
La primera pieza de nuestro asistente de IA: un agente informacional basado en arquitectura RAG
Las arquitecturas basadas en IA agéntica o multi-agente nos permiten construir asistentes conversacionales más completos, al ser capaces de resolver una mayor diversidad de tareas. Una de las capacidades básicas de los asistentes es la de responder a consultas de información que envían los clientes o usuarios.
En nuestro caso de uso, las consultas informativas son aquellas que se pueden responder de igual manera para todos los clientes con información genérica del banco, es decir, sin necesidad de acceder a datos del cliente.
En este artículo nos adentraremos en el funcionamiento del que hemos llamado agente informacional; el primero basado en IA generativa que implementamos en nuestros canales de relación con el cliente. La principal función de este agente es la de aportar una respuesta precisa a consultas genéricas relacionadas con el ámbito bancario y procedimientos o productos de BBVA.


La base de conocimiento: elemento clave para el agente informacional
El desempeño del agente informacional a la hora de generar respuestas útiles y apropiadas no depende sólo de la capacidad del LLM (modelo de lenguaje grande) utilizado, sino también —y en gran medida— de la calidad de la información de la que dispone el agente para generar dichas respuestas. Esta información es lo que en la literatura se conoce como base de conocimiento o KB, por sus siglas en inglés.
La base de conocimiento del agente informacional está formada por un amplio conjunto de respuestas a preguntas frecuentes (FAQs) de BBVA, que incluyen tanto información pública relevante como información de los productos, servicios y procedimientos del banco. Esta documentación es revisada y autorizada por equipos internos del banco, que se encargan de que la información sea precisa y se mantenga actualizada.
Para que el agente pueda utilizar esta información de manera óptima, la pre-procesamos y la indexamos en una base de datos vectorial, lo que permite comparar el mensaje del cliente con el contenido disponible y determinar qué entradas (FAQs) se ajustan mejor a su consulta. Tras una labor de experimentación, hemos decidido utilizar únicamente los títulos de las FAQs, en lugar del texto completo, para realizar la búsqueda. Es decir, codificamos y generamos un embedding para cada título de las preguntas frecuentes, capturando así la información semántica, que luego comparamos con el embedding de la consulta del cliente, recuperando y priorizando el contenido más relevante para construir la respuesta.
¿Cómo funciona el agente informacional? El proceso paso a paso
Cuando un usuario envía una consulta a nuestro asistente, ésta no llega directamente al agente informacional, si no que primero pasa por un proceso de triaje, que ya abordamos en un artículo anterior. Este proceso lo lleva a cabo el agente clasificador, y consiste fundamentalmente en identificar qué es lo que el usuario quiere hacer. Si el agente de triaje determina que la consulta es informativa, la tarea se enrutará al agente informacional.
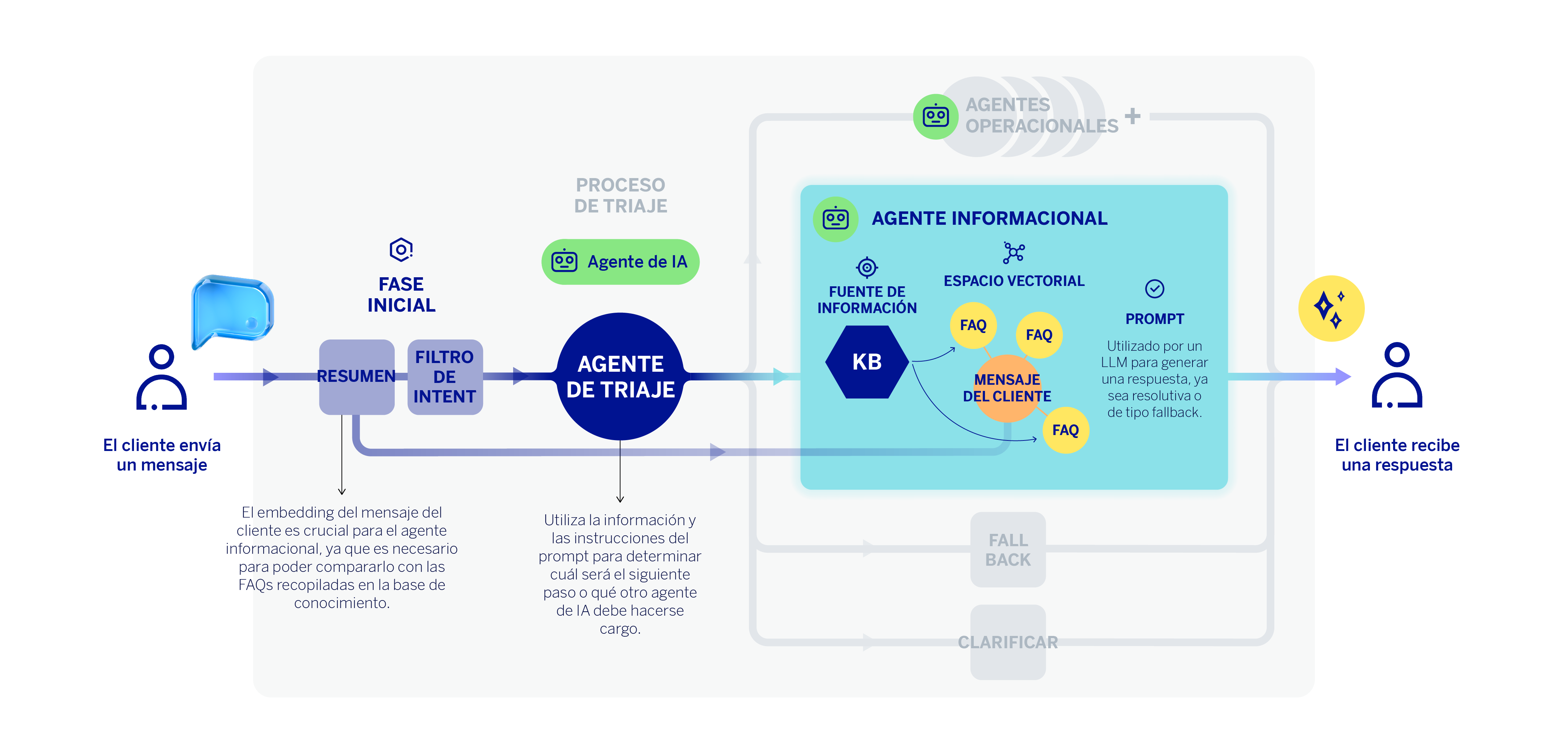
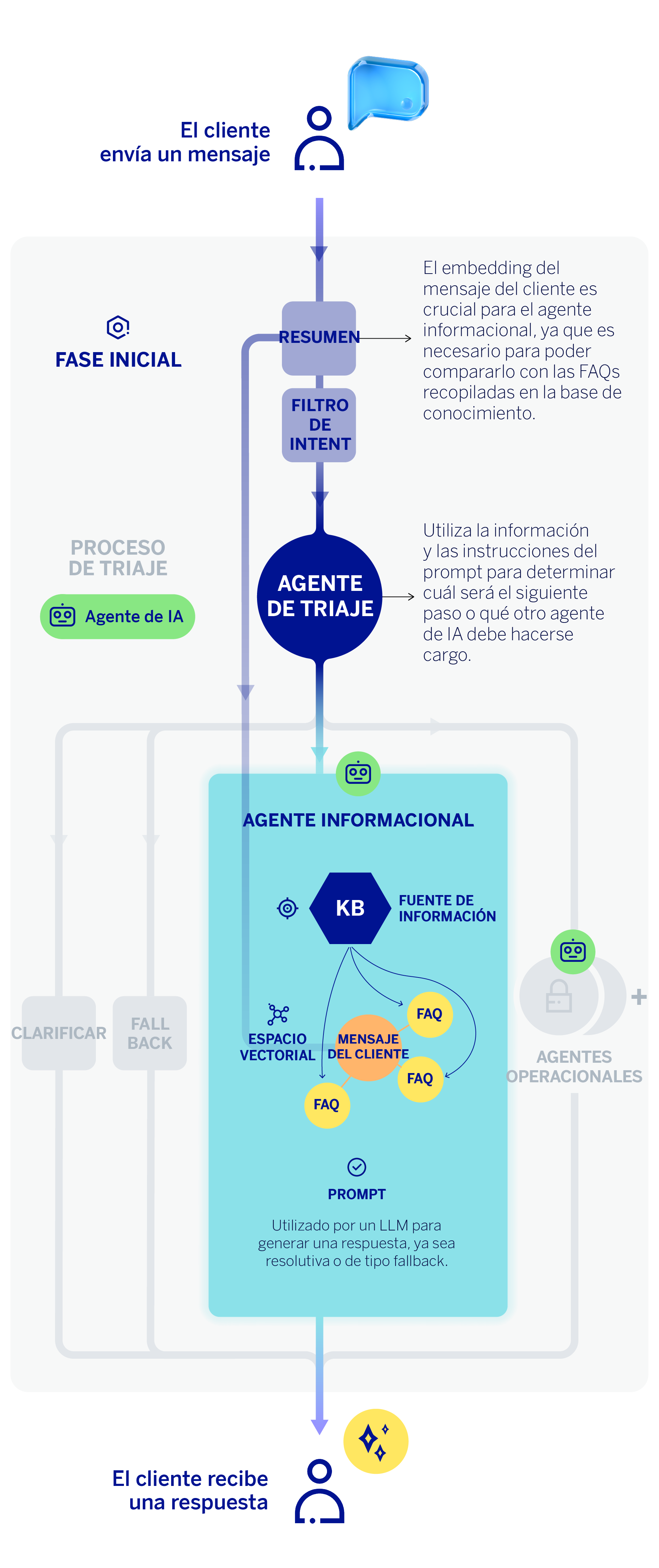
No obstante, aún existe un paso previo. Nos situamos en la fase inicial del flujo de trabajo del asistente, inmediatamente después de recibir el mensaje del cliente. El primer paso del asistente virtual consiste en codificar ese mensaje, generando un embedding que captura su información semántica. Al ser un asistente capaz de entender al cliente en lenguaje natural, en ocasiones la consulta del cliente se materializa en diferentes mensajes —dicho de otro modo, en forma de diálogo—. En ese caso, un LLM resume toda la conversación en un único mensaje que incorpora toda la información contextual de la conversación. Este “resumen” o reformulación de la conversación es lo que se codifica en estos casos.
El embedding del mensaje del cliente es crucial para el agente clasificador o de triaje, pero también para el agente informacional, ya que es necesario para poder compararlo o “emparejarlo” con las preguntas frecuentes que mejor pueden responder a la petición de información del cliente. De esta forma, podemos realizar una comparación semántica del embedding del mensaje del cliente y nuestra base de conocimiento vectorial que contiene la información de las preguntas frecuentes (FAQs). Mediante similitud coseno, se devuelven las “n” FAQs cuyo título se parece más semánticamente a la consulta del cliente.
Una vez realizado este proceso, el LLM del agente informacional recibe un prompt que incluye: el mensaje reformulado o contextualizado del cliente, las FAQs más parecidas semánticamente —obtenidas del proceso anterior—, y una lista de instrucciones diseñadas por el equipo técnico. Cuando el LLM dispone de información suficiente y cumple los requisitos, se genera una respuesta fundamentada en la base de conocimiento que llega directamente al cliente como contestación a su consulta.
Las instrucciones o parámetros que incorpora el prompt persiguen que las respuestas del agente informacional tengan una calidad suficiente, y por tanto deben ser:
- Relevantes, de forma que contesten a la temática de la pregunta.
- Verosímiles, esto es, que la pieza generativa exclusivamente utilice información proveniente de las FAQs y no incluya información adicional proveniente del conocimiento interno del modelo. Además, todas las entidades que proporcione —como pueden ser teléfonos, direcciones de correo, importes o hipervínculos, entre otras— deben ser correctas.
- Útiles, es decir, que sean completas y puedan resolver la petición del cliente.
- Coherentes, que no contengan inconsistencias.
- Completas, evitando dejar información importante del contexto sin incluir en las respuestas.
Generación de respuestas no informativas
Cuando el modelo considera que no está en disposición de generar una respuesta informativa basada en la KB, responde con frases predeterminadas según el motivo.
| Fallback ambiguo | Fallback guardarraíl | Fallback por vacío de conocimiento |
| Cuando la pregunta es poco clara o demasiado esquemática y el modelo no entiende la intencionalidad del cliente, se devuelve un mensaje desambiguador, que tiene por objetivo recabar más información del cliente. | Cuando la consulta no aplica al dominio bancario, no aplica al banco BBVA o el modelo considera que no se debe responder, se devuelve un mensaje indicando al cliente que no puede responder a esa pregunta pero sí a cualquier otra que esté relacionada con el banco. | Cuando la pregunta está bien formulada y el modelo entiende la problemática del cliente pero no encuentra información relacionada en las FAQs del contexto, el agente indica al usuario que carece de información para responder. |
| Fallback ambiguo | Cuando la pregunta es poco clara o demasiado esquemática y el modelo no entiende la intencionalidad del cliente, se devuelve un mensaje desambiguador, que tiene por objetivo recabar más información del cliente. |
| Fallback guardarraíl | Cuando la consulta no aplica al dominio bancario, no aplica al banco BBVA o el modelo considera que no se debe responder, se devuelve un mensaje indicando al cliente que no puede responder a esa pregunta pero sí a cualquier otra que esté relacionada con el banco. |
| Fallback por vacío de conocimiento | Cuando la pregunta está bien formulada y el modelo entiende la problemática del cliente pero no encuentra información relacionada en las FAQs del contexto, el agente indica al usuario que carece de información para responder. |
En este sentido, es importante optimizar la generación de una respuesta informativa o de fallback para no empeorar la experiencia conversacional. Un exceso de fallback puede dar sensación de que el asistente virtual no entiende al cliente. Sin embargo, tenemos que asegurarnos de que las respuestas satisfacen los estándares de calidad. Precisamente, uno de los avances para intentar mantener la conversacionalidad es distinguir frases de fallback según su motivo.
Conclusiones: hacia un asistente informacional útil y preciso
Una de las principales constataciones que se derivan de la implementación de este asistente informacional es la importancia de mantener una base de conocimiento de preguntas frecuentes que sea rigurosa y se actualice periódicamente, ya que, en definitiva, es ésta la información en la que se apoya el asistente para generar respuestas a los clientes. Además, gracias al análisis de las respuestas categorizadas como “fallback por vacío de conocimiento”, hemos descubierto cuestiones relevantes que no habíamos contemplado. En consecuencia, hemos propuesto crear nueva información útil que complemente la que ya teníamos.
La incorporación de RAG en los agentes informacionales ha mejorado mucho la calidad de las respuestas de asistentes virtuales como Blue, el chatbot de BBVA. Al poder consultar una base de conocimiento (KB), estos agentes obtienen información actualizada sobre procedimientos, condiciones o productos de BBVA, sin confundir con información de otras compañías u ofrecer datos incorrectos. Esta capacidad de responder a consultas con información actualizada y en lenguaje natural, unido a la posibilidad de ejecutar operativas bancarias gracias a la orquestación de diferentes agentes, es lo que confiere un poder transformador a los asistentes basados en IA agéntica.
Referencias
- Reginald Martyr, RAG Architecture Explained: A Comprehensive Guide [2025]. ↩︎