Accelerating Data Science Workflows
There are many possible answers to the question “What does a Data Scientist Do?”. But a short one that we especially like is: “Use data to help reduce inefficiencies in products, services or processes”. So we see retail companies employing Data Scientists to try to make shipments more efficient, while in banking we use it to predict the next likely transaction and save the customer time.
But the work carried out by a Data Science team is not free from inefficiencies itself. Very likely, readers will have come across statements such as “feature engineering takes 90% of the work”. This is why some tools propose to automate feature engineering. Or maybe you heard “data preparation is the most annoying task”. This is why some companies have also developed tools to browse internal data more efficiently. From an external perspective, you could probably call these tools “Data Science for Data Scientists” – except Data Scientist would probably not use that name.
A prominent example of “full assistance” for Data Scientists (and more generally, other Machine Learning users) is Google’s AutoML, a suite of easy-to-use ML services built around the concept of neural architecture search and transfer learning. In one of its services, AutoML offers users with limited amount of ML expertise to upload image datasets and start building models with a few clicks. This is an example of “commoditization” of Machine Learning tools: allowing non-experts to access the benefits of Machine Learning technologies.
However, this fast commoditization also poses some challenges, and, indeed some people believe that these products are “destroying Data Science jobs”. Nevertheless, is it a fair question to say that a Data Scientist job can be automated? In our opinion, a more accurate question would be: which tasks that usually fall under the Data Scientists’ responsibilities can be automated, or facilitated?
What does a Data Scientist do?
Efforts to document “the Data Science process” are almost as old as Data Science. In fact, many of these “processes” inherit from Crisp-DM, a methodology (originally designed for data mining), that defines a Data Science task as a process with the following broad steps:
- Business Understanding
- Data Understanding
- Data Preparation
- Modeling
- Evaluation
- Deployment
This has been the basis for proposing many models of “Data Science process” in industry1 . Another example, this time focusing on user experience projects and the importance of prototyping can be read in this post by Fabien Girardin.
At BBVA D&A, our colleagues César de Pablo and Juan Carlos plaza made an effort to actually document a comprehensive workflow of Data Science tasks in projects, and it looks like the figure below.
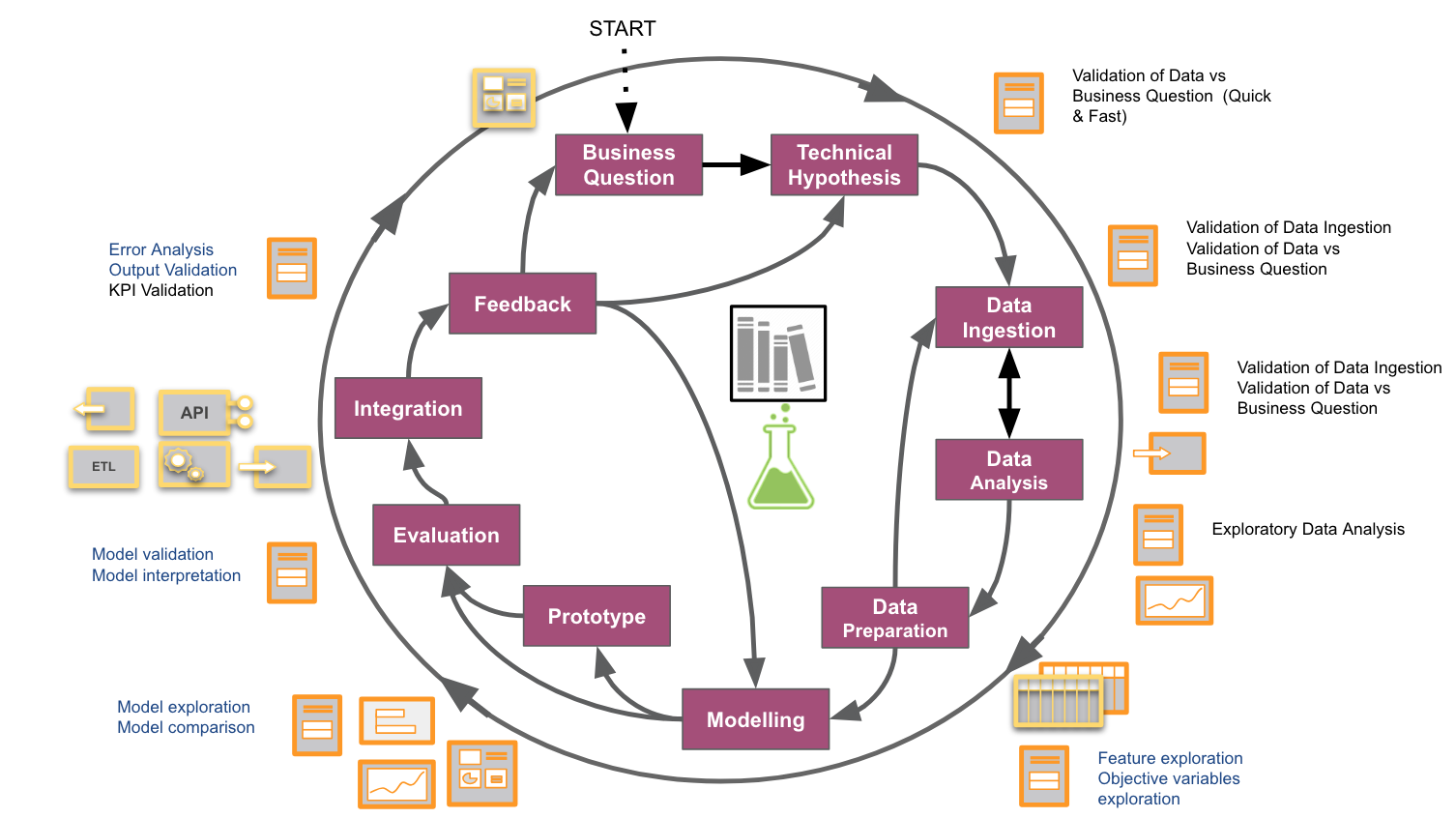
With our projects increasing in number and diversity, we felt the need to abstract and document our workflow, not only for our own understanding and improvement, but also to figure out how to best fit into corporate practices such as Agile processes, or to disseminate a data-driven culture. We built this process by looking from our own perspective at the work developed in the previous references and by illustrating each step with the specific subtasks involved. While this figure might be specific for us, and every Data Science project is different, those familiar with Data Science will probably recognize many common steps.
Algorithms to assist or automate Data Science tasks: A curated list of examples
We believe that replacing Data Scientists by Data Science algorithms, despite some claims, is closer to science-fiction than to reality.
While going deep into the ‘whys’ would probably be the subject of another blog post, we would mention two main factors here:
- Data Science workflows commonly contain “unknown unknowns”. One example is that, as discussed in the book Agile Data Science 2.0, it is difficult to state if a project is viable until after having worked with the data — since the amount / format / quality / content of data will determine whether an application is viable or not. This is a key difference with respect to traditional software projects. Or, many times, you do not know if a data product is useful to a customer until you put it in the hands of your customer (see the diagram above). All in all, Data Science is an iterative process where each step builds on from (human) learnings from previous steps.
- The job of a Data Scientist involves a lot of domain knowledge: choice of the right question, data source, metric, constraints, even before setting up a pipeline that can be automated. In fact, one key contribution of a Data Scientist is to bridge technical tools (built or bought) with (human) domain knowledge.
However, once you have acquired enough experience in a domain, it is possible to identify patterns of repetitive problems or identify commonalities between pipelines, and so build solutions to save time in the future. The industry and open source community has actually been active at releasing solutions to reduce inefficiencies in data science workflows. We provide a curated list of examples, below:
- Tools to help Data Discovery
- Amundsen: Data discovery and metadata engine to facilitate search within corporate databases.
- Tools for Data Exploration:
- Tensorflow Data Validation: Explore datasets quickly using the Tensorflow framework.
- InspectDF: A R tool to summarize, inspect and visualize information within dataframes.
- Feature search and reuse:
- FeatureTOOLS: Discover attributes from tabular data
- Ludwig: A toolbox to reuse representations (embeddings and/or architecture layers) in deep learning for complex types like text and images.
- We have explored embeddings of domain-specific entities (clients) in the client2vec use case below.
- HyperParameter search:
- Gpyopt: Replace hyperparameter grid search by exploration/exploitation scheme using Bayesian optimization.
- Neural Architecture search
- ML pipeline definition and optimization
- TPOT: A python library described as “your Data Science Assistant” allowing to define ML pipelines and performing automatic end-to-end optimization.
- TransmogrifAI: A Spark/Scala library to set up and optimize ML pipelines.
- ML Model Validation and Evaluation
- What if Tool: A visual interface that allows easy exploration and interpretation trained models, understand the influence of features and the outcome of examples.
- SHAP: a unified approach to explain black-box model prediction including latest advancements.
- Uber Manifold : a tool for model comparison and debugging that may be used to validate model outputs on different subsets of data or compare models results in production.
- Model Deployment:
- Amazon Sagemaker : a framework for creating, training and deploying online machine learning models with a focus on making deployment as easy as possible for common use cases.
There are probably many other examples. In fact, as of the writing of this post, there are 32 repositories in GitHub with the label “automated-machine-learning”.
Our take: Embeddings of users
This section briefly describes an experimental use case within BBVA D&A where we attempted to develop a “generic template” to solve a specific type of recurrent problem. We do not dare to call it “design pattern for Data Science” to avoid misusing engineering jargon, since the term “design pattern” has specific technical connotations.
In our case, we found that some applications at BBVA related with user experience, such as the compare yourself, or recommender systems, were about finding a representation of the user based on their data, normally called the “embedding”, and then applying some classification or regression algorithm on top of this embedding. We observed these embeddings were constructed from scratch for every new application.
So we thought: if you give Data Scientist pre-computed embeddings and an efficient way to retrieve them, you offer a tool for Data Scientists to try those readily available embeddings before embarking on the construction of more complicated and application-tailored embeddings. The first objection is always: how can I obtain domain-independent embeddings? But there are many examples in the Machine Learning community where generic embeddings of entities have been obtained which can then be reused (and optimized against) specific end-tasks. Probably, one of the most well-known cases is that of word embeddings and word2vec.
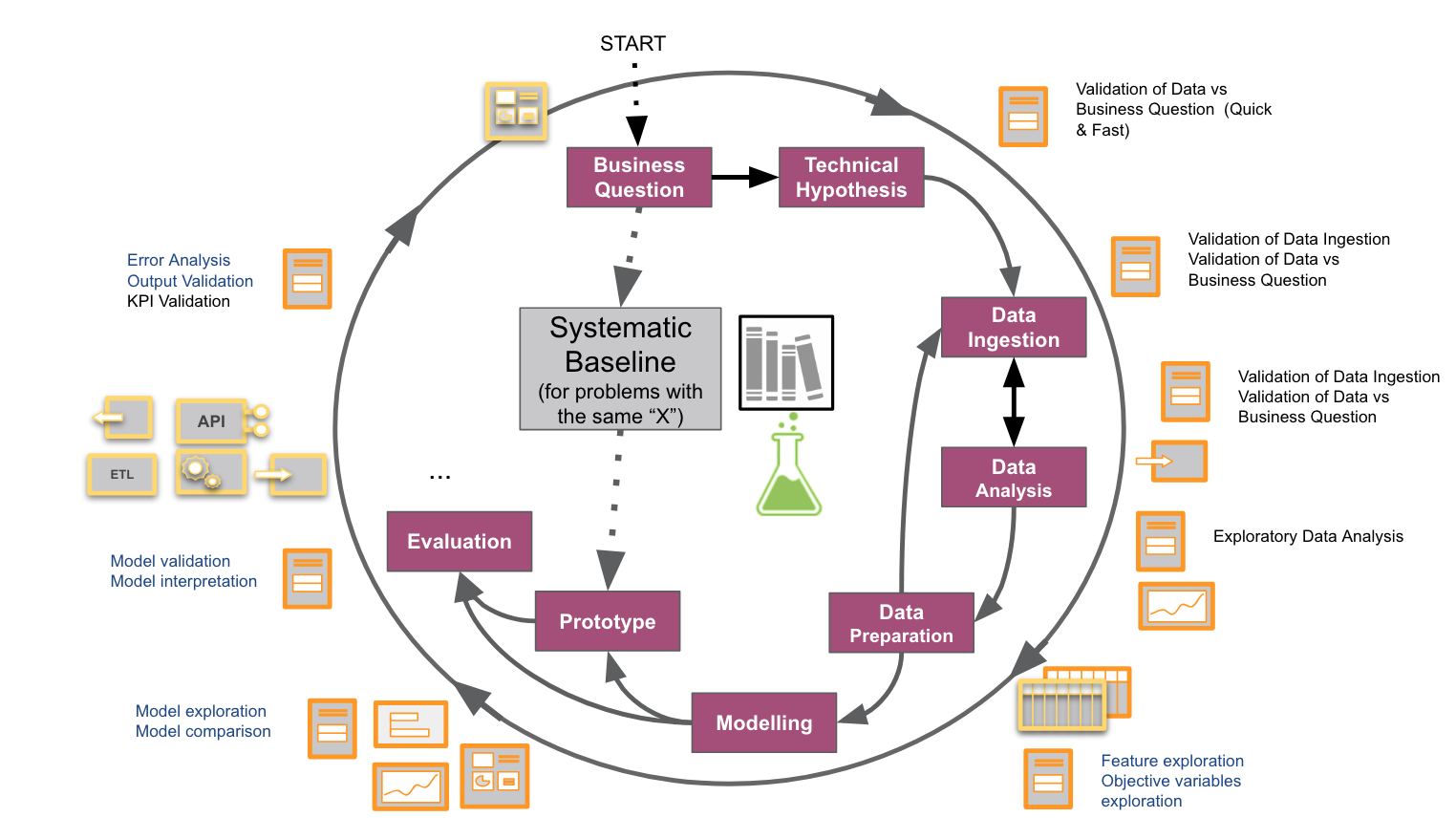
As shown in the figure above, we can imagine this as a shortcut in the previous workflow so that we can make a step from “Business question” to prototype very quickly. Of course, this will probably not be (and can be quite far from) the most optimized model. But there are two advantages. First, that “shortcut” gives us a very cheap, initial learning cycle. Learning is important, especially in the first phases of a project: when validating a new idea. Second, what if the performance using the pre-computed embeddings was enough for your idea?
This is what was proposed in our experimental client2vec paper, which describes an internal research carried out to gain insights about these approaches. We note “commoditizing” embeddings has been carried out at companies such as Twitter or Spotify.
At BBVA D&A we are constantly trying other similar tools such as Bayesian optimization or our own dedicated pipeline automation for specific types of models. Do you know how to apply this type of techniques or know other examples?