting with the model in English and using less data than the target language (In this case Spanish or French) we can achieve similar results to those obtained by adapting a model for each language. For example, in the case of Spanish, we would reach a similar performance if we start from the English model and add only 40% of the data in Spanish. On the other hand, in the case of French, the results begin to be equal when using the English model and 80% of data in French. Finally, if we use all the available data, the results improve moderately when compared to the results we achieved when training only with data for each language. However, there is a marked improvement when using the English model for the other languages. It is important to bear in mind that these results will depend on the specific task to which they are applied.
These results are very encouraging from the point of view of an application to real problems, since they would indicate that the models are capable of using the knowledge acquired in one language to extrapolate it to another language, thus obtaining the same quality with less labelled data. In fact, one of the main obstacles when developing any NLP functionality in an industrial environment is having a large amount of quality data, and having to develop this for each given language. Therefore, requiring less labelled data is always a great advantage when developing functionalities.
The knowledge gained (or “transfered”) from this collaboration with Vicomtech will allow us to build more agile functionalities to help managers in their relationship with the client, hence reducing the development cycle of a use case in a language or channel other than the one in which it was originally implemented.