
An AWS re:Invent 2021 recap
⎋ See twitter thread
Last December we had the opportunity to attend AWS re:Invent 2021 in person and learn first-hand about the new features announced by Amazon Web Services, especially those related to Machine Learning.
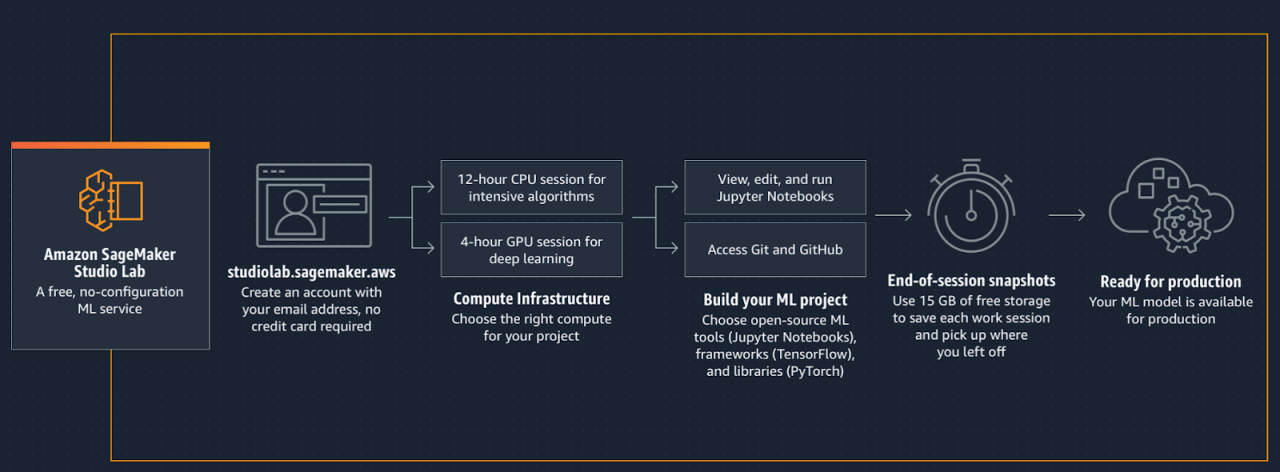
SageMaker Studio Lab
This is the free, simplified version of SageMaker Studio. It is a Machine Learning development environment that provides persistent storage (up to 15 GB) and compute capacity (CPU and GPU, with 16 GB of RAM) for free. It also allows integration with the rest of the AWS tools through the Python SDKs (both Sagemaker SDK and Boto3), making it easy to prototype at no cost, and then use the rest of the AWS resources when necessary. On the other hand, it is also an additional option for learning and putting Machine Learning into practice, in addition to Google Colab and the Kaggle notebooks. We recommend this post where ingenious tests are carried out to compare the three environments.
⎋ Announcement
⎋ Service
⎋ Video
SageMaker Inference Recommender
This new service is able to run multiple tests automatically related to model inference and recommend to the user: the type of compute instance, the number of instances, configuration parameter values of the containers hosting the code for inference, among other things. This allows objective, evidence-based decisions to be made regarding the deployment of models to optimise costs, and also saves valuable time for developers.
⎋ Announcement
⎋ Repository examples
⎋ Video

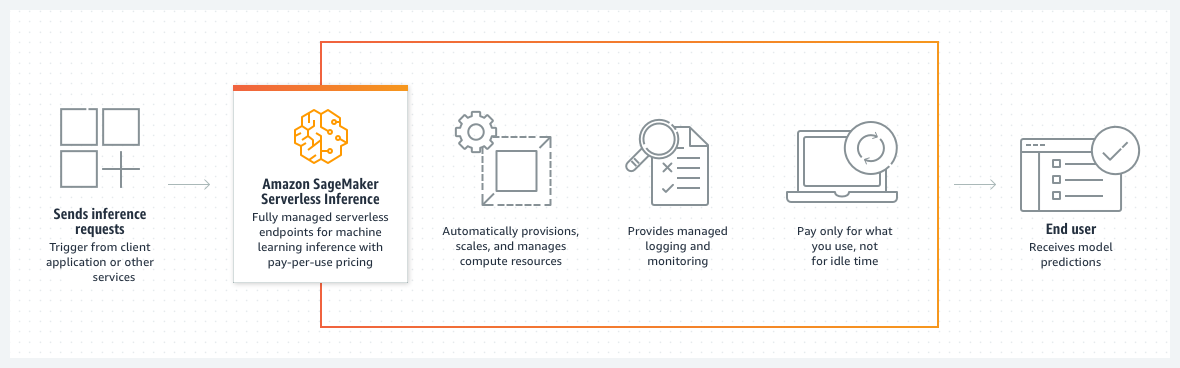
SageMaker Serverless Inference
This new service integrates Lambda and SageMaker, and is designed to perform inference on applications with intermittent or unpredictable traffic. Prior to this service, the inference options in SageMaker were real-time inference, batch inference, and asynchronous inference. Now, the new Serverless Inference option is capable of automatically provisioning and scaling compute capacity based on request volume.
⎋ Announcement
⎋ Repository examples
⎋ Video
SageMaker Canvas
This is a visual, codeless tool designed for business analysts and other less technical profiles to be able to build and evaluate models, as well as make predictions about new data, through an intuitive user interface. In addition, models generated in Canvas can then be shared with data scientists and developers to make them available in SageMaker Studio.
SageMaker Ground Truth Plus
This is a new labelling service for creating high quality datasets for use in training Machine Learning models. Ground Truth Plus uses innovative techniques from the scientific community, such as active learning, pre-tagging and automatic validation. While SageMaker Ground Truth already existed as of 2019, allowing the user to create data tagging workflows and manage tagging staff, SageMaker Ground Truth Plus creates and manages these workflows automatically without the need for user intervention.
SageMaker Training Compiler
This new feature of SageMaker automatically compiles model training code written in a Python-based Machine Learning framework (TensorFlow or PyTorch) and generates GPU kernels specific to those models. In other words, SageMaker Training Compiler converts models from their high-level language representation to hardware-optimised instructions, so that they will use less memory and less computation and, therefore, train faster.
⎋ Announcement
⎋ Repository examples
⎋ Video
EMR on SageMaker Studio
This new feature integrates EMR and SageMaker Studio. Prior to this feature, SageMaker Studio users had some ability to search for EMR clusters already created and connect to them, as long as these clusters were running on the same account as the SageMaker Studio session. However, users could not create clusters from SageMaker Studio, but had to manually configure them from EMR to do so. In addition, being restricted to creating and managing clusters in a single account could become prohibitive in organisations working with many AWS accounts. Now, with this new feature, SageMaker Studio users can manage, create, and connect to Amazon EMR clusters from within SageMaker Studio, as well as connect to and monitor Spark jobs running on these clusters.
⎋ Announcement
⎋ Repository examples
Beyond the announcements
In addition to the announcements of new features in SageMaker that took place at the event, there are other features that are not exactly new but which we had the opportunity to learn about during the event through presentations, workshops, or informal chats. Here we comment a bit on some of them.
RStudio on SageMaker
This feature is a result of the collaboration between AWS and RStudio PBC and was announced in November 2021. As a result of this collaboration, the RStudio development environment is now available in SageMaker, adding to the SageMaker Studio environment option, which is based on the JupyterLab project. With this addition, data scientists and developers now have the freedom to choose between programming languages and interfaces to switch between RStudio and Amazon SageMaker Studio. All work developed in either environment (code, datasets, repositories and other artefacts) is synchronised through the underlying storage in Amazon EFS.
⎋ AWS Announcement
⎋ RStudio PBC announcement
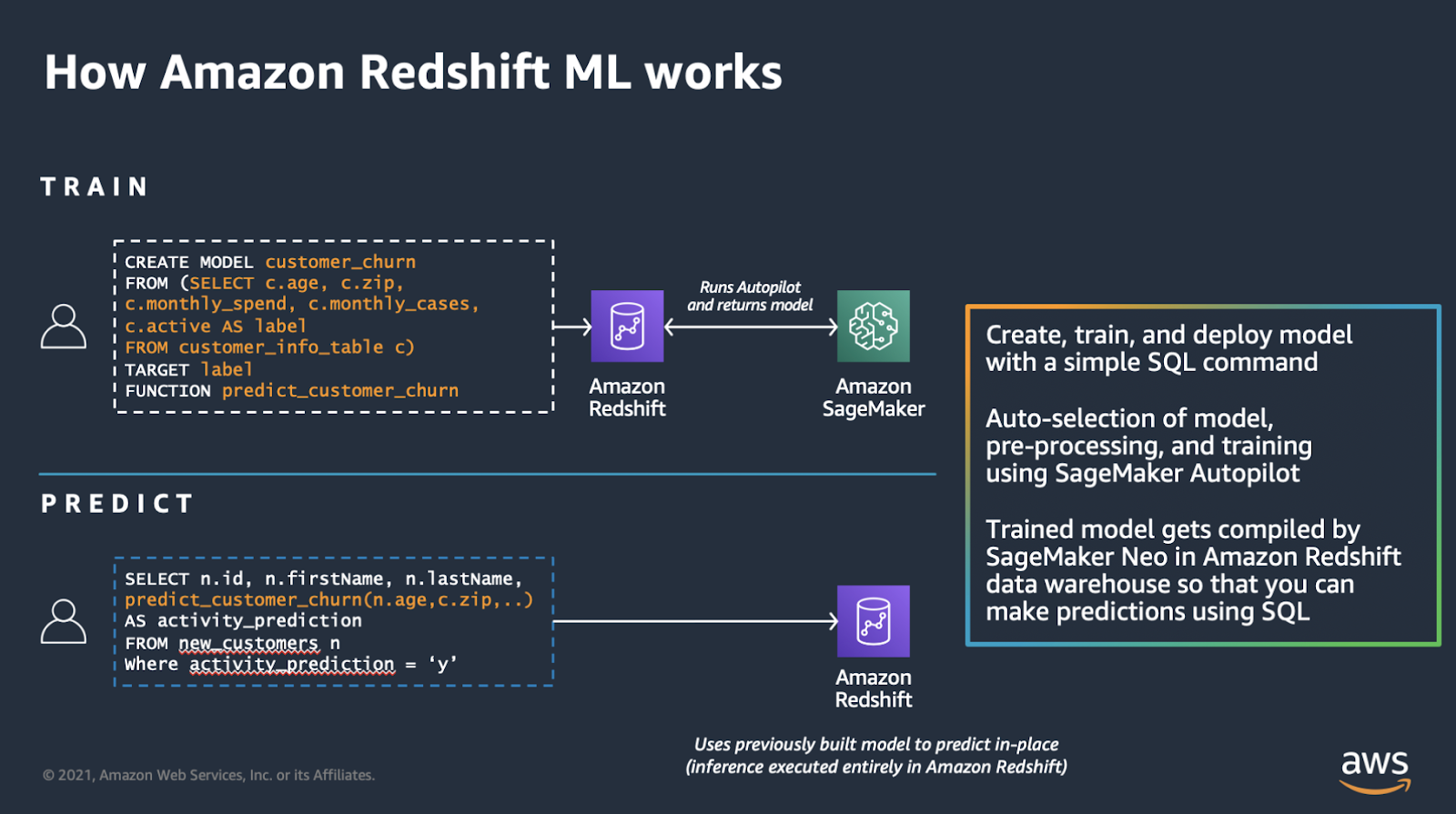
Redshift ML
This service was announced in December 2020 and is an integration between Redshift and SageMaker. Basically it is about doing training, evaluation, and deployment of models from Redshift via SQL statements, using SageMaker as a backend.
AutoML en AWS
There are two initiatives related to automated Machine Learning (AutoML) in AWS: SageMaker Autopilot and AutoGluon from AWS Labs (video).
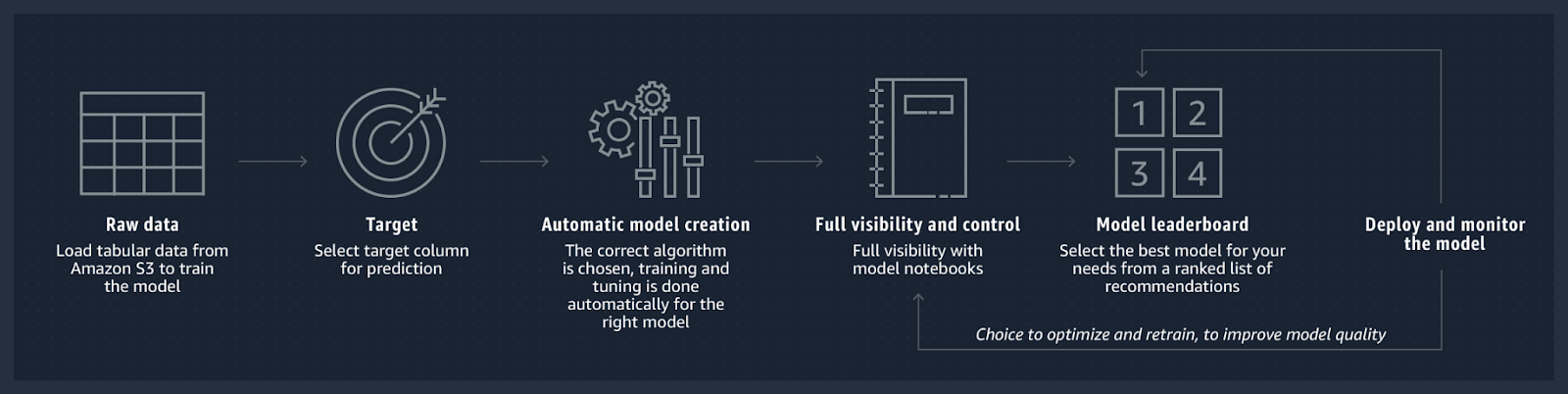
SageMaker Autopilot was announced in December 2019 so it has been on the market for some time now. It refers to AWS’s commercial solution for doing automated Machine Learning (AutoML) and can be used in several ways: on autopilot (hence the name) or with varying degrees of human guidance (without code via Amazon SageMaker Studio, or with code using one of the AWS SDKs).
A remarkable feature is that Autopilot creates three automatic reports on notebooks that describe the plan that has been followed: one related to the data exploration, one related to the definition of the candidate models, and one related to the performance metrics of the final models. Through these reports, the user has access to the complete source code for pre-processing and training of the models, so the user has the freedom to analyse how the models were built and also to make modifications to improve performance. In other words, compared to other commercial AutoML solutions available on the market, Autopilot is a (mostly) white box tool.
Autopilot has predefined strategies for algorithm selection depending on the type of problem, and as for how hyperparameter optimisation is done, Autopilot uses strategies based on random searches and Bayesian optimisation. More information here. In other words, Autopilot follows strategies that fall within the paradigm known as Combined Algorithm Selection and Hyperparameter optimization (“CASH”), which broadly speaking consists of employing strategies to simultaneously find the best type of algorithm and its respective optimal hyperparameters.
⎋ Announcement
⎋ Repository examples
⎋ Video
AutoGluon is an open source, research-oriented, production-ready project powered by AWS Labs that was released towards the end of 2019. In the words of one of its authors, AutoGluon automates Machine Learning and Deep Learning for applications involving images, text and tabular datasets, and simplifies work for both Machine Learning beginners and experts. It supports both CPU and GPU for the backend. Contains several modules:
- Tabular prediction1
- Text prediction
- Image prediction
- Object prediction
- Tuning (of hyperparameters, Python script arguments, and more)
- Neural architecture search
A rather innovative and powerful feature of AutoGluon is that it introduces its text prediction and image prediction capabilities within its tabular prediction module, allowing you to have the option of Multimodal Tables (example and tutorial here). This is useful in use cases where you have simultaneous numerical, categorical, text, and image data, or any combination of these.
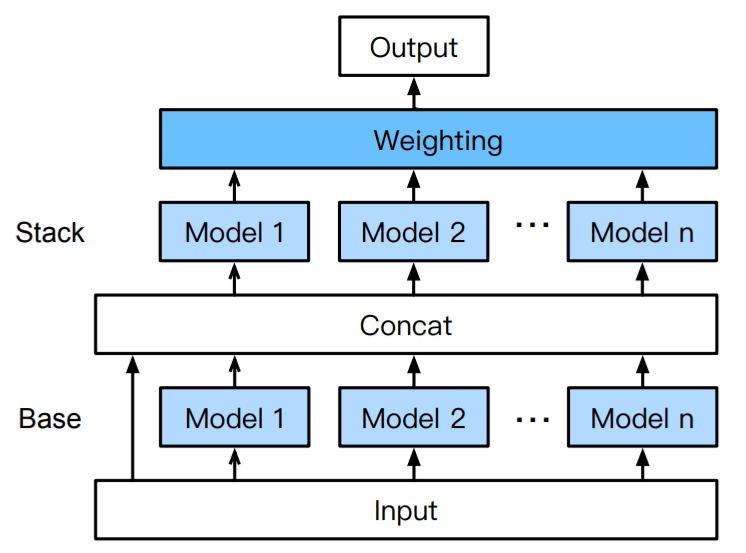
Speaking specifically of the tabular prediction module and its approach to making AutoML, AutoGluon takes an alternative direction to the CASH paradigm (making it different from both SageMaker Autopilot and the other open source projects such as auto-sklearn and H2O AutoML) by following an approach of assembling and stacking models (from different families and from different frameworks) in multiple layers, inspired by practices known to be effective in the Machine Learning community (e.g. in Kaggle competitions). To these ideas, AutoGluon also adds other techniques:
- A strategy to reduce variance in predictions and reduce the risk of overfitting (k-fold ensemble bagging, also called cross-validated committees)2. This process is highly parallelisable and is implemented in AutoGluon using Ray.
- A strategy to optimally combine models in the last layer of the ensemble3.
- A strategy to distil the complex model of the final ensemble into some simpler single model4 that mimics the performance of the complex model and is lighter (and therefore has lower latency in inference time).
⎋ Announcement
⎋ Repository
⎋ Amazon Science post
⎋ Video
In addition, AutoGluon can be used for both training and deployment in SageMaker:
⎋ AutoGluon in SageMaker example
⎋ AutoGluon in AWS Marketplace
Finally, AutoGluon can be integrated with Nvidia Rapids, specifically cuML (a feature announced at Nvidia GTC 2021 as a collaboration between AWS Labs and Nvidia) for further acceleration for GPU training: