
¿Prompting o fine-tuning? Medir bien sigue siendo la decisión más inteligente cuando adaptamos LLMs
En BBVA llevamos unos años experimentando con grandes modelos de lenguaje (LLMs por sus siglas en inglés) y, en general, con la IA generativa, una tecnología que se ha convertido en la base de nuevos servicios como Blue, el asistente virtual de BBVA.
Un gran modelo de lenguaje (LLM) es un tipo de inteligencia artificial entrenado con una cantidad masiva de texto para entender y generar texto en lenguaje humano. Dada la inmensa inversión en datos y capacidad computacional que implica entrenar un LLM desde cero, en BBVA utilizamos modelos avanzados disponibles en el mercado, como la familia de modelos GPT de OpenAI, y los adaptamos a nuestras necesidades específicas. En este artículo contamos algunos casos de uso y aplicaciones de los LLMs.
Para adaptar un LLM a un caso de uso o necesidad de negocio generalmente podemos seguir dos caminos. El primero es la ingeniería de prompts, que consiste en darle instrucciones muy claras y detalladas al modelo. Es como si le diéramos a un asistente muy capaz y polivalente una lista de tareas perfectamente descrita, con el contexto, las restricciones y el formato de respuesta deseado para que la ejecute sin fallos. No se modifica la habilidad general del asistente, sino que se perfecciona la calidad de la petición para obtener un resultado excelente.
La segunda estrategia que podemos seguir es el fine-tuning. Este proceso va un paso más allá: en lugar de solo dar instrucciones, modificamos ligeramente el comportamiento base del modelo entrenándolo con cientos o miles de ejemplos específicos de nuestra tarea. Siguiendo la analogía, sería como si el asistente recibiera una formación intensiva y especializada, de forma que se convierta en un experto en un área concreta, como la interpretación de informes financieros, por ejemplo. Su conocimiento fundamental no cambia, pero adquiere un nuevo matiz, una especialización.
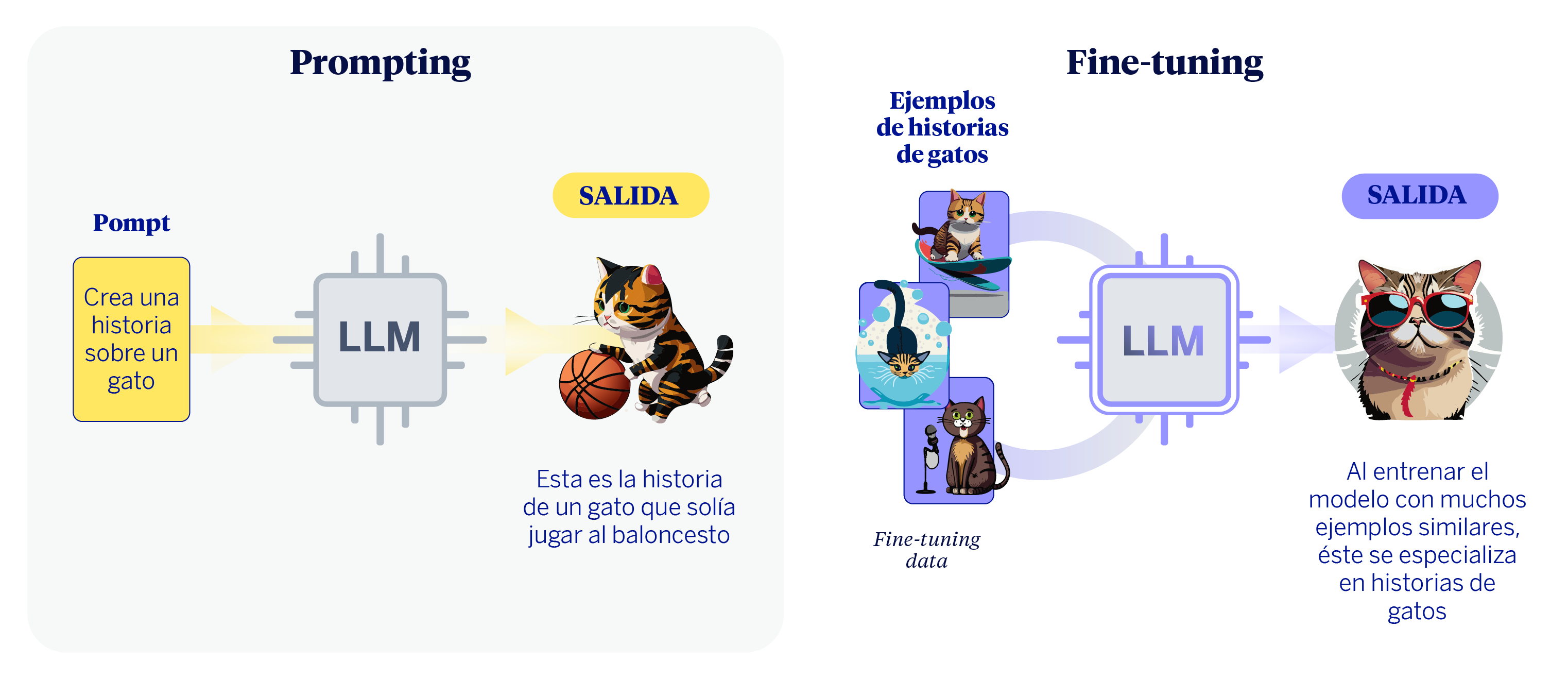
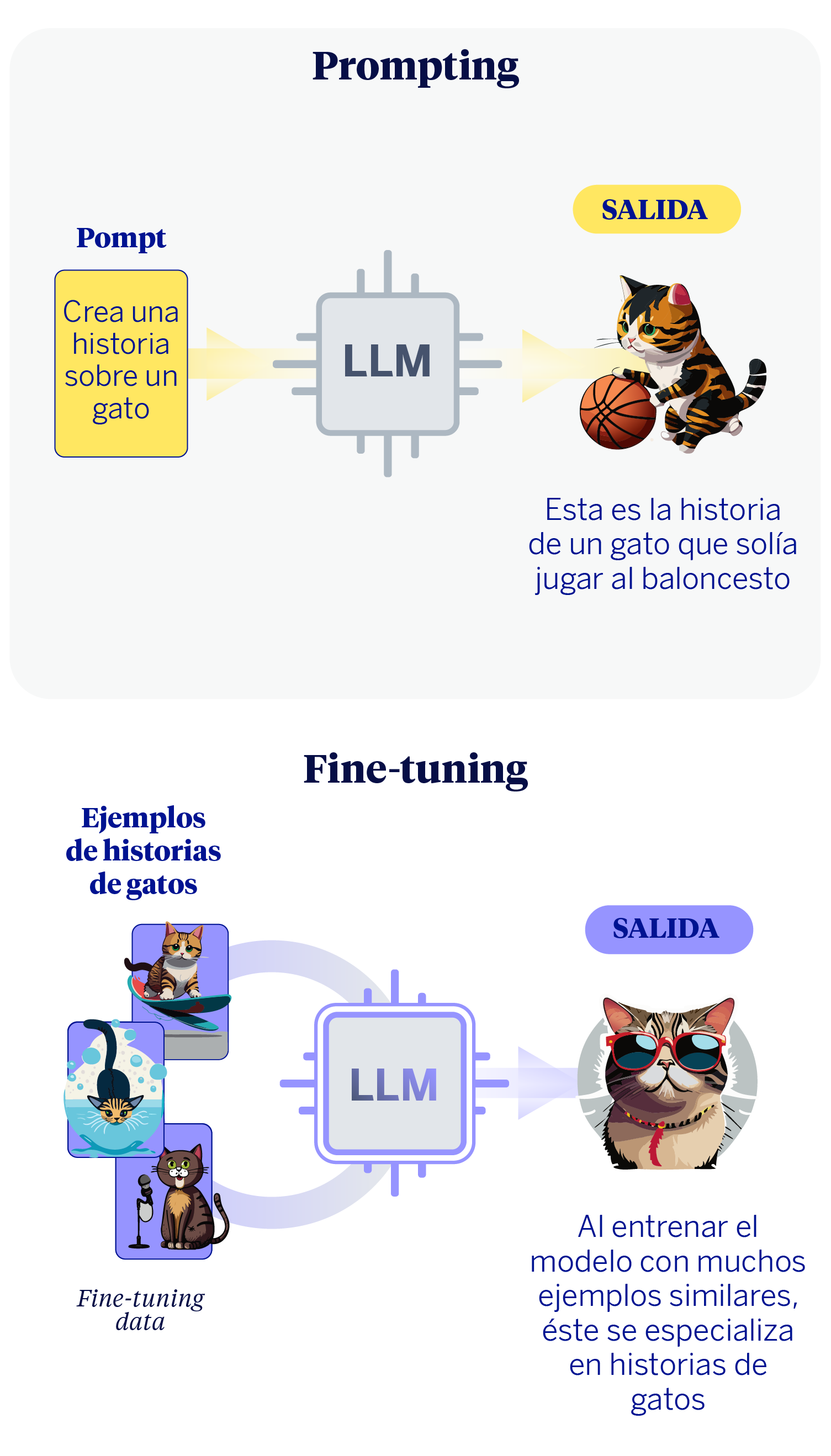
Ahora bien, antes de elegir uno de los caminos, es crucial establecer ciclos de validación que nos permitan medir los resultados desde el principio. La información que obtengamos de estos procesos de evaluación nos indicarán en gran medida cuál es el mejor camino a seguir a continuación. En nuestra experiencia trabajando con LLMs en el Gen AI Lab de BBVA AI Factory, hemos aprendido que la pregunta más importante no es qué camino tomar, sino cómo vamos a medir si hemos llegado a nuestro destino. Este artículo presenta una metodología para adaptar LLMs a casos de uso específicos, poniendo en el centro la medición periódica de resultados.
El papel clave de la evaluación de resultados para el uso de LLMs
Los modelos de lenguaje son complejos y, en ocasiones, sus respuestas pueden ser impredecibles. Por eso, la evaluación es el pilar de cualquier proyecto serio. Un buen sistema de evaluación nos permite medir el rendimiento de forma objetiva, guiar las mejoras y asegurar que la solución final es fiable y segura. Nuestro enfoque se basa en un sistema de evaluación con varios componentes que funcionan en conjunto:
- Métricas automáticas y revisión humana: Por un lado, usamos métricas automáticas que nos dan una idea rápida del rendimiento, como la precisión o el porcentaje de respuestas correctas. Son rápidas y escalables, pero a menudo se quedan en la superficie. Por otro lado, la revisión humana nos permite analizar aspectos y matices que la evaluación automática no está capturando correctamente, al tiempo que controlamos su propio funcionamiento.
- Seguimiento continuo en producción: El rendimiento de un modelo puede cambiar cuando se enfrenta a situaciones y usuarios del mundo real. Por ello, es fundamental hacer un seguimiento continuo una vez que la herramienta está en funcionamiento. Esto nos permite detectar rápidamente si el modelo empieza a fallar con nuevas preguntas que no habíamos previsto o si los usuarios interactúan de una forma inesperada, para así poder reaccionar a tiempo.
- Validación iterativa desde el principio: La evaluación no es el último paso, sino un proceso que ocurre al mismo tiempo que el desarrollo. Someter a los modelos a ciclos de validación nos ha permitido identificar la raíz de muchos problemas de forma temprana, lo que ahorra una enorme cantidad de tiempo y recursos. Nos ha enseñado que muchas deficiencias que parecían necesitar un costoso fine-tuning se resolvían con instrucciones más precisas, siempre guiadas por los datos de la evaluación.
Esta capacidad de evaluación ha sido más determinante que cualquier técnica puntual. Muchos experimentos que parecían requerir un proceso de fine-tuning se resolvieron simplemente con instrucciones o prompts más precisos y midiendo bien los resultados.
Una metodología para adaptar LLMs
Para organizar nuestro trabajo, hemos consolidado un proceso iterativo que basa las decisiones técnicas en los datos que obtenemos de la evaluación. Es un ciclo de mejora continua.
Paso 1: Definir el objetivo y las métricas de éxito
Todo proyecto comienza con una definición clara del problema a resolver y de los indicadores que nos dirán si hemos tenido éxito. Es crucial que estas métricas técnicas estén alineadas con los objetivos de negocio. Por ejemplo, traducimos metas como “mejorar la satisfacción del cliente” en métricas que podamos medir, como el porcentaje de consultas resueltas en el primer contacto o la puntuación de satisfacción de los usuarios.
Paso 2: Iteración ágil con prompting
Comenzamos el desarrollo usando prompting por su agilidad y bajo coste. Esto nos permite tener una primera versión funcional rápidamente y empezar a medir. Usamos distintas técnicas según el problema:
- Chain-of-Thought (CoT): Para problemas que requieren razonamiento, le pedimos al modelo que piense paso a paso, desglosando su lógica antes de dar la respuesta final.
- Few-Shot Prompting: Le damos al modelo ejemplos concretos de lo que queremos que haga, lo que le ayuda a entender el patrón y el formato esperado.
- Uso de Herramientas y Agentes (Tool-Use): Permitimos que el modelo interactúe con sistemas externos (como bases de datos o calculadoras) para que pueda consultar información actualizada o realizar acciones, superando las limitaciones de su conocimiento estático.
- Retrieval-Augmented Generation (RAG): Conectamos el modelo a una fuente de información externa y fiable (un corpus de preguntas frecuentes, por ejemplo). Así, sus respuestas se basan en datos específicos y controlados por nosotros, lo que reduce enormemente el riesgo de que invente información.
Paso 3: Evaluación continua
Cada nueva versión de un prompt se somete a nuestro sistema de evaluación. De esta forma, este paso se convierte en un diálogo constante con el modelo: proponemos un prompt, analizamos los resultados para entender los fallos y las áreas de mejora, y respondemos con un nuevo prompt. Este ciclo es lo que nos permite refinar la solución de forma progresiva.
Paso 4: Transición controlada a procesos de fine-tuning
Solo planteamos hacer fine-tuning cuando el prompting llega a un punto en el que deja de mejorar y las métricas nos demuestran que aún no hemos alcanzado los objetivos. Esta decisión siempre se basa en datos y justifica la mayor inversión de tiempo y recursos que requiere el fine-tuning. No es un fracaso del prompting, sino un paso estratégico para alcanzar un nivel de rendimiento superior que, en algunos casos, solo la especialización puede dar. Cuando lo hacemos, damos prioridad a técnicas eficientes como PEFT (Parameter-Efficient Fine-Tuning) o LoRA (Low-Rank Adaptation), que ajusta solo una pequeña parte del modelo, reduciendo el coste y los riesgos.
Casos de uso en BBVA: lecciones aprendidas
Nuestra metodología se ha puesto a prueba en múltiples proyectos internos, dejándonos lecciones muy claras:
| ✅ Caso de éxito con prompting bien evaluado | Desarrollando asistentes internos basados en LLMs para tareas administrativas y de atención al cliente, un enfoque riguroso de prompting y evaluación nos permitió resolver más del 90% de los casos de uso sin necesidad de fine-tuning. La clave fue iterar sobre los prompts y evaluar de forma rigurosa: cobertura de casos, coherencia de respuestas y satisfacción de los usuarios finales de la herramienta (empleados de BBVA). |
| ⚠️ Caso de mejora mínima con fine-tuning | En un proyecto con respuestas muy ambiguas, intentamos mejorar el rendimiento con fine-tuning. El coste de conseguir datos bien etiquetados fue alto, y la mejora final fue muy pequeña en comparación con la solución que ya teníamos usando prompting. Además, el sistema resultante era menos interpretable y más difícil de mantener. Esto nos demostró que, sin una necesidad clara y datos de calidad, el fine-tuning puede ser una gran inversión con pocos beneficios. Los recursos invertidos podrían haberse destinado a otros proyectos de mayor impacto. |
| ❌ Casos con fallo en los datos de entrada | En varios proyectos con RAG inicialmente atribuimos el rendimiento al modelo. Sin embargo, un análisis detallado de los fallos nos indicó que el problema real era la calidad de la fuente de información que consultaba: datos anticuados, mal organizados o irrelevantes. Al mejorar la fuente de información y las instrucciones, el rendimiento mejoró notablemente sin tocar el modelo. De nuevo, evaluar bien nos permitió evitar una solución más costosa. |
Conclusión: la clave para entender es medir
Después de trabajar en la adaptación e implementación de LLMs, llegamos a la conclusión de que el debate sobre si usar prompting o fine-tuning es secundario. La experiencia práctica nos demuestra que la pregunta fundamental es otra: ¿qué problema estamos resolviendo y cómo vamos a medir si lo hacemos bien?
La ingeniería de prompts es una forma rápida y eficiente de obtener resultados y aprender del modelo. El fine-tuning es una herramienta potente para especializar un modelo, pero su uso debe estar justificado por una necesidad de negocio y respaldado por datos. En última instancia, el éxito de un proyecto de IA no se mide por la complejidad de la técnica utilizada, sino por la rigurosidad con la que se evalúa su rendimiento y su impacto real.
Como nos gusta decir en el equipo: “No se trata solo de cómo le hablas al modelo, sino de cómo evalúas lo que te responde”. Esa evaluación constante es la que garantiza que construimos soluciones de IA robustas, fiables y verdaderamente útiles.