
Un único modelo para categorizar texto y sugerir etiquetas
Siguiendo con el proyecto que inicié durante mi estancia en prácticas en BBVA Data & Analytics en 2017, que se describe en este otro artículo, es el momento de poner el foco en explicar el trabajo realizado como continuación a esta investigación durante mi segundo periodo de prácticas en la compañía. El problema que intentamos resolver, y que mostramos en este artículo, se basa en la clasificación conjunta y la predicción de etiquetas para textos cortos.
Predicción y clasificación de etiquetas
Este problema lo podemos encontrar en aplicaciones prácticas como la categorización de descripciones de productos para e-commerce, la clasificación de nombres de comercios en bases de datos empresariales o la organización de títulos o preguntas en foros de discusión en línea. En el ámbito de la banca, este problema puede aparecer en la categorización de transacciones. Por ejemplo, cuando en las aplicaciones móviles de gestión de finanzas personales se asigna una categoría a una transacción, basándose en las palabras que aparecen en el concepto (clasificaríamos “Joan’s Coffee Shop” en la categoría “Bares y Restaurantes”), pero es posible que se deseasen inferir otras etiquetas descriptivas (como “cafetería”).
Tanto la predicción de categorías basada en un texto corto, como la de etiquetas, pueden ser abordadas con técnicas de aprendizaje profundo (Deep Learning). Sin embargo, ambos problemas no son totalmente independientes, ya que es deseable que las etiquetas y las categorías sean consistentes. Por lo tanto, el desafío aquí es cómo diseñar un modelo capaz de aprender conjuntamente las etiquetas y categorías, dadas algunas frases de entrada (y posiblemente algunas etiquetas conocidas).
Además, hay situaciones en las que se requiere explicabilidad y, por lo tanto, necesitamos comprender por qué se asignó un texto corto a una clase determinada. En el caso de la clasificación de textos, un método es señalar las palabras que contienen la mayor parte de la información para la clasificación, lo que se logra típicamente a través de los llamados modelos de atención (attention models). Una vez más, el reto sería cómo añadir explicabilidad a la predicción conjunta de categorías y etiquetas.
El objetivo final del trabajo fue explorar la arquitectura de una red neuronal que toma como entrada una frase y opcionalmente un conjunto de etiquetas conocidas, y que fuera capaz de cumplir las siguientes tres propiedades -cosa que ningún método de clasificación de oraciones cortas conocido cumplía-:
- clasificar la frase, teniendo en cuenta las palabras y etiquetas observadas
- predecir las etiquetas que faltan, basándonos en las palabras observadas y otras etiquetas
- puntuar las palabras y etiquetas seleccionadas por su importancia. Por ejemplo, cuantificando o explicando cuánto contribuye cada palabra o etiqueta observada a la decisión. Este modelo, presentado gráficamente bajo estas líneas, utiliza un primer “attention model” para construir una incrustación o embedding de una cadena de texto en términos de palabras y etiquetas de entrada.
Este “embedding” se utiliza para puntuar conceptos a partir de un vocabulario de conceptos fijo. Finalmente, los “embeddings” de los conceptos puntuados se agrupan en una representación final de la frase que puede utilizarse para la clasificación. El scoring de conceptos puede ser interpretado como un segundo mecanismo de atención, donde la frase de entrada es “reconstruida” en términos de un vocabulario de conceptos conocidos. A continuación se muestra una ilustración de esta red:
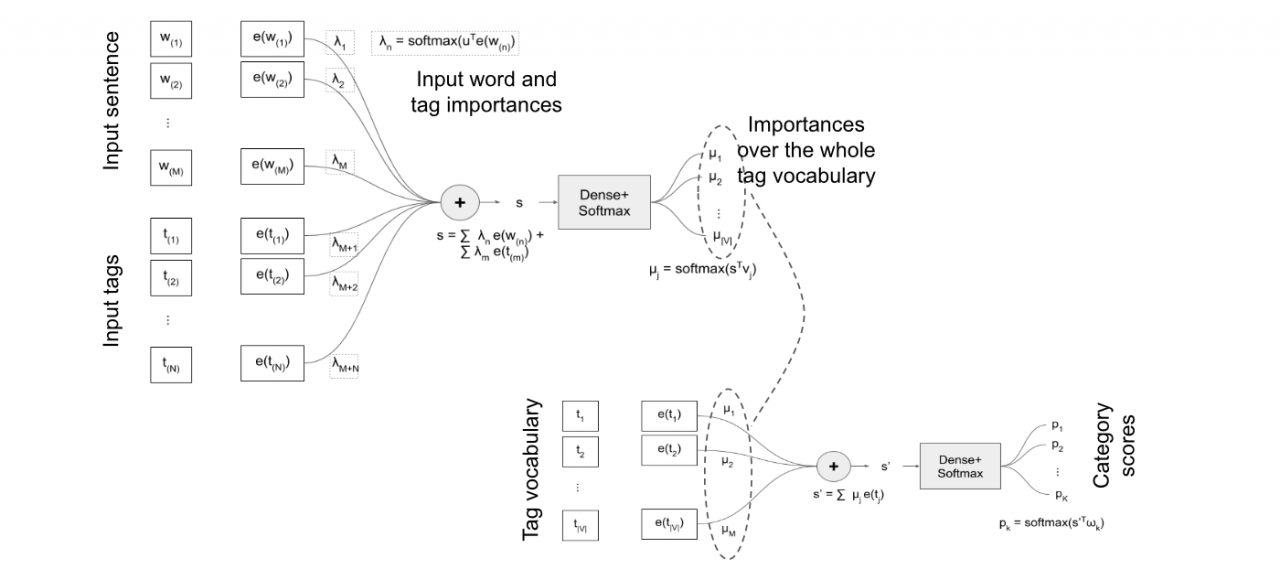
Por lo tanto, con este modelo obtenemos la categoría de la cadena de texto y cierto grado de interpretabilidad en términos de qué palabras son importantes, así como las etiquetas inducidas. Hemos aplicado este modelo a un conjunto de datos de clasificación de preguntas de “Stack Overflow” y a la tarea industrial de clasificación de nombres de comercios en datos transaccionales. El informe técnico de la estancia en prácticas se puede encontrar aquí.