
¿Cómo creamos variables basadas en grafos? Un ejercicio práctico con mercury-graph
Los grafos se han convertido en una herramienta fundamental para comprender sistemas complejos en diversos ámbitos. Al representar entidades como nodos y sus relaciones como aristas, los grafos ofrecen un marco versátil para caracterizar, analizar y visualizar interacciones entre objetos de interés. Este enfoque facilita la identificación de patrones, tendencias y anomalías en conjuntos de datos complejos.
La adopción del análisis basado en grafos ha sido cada vez más prominente en BBVA. Este artículo presenta la implementación de código abierto de BBVA para generar automáticamente variables basadas en grafos con el fin de mejorar el rendimiento de los modelos.
Para que las metodologías expuestas en este artículo sean más accesibles y prácticas, hemos puesto nuestro código a disposición del público en mercury-graph. Este recurso permite a los lectores realizar sus propios experimentos y aplicar estos conceptos a sus casos de estudio específicos, fomentando así una comprensión más profunda y garantizando la reproducibilidad de nuestros hallazgos.
Contexto del problema
La eficacia de los modelos de aprendizaje automático depende de la existencia de patrones relevantes en los datos subyacentes. Sin embargo, ciertos patrones, en particular los derivados de las relaciones dentro de una red, pueden ser difíciles de aprender para los modelos cuando no se modelan explícitamente los datos como un grafo. Incorporar variables basadas en grafos al conjunto de características permite a los modelos descubrir patrones complejos que de otro modo podrían pasar desapercibidos, mejorando así su rendimiento global.
Esta idea se resume en la famosa cita del lingüista John R. Firth: “Conocerás una palabra por su compañía”. Al igual que el significado de una palabra puede deducirse de las palabras que la rodean, podemos aprender mucho sobre una persona viendo con quién está conectada. En una red, las personas (o nodos) con las que alguien interactúa suelen reflejar intereses, hábitos o bagajes comunes. Esa es la intuición que subyace a la agregación de información de los vecinos en un grafo: ayuda al modelo a detectar patrones que no son obvios a partir de las características de un individuo por sí solas.
Supongamos que estamos entrenando un modelo supervisado. Antes de la introducción de variables basadas en grafos, nuestro modelo era incapaz de ver más allá de los atributos propios de cada observación. En cambio, una vez que modelamos los datos como un grafo, permitimos que nuestro modelo utilice la información que rodea a cada observación.
En un conjunto de datos tradicional, cada observación tiene su propio conjunto de atributos (ingresos, gastos, etc.). Para diseñar variables basadas en grafos, debemos modelar los datos como un grafo, utilizar su estructura de red para agregar la información de cada nodo y transmitirla a un vecino cercano. De este modo, su vecino recibe su información mientras que usted recibe la de sus vecinos.
Este proceso se conoce formalmente como paso de mensajes porque pasamos los mensajes de nuestros vecinos (características) utilizando las aristas del grafo. Múltiples marcos pueden hacer esto, siendo PyTorch Geometric la implementación más popular. Sin embargo, estas implementaciones se desarrollaron para ejecutarse en un único ordenador, y los grafos del mundo real suelen ser demasiado grandes para caber en una única memoria. Por ello, hemos desarrollado nuestra propia solución distribuida y la hemos publicado en mercury-graph1.
Hands-on: Variables de grafos con mercury-graph
Supongamos que estamos trabajando en un modelo de aprendizaje automático supervisado. Partimos de un conjunto de datos estándar en el que cada observación tiene un conjunto de atributos y un objetivo. Nuestra misión es mejorar el rendimiento del modelo añadiendo características que contengan información sobre los vecinos de un nodo. El principio que subyace a esta idea es que nuestro comportamiento está influido por quienes nos rodean.
Para añadir características de las personas de nuestro entorno, primero tenemos que determinar quién está conectado con quién. En términos de grafos, esto significa definir un conjunto de aristas que modelen las relaciones por pares entre nodos. Utilizaremos las aristas para encontrar a los vecinos de cada uno, obtener sus características, aplicar alguna función de agregación (como una media) y devolver esta información al nodo original.
Además de los atributos a nivel de nodo en el conjunto de datos original, estas variables basadas en el grafo proporcionan un contexto más rico, lo que permite al modelo descubrir patrones ocultos en los datos y, en última instancia, mejorar su rendimiento predictivo.
Para poner las cosas en perspectiva, utilizaremos el conjunto de datos BankSim, un conjunto de datos de código abierto que representa transacciones entre clientes y comerciantes. Cada nodo es un cliente o un comerciante, y ambos están conectados por el importe de una transacción. Sólo los clientes tienen atributos como sexo y edad (los comerciantes no tienen atributos).
Hands-on: Configuración del entorno
Empecemos importando las dependencias necesarias y creando una sesión PySpark.
# Importar
import pandas as pd
import mercury.graph as mg
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
# Configurar sesión PySpark
spark = (
SparkSession.builder.appName("graphs")
.config(
"spark.jars.packages",
"graphframes:graphframes:0.8.3-spark3.5-s_2.12"
)
.getOrCreate()
)
Ahora procedemos a cargar y limpiar los datos.
# Declarar rutas
PATH = (
"https://raw.githubusercontent.com/atavci/fraud-detection-on-banksim-data/refs/"
"heads/master/Data/synthetic-data-from-a-financial-payment-system/"
"bs140513_032310.csv"
)
# Leer Datos
df = pd.read_csv(PATH, quotechar="'")
# Declarar el importe total transaccionado por cliente
df["total"] = df.groupby("customer")["amount"].transform("sum")
# Eliminar las observaciones en las que se desconoce la edad o el género
df = df[df["age"].ne("U") & df["gender"].isin(["M", "F"])]
# Convertir la edad y género en enteros
df = df.assign(
age=df["age"].astype(int),
female=df["gender"].eq("F").astype(int)
)
En su forma original, los datos muestran conexiones entre clientes y comerciantes, pero sólo los clientes tienen atributos. Para que los datos sean más útiles, tenemos que vincular a los clientes entre sí utilizando a los comerciantes como intermediarios. Esto es importante porque nuestro objetivo es pasar mensajes entre nodos conectados, y eso no funcionaría si dejáramos los datos como están (¡porque los comerciantes no tienen atributos!).
# Definimos aristas como subconjuntos de df
edges = (
df[["customer", "merchant"]] # Seleccionar columnas
.drop_duplicates(keep="first") # Ignorar estructura multigráfica
.reset_index(drop=True)
.sample(5000, random_state=42) # Reducción para este ejemplo
)
# Autounión de edges consigo mismo para obtener relaciones cliente-cliente
edges = edges.merge(right=edges, how="inner", on="merchant").drop(columns="merchant")
edges.columns = ["src", "dst"] # Renombrar columnas
edges = edges[edges["src"] != edges["dst"]]
# Eliminar self-loops
Nuestro siguiente paso es declarar un objeto mercury-graph utilizando las tablas que acabamos de cargar.
# Declarar el grafo usando vértices y aristas
g = mg.core.Graph(
data=edges,
nodes=vertices,
keys={"directed": False}
)
Ahora tenemos un objeto mercury-graph que representa la red. Nuestro objetivo es generar nuevas características o variables tomando la información de sus vértices y pasándola a otros nodos a través de la estructura definida por sus aristas.
Paso de mensajes para un único nodo
En primer lugar, utilizamos las aristas del grafo para encontrar los vecinos del nodo de interés. Por ejemplo, si estamos interesados en generar nuevas características para el nodo 0, utilizamos las aristas para encontrar sus vecinos 1, 2 y 3. A continuación, buscamos los vecinos en los vértices del grafo y obtenemos sus atributos individuales.
Por último, agregamos los atributos obtenidos con las funciones de agregación deseadas (mínimo, máximo y promedio en este ejemplo) y añadimos esta nueva información al nodo original.
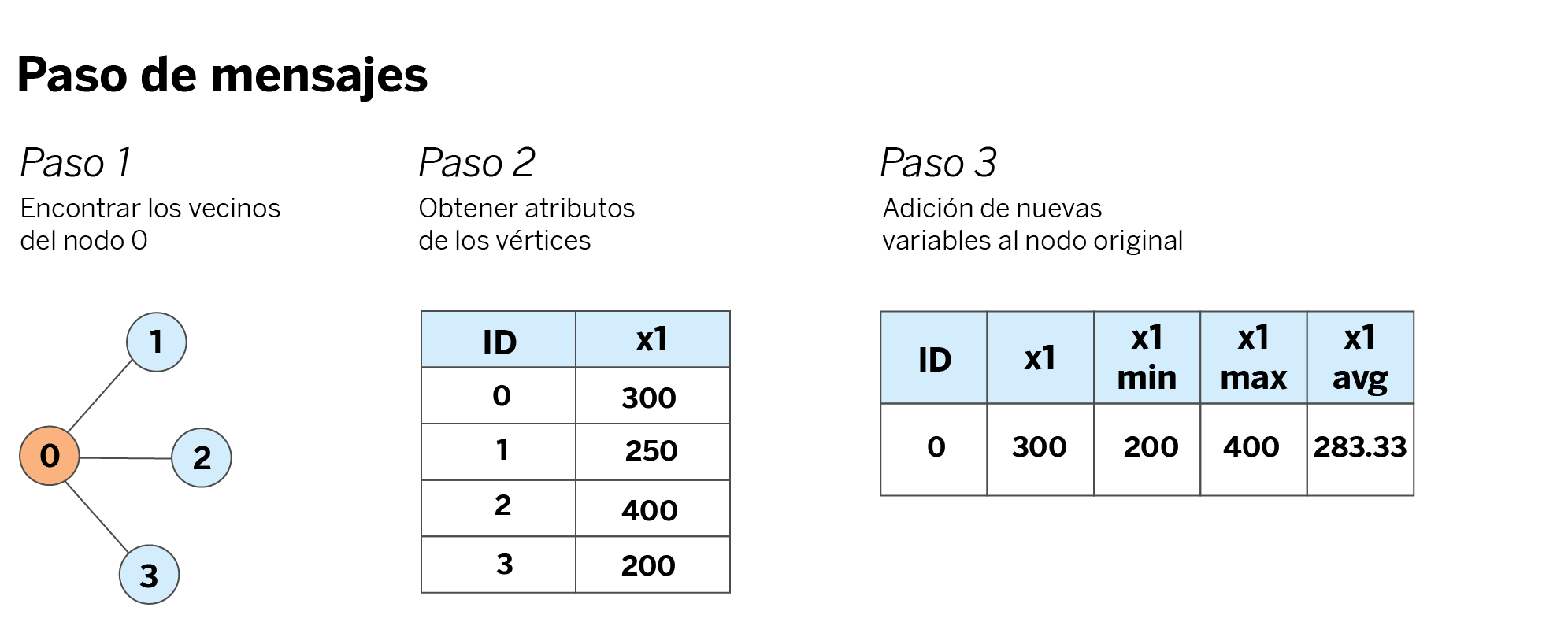
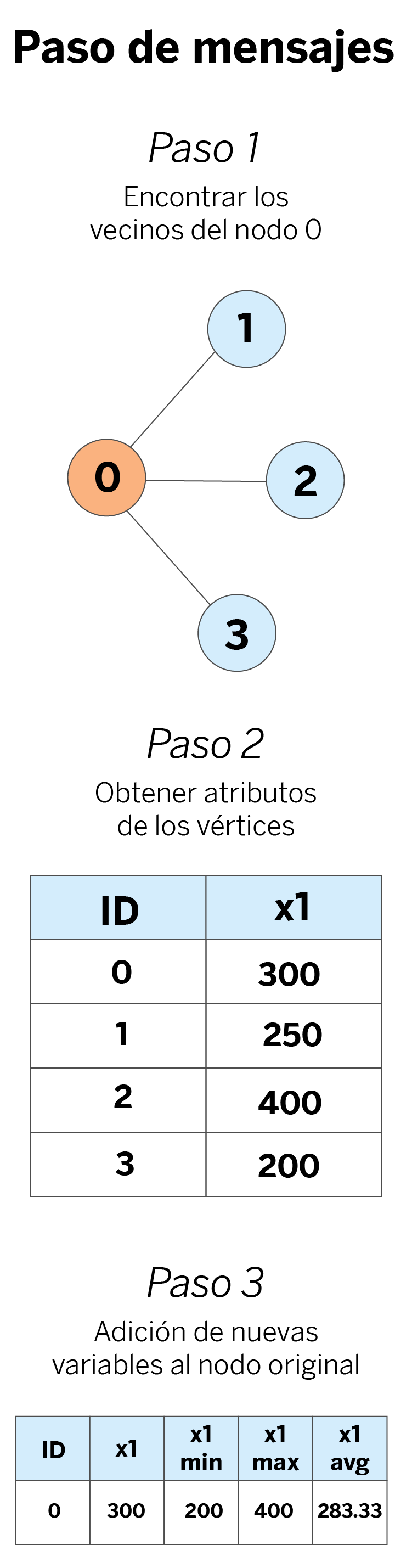
Hands-on: Paso de mensajes con mercury-graph
Hemos desarrollado GraphFeatures, una clase que implementa una versión distribuida de este proceso. Recibe un objeto mercury-graph e ingenia características basadas en grafos para todos los nodos de la red.
# Inicializamos una instancia de GraphFeatures
gf = mg.ml.graph_features.GraphFeatures(
attributes=["age", "female", "total"], # Características a agregar
agg_funcs=["min", "avg", "max"] # Funciones de agregación a aplicar
)
# Fit de la instancia con la info de g
gf.fit(g)
En el fragmento de código anterior, attributes representa los atributos a nivel de nodo que queremos agregar, y agg_funcs representa las funciones de agregación que queremos aplicar a dichos atributos. Al ajustar la instancia, la clase produce un producto cartesiano de ambos argumentos para que cada atributo se pase a todas las funciones de agregación. En otras palabras, cada atributo se pasará a cada función y se diseñarán las siguientes características:
- age_min: Edad mínima de los vecinos de primer orden
- age_avg: Edad media de los vecinos de primer orden
- age_max: Edad máxima de los vecinos de primer orden
- female_min: Valor mínimo de mujeres entre los vecinos de primer orden (un valor de cero implica que el nodo tiene al menos un vecino hombre)
- female_avg: Valor medio de mujeres entre los vecinos de primer orden (interpretado como la proporción de vecinos que son mujeres)
- female_max: Valor máximo de mujeres entre los vecinos de primer orden (un valor cero implica que el nodo no tiene vecinas mujeres).
- total_min: Importe mínimo transaccionado de los vecinos de primer orden
- total_avg: Importe medio transaccionado de los vecinos de primer orden
- total_max: Importe máximo transaccionado de los vecinos de primer orden
Es importante señalar que en este conjunto de datos, la información relativa al género es binaria (1 para mujer y 0 para hombre). En consecuencia, incluir explícitamente tanto el género femenino como su complemento (masculino = 1 – femenino) conduciría a una colinealidad perfecta. Así pues, sólo incorporamos female en nuestro modelo para evitar problemas de redundancia y multicolinealidad.
Ahora podemos acceder a la propiedad node_features_ recién añadida para recuperar las características que hemos creado.
# Ver atributos generados
gf.node_features_.show(5)
El objetivo de estas nuevas variables es incorporarlas al conjunto de características original para mejorar el rendimiento del modelo. Antes de su introducción, el modelo sólo podía aprender de los atributos de los nodos. Al incorporar estas variables, el modelo también puede aprender de patrones ocultos que sólo pueden deducirse de la estructura del grafo.
Escalando a órdenes superiores
Como nota técnica, no es necesario que un nodo esté directamente conectado a otro nodo del grafo para que se consideren vecinos. Para verlo, piensa en el vecino de tu vecino; ¿no son también vecinos tuyos también? Dos nodos conectados a través de un intermediario se conocen como vecinos de segundo orden porque están conectados a través de un camino de dos pasos. Del mismo modo, las conexiones de tercer orden representan nodos conectados a través de caminos de tres pasos y así sucesivamente.
El primer paso consiste en utilizar las aristas del grafo para determinar las relaciones de vecindad, no de un solo nodo, sino de todos los nodos a la vez. En un grafo no dirigido, esto se consigue tomando la tabla de aristas y concatenando una copia de la misma con las columnas de origen y destino intercambiadas (src se convierte en dst y dst en src). El resultado es lo que llamamos tabla de vecinos de primer orden, que cumple una función similar a la de una matriz de adyacencia, pero se almacena de forma más eficiente debido a su forma longitudinal.

Obtener los vecinos de segundo orden es una tarea sencilla. Todo lo que tenemos que hacer es unir la tabla de vecinos de primer orden consigo misma utilizando neigh como clave de unión. Del mismo modo, podemos unir la tabla de vecinos consigo misma una vez más para obtener la tabla de vecinos de tercer orden.
Técnicamente, podemos hacer esto para encontrar todas las conexiones de n órdenes, pero este proceso se vuelve costoso computacionalmente porque implica unir la tabla de bordes (que presumiblemente es muy grande) consigo misma n veces consecutivas. Además, es difícil argumentar que las conexiones de tercer grado (o superiores) afectan realmente a tu comportamiento debido a la distancia entre tú y los vecinos de tus vecinos.
En cualquier caso, nuestra aplicación es capaz de generar características de cualquier orden. Como se mencionó anteriormente, calculamos la tabla de vecinos de n-ésimo orden uniendo recursivamente la tabla de vecinos de primer orden consigo misma. Esta tabla es la concatenación de aristas consigo misma (una tabla muy grande por sí sola); por lo tanto, el plan lógico de spark desbordará su memoria.
El secreto para evitar que el plan lógico explote es comprobar la tabla de vecinos de primer orden así como el resultado de la iteración actual de la autounión. Esto evita que nuestra memoria se desborde y nos permite agregar mensajes de cualquier orden.
Conclusiones
En conclusión, la eficacia de los modelos de aprendizaje automático depende en gran medida de su capacidad para captar patrones relevantes en los datos. La incorporación de variables basadas en grafos a nuestro espacio de variables permite a nuestro modelo aprovechar las complejas relaciones con los clientes, aumentando su poder predictivo. Antes de incluir estas variables basadas en grafos, nuestros modelos se limitaban a evaluar cada observación de forma aislada.
Sin embargo, al modelar los datos como un grafo, permitimos que el modelo incorpore información procedente de la estructura de la red, lo que mejora significativamente su rendimiento. Esto demuestra el valor de la ingeniería de características basada en grafos para revelar patrones ocultos y mejorar el rendimiento del modelo.
Notas
- Nuestro código aún no admite grafos dirigidos. Actualmente sólo admite grafos no dirigidos. ↩︎