
A random search at NeurIPS 2019
The conference was held in Vancouver, Canada from December 8-14, and was organized with tutorials, workshops, demos, presentations and poster sessions. In this article we summarize some relevant aspects of the event.
Some numbers
With approximately 13,000 people registered, this was the largest edition of NeurIPS to date. There was a record number of 6,743 articles submitted (49% more than the previous year’s edition), reviewed and commented on by a total of 4,543 reviewers, resulting in 1,428 accepted articles (i.e. an acceptance rate of 21.6%). There were 9 tutorials and 51 workshops with a variety of topics such as: reinforcement learning, bayesian machine learning, imitation learning, federated learning, optimization algorithms, representation of graphs, computational biology, game theory, privacy and fairness in learning algorithms, etc.
In addition, there were a total of 79 official NeurIPS meetups in more than 35 countries from 6 continents. These meetups are local events in which the content of the live conference is discussed; most of these were held in Africa (28) and Europe (21). For a more detailed description of the issues included this edition of NeurIPS we recommend the following post.
A fun little demonstration of the scale of #NeurIPS2019 – video of people heading into keynote talk.
— Andrey Kurenkov (@andrey_kurenkov) December 12, 2019
This is 9 minutes condensed down to 15 seconds, and this is not even close to all the attendees! pic.twitter.com/1VqAHZoqtj
Industry presence
As outlined in this excellent post with some statistics on the articles accepted for NeurIPS 2019, we can note the significant presence of authors with affiliations to large technology companies. For example, in the top-5 institutions with the highest number of accepted articles, Google (through Google AI, Google Research or DeepMind) and Microsoft Research appear together with MIT, Stanford University, and Carnegie Mellon University. In the top-20 we can also appreciate industry presence with Facebook AI Research, IBM Research, and Amazon. Below is a list of the sites of each of the companies with the greatest presence at the event, where they list the articles, tutorials and workshops in which they participated.
- Google AI
- Microsoft Research
- Facebook AI Research
- IBM Research
- Amazon
- Intel AI
- Nvidia Research
- Apple
As expected, most of the research of these companies is still oriented towards language understanding, translation between languages, voice recognition, visual and audio perception, etc. We note that a large part of the research has been aimed towards designing new variants of BERT-based language models and tools for understanding the representations that they produce 1 2 3 4. For a more detailed description of several articles related to BERT and Transformers in NeurIPS 2019, we recommend this post.
Additionally, we were able to appreciate the amount of research on the part of these companies (with or without collaboration of academic institutions), directed towards the fields of multi-agent reinforcement learning 5 6 7, motivated by the data that can be obtained through the interaction of multiple agents in real scenarios on the Internet, and multi-armed bandits 8 9 10, where the work focuses particularly on contextual bandits 11 12, motivated by applications related to personalization and web optimization.
On the other hand, while the increasing industrial presence at this conference is enriching, it is also true that the unofficial and exclusive events organized by the companies can divert the focus from the scientific and inclusionary objectives of the conference.
Trends
According to the analysis of the program chair of this edition of NeurIPS, Hugo Larochelle, the category that obtained the greatest increase in its acceptance rate with respect to the previous edition was neuroscience.
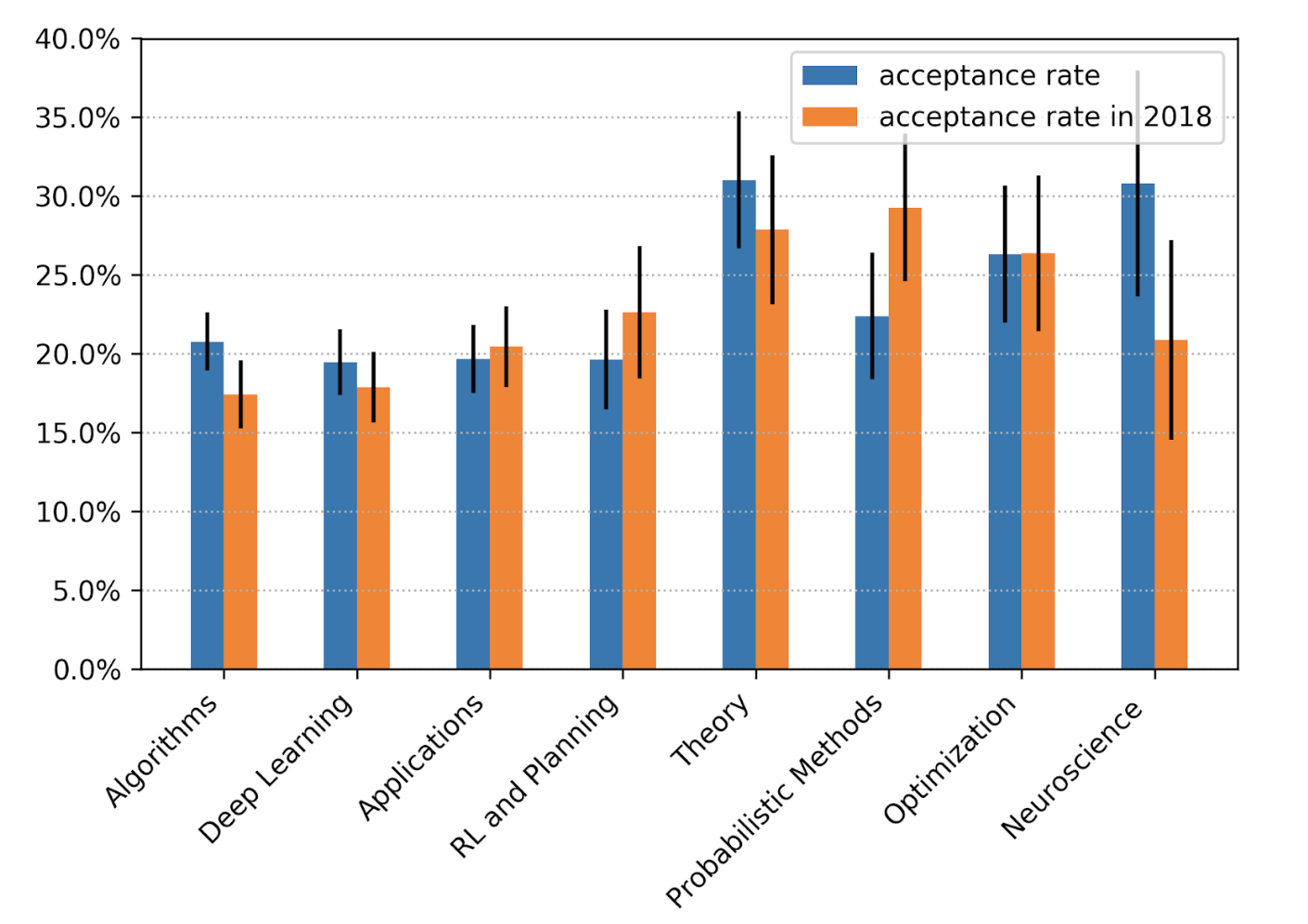
On the other hand, comparing the keywords of the accepted articles from 2019 and 2018, described in this excellent post by Chip Huyen, we can see which topics have gained or lost presence compared to last year.
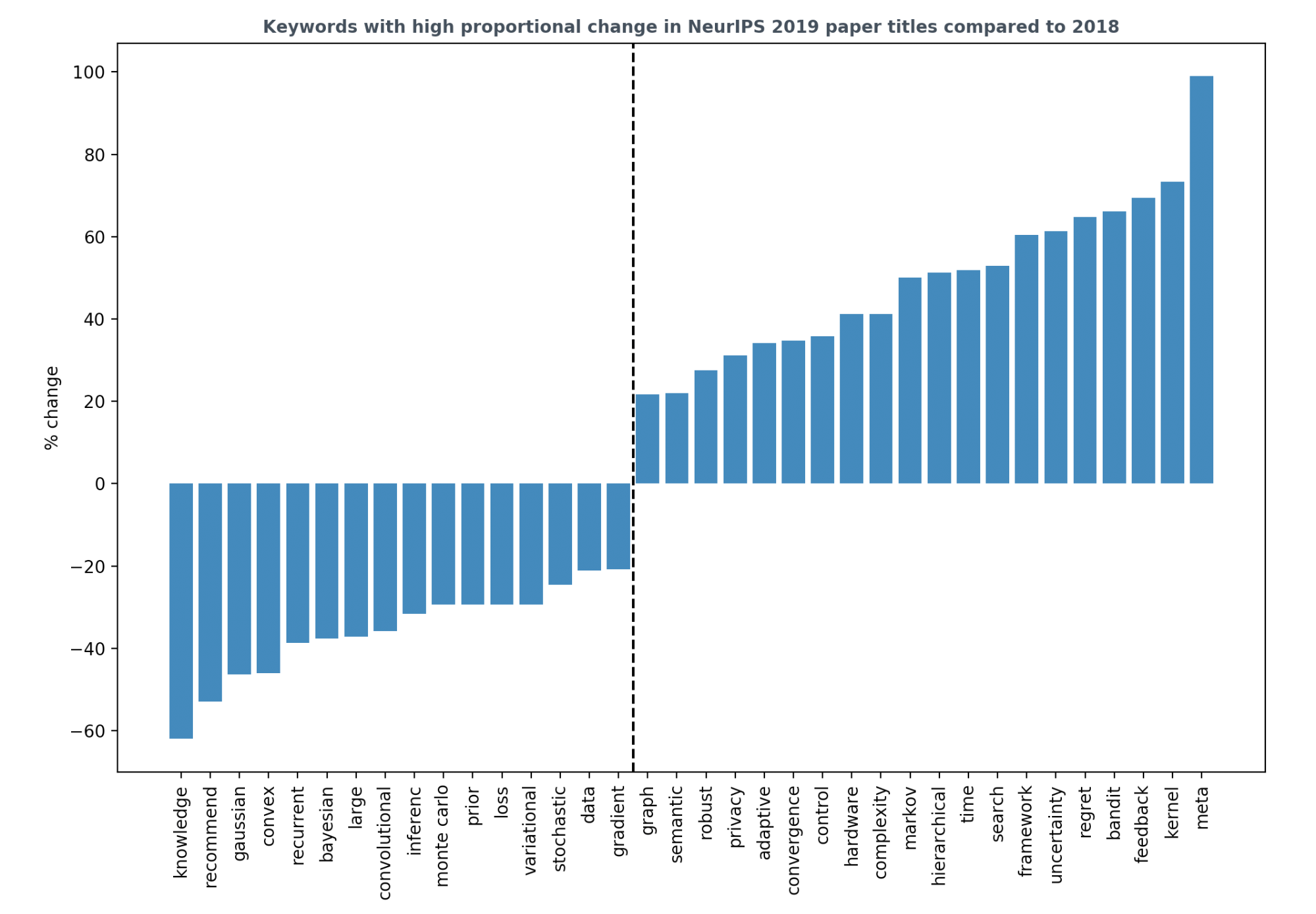
Main findings:
- Reinforcement learning is gaining significant ground. In particular, the algorithms based on multi-armed bandits and contextual bandits. This trend can be seen in the high recurrence of words such as “bandit”, “feedback”, “regret”, and “control”.
- Recurrent and Convolutional Neural Networks seem to be losing ground. At least in the case of recurrent ones, it is likely that this is due to the fact that since NeurIPS 2017, all we need are attention mechanisms.
- The words “hardware” and “privacy” are gaining ground, reflecting the fact that there is more work related to the design of algorithms that take into account hardware architectures, or issues related to privacy.
- Words like “convergence”, “complexity” and “time” are also gaining ground, reflecting the growing research in theory related to deep learning.
- Research related to graph representation is also on the rise, and Kernel-based methods seem to be enjoying a resurgence, as evidenced by positive percentage changes in the words “graph” and “kernel”, respectively.
- Interestingly, although the percentage change of Bayesian decreases, the percentage change of uncertainty increases. This could be due to the fact that in 2018 there were numerous projects related to Bayesian principles not exactly related to deep learning (e.g. Bayesian optimization, Bayesian regression, etc.), while in 2019 there was a greater tendency to incorporate uncertainty, and in general, probabilistic elements into deep learning models.
- “Meta” is the word with the highest positive percentage change, reflecting the fact that meta-learning algorithms in their various variants are becoming popular (e.g. graph meta-learning, meta-architecture search, meta-reinforcement learning, meta-inverse reinforcement learning, etc).
Award-winning articles
In this edition of NeurIPS there was a new category called Outstanding New Directions Paper Award. According to the organizing committee, this award is given to highlight work that distinguishes itself by establishing lines of future research. The winning paper was Uniform Convergence may be unable to explain generalization in deep learning. Broadly speaking, the article explains both theoretically and empirically that Uniform Convergence Theory cannot explain the ability of deep learning algorithms to generalize on its own, so it therefore calls for the development of techniques that do not depend on this particular theoretical tool to explain the ability to generalize.
On the other hand, the Test of Time Award – a prize given to a paper presented at the NeurIPS ten years ago and which has shown to have a lasting impact in its particular field – was given to Dual Averaging Method for Regularized Stochastic Learning and Online Optimization. Here, very broadly speaking, Lin Xiao proposed a new algorithm to solve convex online optimization problems in order to exploit the L1 regularization structure and that provides theoretical guarantees.
To check out the complete list of articles that have received recognition, please consult this post written by the organizing committee. For a more detailed discussion of some of the award-winning articles this post is strongly recommended.
Tutorials
Tutorials are sessions of a couple of hours duration that aim to present recent research on a particular topic by a leading researcher in their field. We had the opportunity to attend two of these:
- Deep Learning with Bayesian Principles. Emtiyaz Khan listed concepts of deep learning and Bayesian learning to establish similarities and differences between the two. Among the main differences, he argued that while deep learning uses a more empirical approach, using Bayesian principles forces the establishment of hypotheses from the beginning. In this sense, Khan’s work focuses on reducing the gap between the two. During the tutorial, he showed how from Bayesian principles it is possible to develop a theoretical framework where the most used learning algorithms in the deep learning community (SGD, RMSprop, Adam, etc.) emerge as particular cases. In our opinion, the material presented in this tutorial is exquisite and it is impressive to see how such optimization techniques can be deduced in an elegant way through probabilistic principles.
- Reinforcement Learning: Past, Present, and Future Perspectives. Katja Hofmann presented a fairly comprehensive overview and historical review of the most significant advances in the field of reinforcement learning. In addition, as a conclusion, Katja pointed out future opportunities in both research and real applications, with emphasis on the field of multi-agent reinforcement learning, especially in collaborative environments. We believe that this tutorial presents excellent material for those who want to get started in the study of reinforcement learning and for those who want to be aware of present and future lines of research in this field.
Workshops
Workshops are sessions of several hours duration that are organized as part of the conference, consisting of lectures and poster sessions, and that seek to promote knowledge and collaboration in emerging areas. We had the opportunity to be present mainly in the following:
- Deep Reinforcement Learning: This workshop was one of the best attended and brought together researchers working at the intersection of reinforcement learning and deep learning. The poster sessions were very rich and rewarding and, as expected, there was a big presence of researchers from DeepMind, Google Research and BAIR.We recommend this talk by Oriol Vinyals on recent advances in DeepMind with StarCraft II using multi-agent reinforcement learning tools.
- Beyond First Order Methods in ML: This workshop started from the premise that second and higher order optimization methods are undervalued in applications to machine learning problems. During the workshop, topics such as second-order methods, adaptive gradient-based methods, regularization techniques, etc. were discussed. In particular, we recommend this talk by Stephen Wright, a prominent figure within the optimization community, on smooth and non-convex optimization algorithms.
Other workshops that we attended in part were Bayesian Deep Learning and The Optimization Foundations of Reinforcement Learning. We strongly recommend reviewing the material relating to these.
Poster sessions

Here is small selection of valuable articles that we saw during the poster sessions and that we want to share with you in this section:
- Multilabel reductions: what is my loss optimising?. This paper describes popular choices of target functions to address multi-label classification problems and argues that, although these have been shown to be empirically successful, we do not understand about how they relate to the two most popular metrics for these types of problems: precision@k and recall@k. The article seeks to fill that gap and provides a formal justification for both ways of choosing the target function.
- PyTorch: An Imperative Style, High-Performance Deep Learning Library. This is the most recent PyTorch article par excellence. Here the authors detail the principles that drove the implementation of PyTorch and how these are reflected in the architecture.
- rlpyt: A Research Code Base for Deep Reinforcement Learning in PyTorch. This presents the rlpyt project, which includes PyTorch implementations of the most common algorithms used in deep reinforcement learning. It also supports the interface of OpenAI Gym environments.
- The PlayStation Reinforcement Learning Environment (PSXLE). This presents the PSXLE project, a modified PlayStation emulator designed to be used as a new environment for evaluating reinforcement learning algorithms. It also supports the OpenAI Gym interface.
- Competitive Gradient Descent: This paper addresses certain types of Gradient Descent applications from the point of view of competitive optimization and presents a new algorithm to obtain the solution that corresponds to Nash’s balance in a two-player game. This work is interesting because it is related to problems that arise in reinforcement learning or in deep learning (e.g. in GAN’s, with the generating network and the discriminating network in a competitive game).
Conclusions
To sum up, NeurIPS 2019 was a huge and enriching event, as well as overwhelming. The high number of attendees posed certain challenges in terms of some aspects of the conference. For instance, interacting properly with the authors of the papers during the poster sessions. Indeed, due to the large number of papers and topics it became impossible to strike an ideal balance between exploration and exploitation during the workshop talks and poster sessions. Hence, a random search seems to be the best strategy. Nevertheless, we still managed to discover papers and lines of research that have served for intellectual growth and inspiration.
References
- Emily Reif, Ann Yuan, Martin Wattenberg, Fernanda B. Viegas, Andy Coenen, Adam Pearce, Been Kim ↩︎
- Jiasen Lu, Dhruv Batra, Devi Parikh, Stefan Lee ↩︎
- Wei-Cheng Chang, Hsiang-Fu Yu, Kai Zhong, Yiming Yang, Inderjit Dhillon ↩︎
- Benjamin Hoover, Hendrik Strobelt, Sebastian Gehrmann ↩︎
- Nicolas Carion, Nicolas Usunier, Gabriel Synnaeve, Alessandro Lazaric ↩︎
- Alexander Peysakhovich, Christian Kroer, Adam Lerer ↩︎
- Sai Qian Zhang, Qi Zhang, Jieyu Lin ↩︎
- Yogev Bar-On, Yishay Mansour ↩︎
- Soumya Basu, Rajat Sen, Sujay Sanghavi, Sanjay Shakkottai ↩︎
- Sumeet Katariya, Ardhendu Tripathy, Robert Nowak ↩︎
- Santiago Balseiro, Negin Golrezaei, Mohammad Mahdian, Vahab Mirrokni, Jon Schneider ↩︎
- Dylan J. Foster, Akshay Krishnamurthy, Haipeng Luo ↩︎