
Los 10 mejores artículos científicos de NeurIPS 2022
Hace dos semanas tuvimos la oportunidad de asistir a NeurIPS 2022, una conferencia de referencia a nivel mundial en Inteligencia Artificial y Aprendizaje Automático, que se celebró en Nueva Orleans, Estados Unidos. Muchas de las técnicas y herramientas que hoy damos por sentadas, tanto en la industria como en el mundo académico, se presentaron en algunas ediciones de esa conferencia. Por ejemplo, el famoso e influyente artículo AlexNet de 2012 (que presentó la primera red neuronal convolucional entrenada en la base de datos ImageNet) fue seleccionado por unanimidad para el premio NeurIPS 2022 Test of Time.
Aunque muchos de los trabajos presentados en NeurIPS son principalmente teóricos y muestran su utilidad y potencial a largo plazo, también es posible encontrar trabajos muy aplicados y que proporcionan implementaciones listas para usar. Como profesionales del Machine Learning (aprendizaje automático) en la industria, prestamos especial atención a este tipo de trabajos. En este artículo destacamos una lista de los 10 mejores trabajos con código que descubrimos en NeurIPS 2022, y que nos entusiasma probar y compartir.
Gradient Descent: El optimizador definitivo
Este trabajo fue galardonado con el premio Outstanding Paper. En este trabajo, los autores presentan una técnica novedosa que permite a los optimizadores de descenso de gradiente, como SGD y Adam, ajustar sus hiperparámetros automáticamente. El método no requiere diferenciación manual y puede apilarse recursivamente a muchos niveles.

|
|---|
.
MABSplit: Forest Training más rápido mediante Multi-Armed Bandits
Los autores presentan un algoritmo que acelera el entrenamiento de random forests y otros métodos de aprendizaje basados en árboles. En el núcleo del algoritmo hay una subrutina novedosa de división de nodos que se utiliza para encontrar eficientemente puntos de división al construir árboles de decisión. El algoritmo toma prestadas técnicas de la literatura sobre multi-armed bandit para determinar cómo distribuir las muestras y la potencia computacional entre los puntos de división candidatos.
Más allá de L1: Mejores y más rápidos modelos Sparse con skglm
Los autores presentan un nuevo algoritmo rápido para estimar modelos lineales generalizados (GLM) dispersos con penalizaciones separables convexas o no convexas. Los autores lanzan un paquete flexible, compatible con scikit-learn, que maneja fácilmente penalizaciones personalizadas.
SketchBoost: Gradient Boosted Decision Tree rápido para problemas con múltiples salidas
Los autores presentan nuevos métodos para acelerar el proceso de entrenamiento de GBDT en el escenario de múltiples salidas, cuando la salida es altamente multidimensional. Estos métodos se implementan en SketchBoost, que a su vez se integra en la implementación GPU de GBDT basada en Python y fácilmente personalizable denominada Py-Boost.

|
.
Benchopt: Benchmarks de optimización reproducibles, eficientes y colaborativos
Los autores presentan Benchopt, un framework para automatizar, reproducir y publicar benchmarks de optimización en aprendizaje automático a través de lenguajes de programación y arquitecturas de hardware. Está escrito en Python, pero es compatible con muchos lenguajes de programación.
AutoWS-Bench-101: Benchmarking de Weak Supervision automático con 100 etiquetas
Weak supervision (WS) es un potente método que permite crear conjuntos de datos etiquetados para entrenar modelos supervisados cuando los datos etiquetados son escasos o inexistentes. Sustituye el etiquetado manual de datos por la agregación de múltiples estimaciones de etiquetas ruidosas pero baratas (noisy-but-cheap). Los autores presentan AutoWS-Bench-101, un framework para evaluar técnicas automatizadas de WS en configuraciones difíciles de WS.
Pythae: Unificando autocodificadores generativos en Python: un caso de uso de evaluación comparativa
Los autores presentan Pythae, una biblioteca Python versátil que proporciona tanto una implementación unificada como un framework dedicado que permite el uso directo, reproducible y fiable de modelos autocodificadores generativos (autoencoder models). En particular, ofrece la posibilidad de realizar experimentos de referencia y comparaciones entrenando los modelos con la misma arquitectura de red neuronal de autocodificación (autoencoding neural network).
SnAKe: Optimización Bayesiana con Pathwise Exploration
Inspirándose en aplicaciones del ámbito de la química, los autores proponen un método para optimizar funciones de caja negra (black-box functions) en un entorno novedoso en el que el gasto de evaluar la función puede aumentar significativamente al realizar grandes cambios de entrada entre iteraciones, y bajo un entorno asíncrono (lo que significa que el algoritmo tiene que decidir sobre nuevas consultas antes de que termine de evaluar los experimentos anteriores).
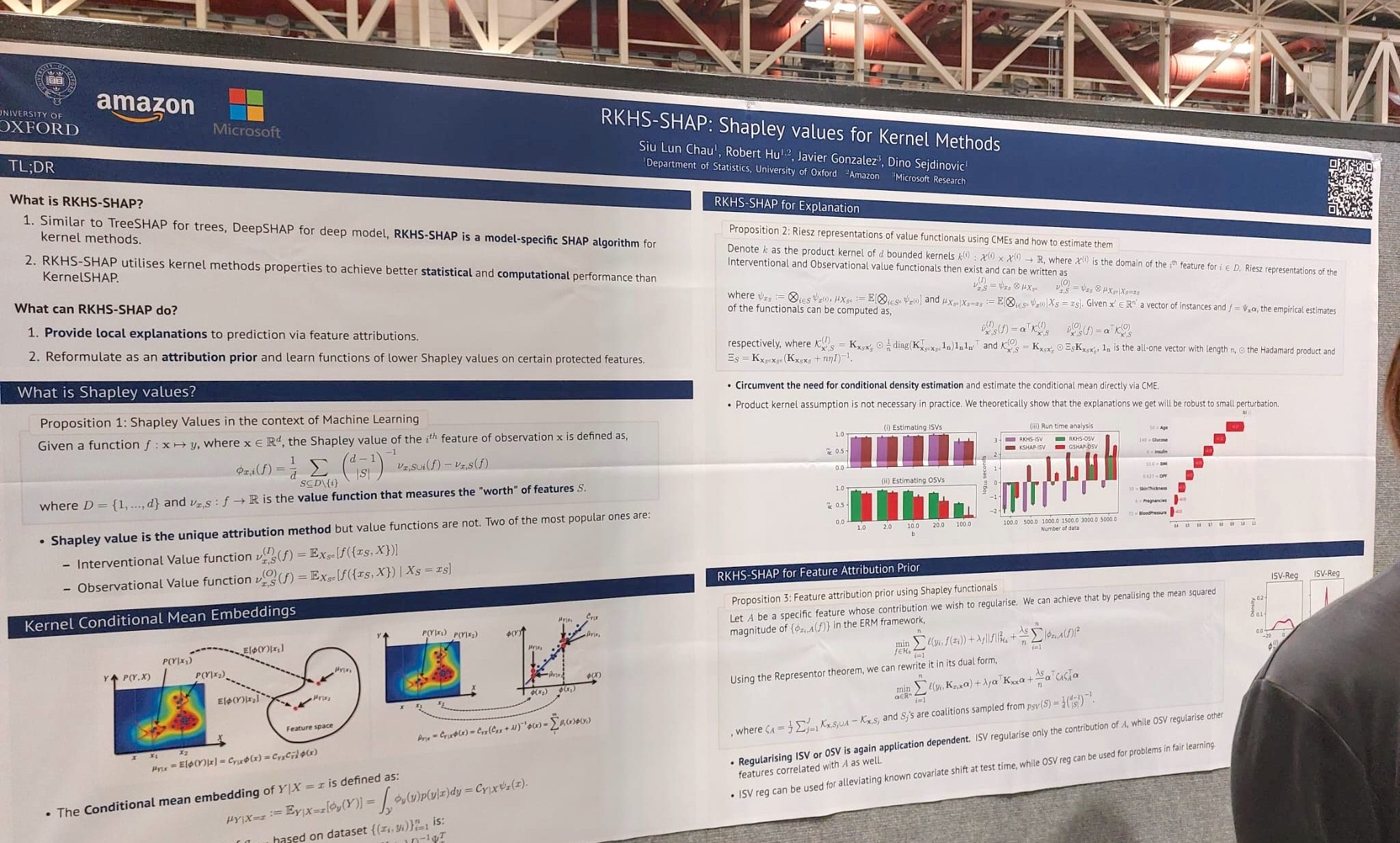
RKHS-SHAP: Valores Shapley para métodos Kernel
Los valores de Shapley se han aplicado previamente a diferentes tareas de interpretación de modelos de aprendizaje automático, como modelos lineales, conjuntos de árboles y redes profundas, pero faltaba una extensión para los métodos kernel. En este trabajo, los autores proponen un método novedoso para calcular valores de Shapley para modelos basados en kernel e incluyen tanto un análisis teórico como una amplia evaluación experimental.
|
|---|
.
Explicar las preferencias con valores de Shapley
En este trabajo, los autores proponen Pref-SHAP, un framework de explicación de modelos basado en el valor de Shapley para datos de comparación por pares. Para demostrar la utilidad del método, lo aplican a diversos conjuntos de datos sintéticos y del mundo real (¡incluidos datos de batallas Pokémon!) y demuestran que se pueden obtener explicaciones más ricas y perspicaces frente al baseline.
BONUS!
En su discurso de apertura, Geoff Hinton ofreció sus reflexiones sobre el futuro del aprendizaje automático y habló de sus últimas investigaciones sobre el algoritmo “Forward-Forward” (FF), una alternativa al algoritmo de Backpropagation con motivaciones biológicas. Las ideas principales de la ponencia se resumen ingeniosamente en este hilo de twitter. Será interesante ver la influencia de este nuevo enfoque en la comunidad del ML en los próximos años.
Los 10 mejores papers de NeurIPS 2022
1. Gradient Descent: El optimizador definitivo
Este trabajo fue galardonado con el premio Outstanding Paper. En este trabajo, los autores presentan una técnica novedosa que permite a los optimizadores de descenso de gradiente, como SGD y Adam, ajustar sus hiperparámetros automáticamente. El método no requiere diferenciación manual y puede apilarse recursivamente a muchos niveles.
⎋ Poster
⎋ Paper
⎋ Repositorio
⎋ Nota de prensa
2. MABSplit: Forest Training más rápido mediante Multi-Armed Bandits
Los autores presentan un algoritmo que acelera el entrenamiento de random forests y otros métodos de aprendizaje basados en árboles. En el núcleo del algoritmo hay una subrutina novedosa de división de nodos que se utiliza para encontrar eficientemente puntos de división al construir árboles de decisión. El algoritmo toma prestadas técnicas de la literatura sobre multi-armed bandit para determinar cómo distribuir las muestras y la potencia computacional entre los puntos de división candidatos.
⎋ Poster
⎋ Paper
⎋ Repositorio
3. Más allá de L1: Mejores y más rápidos modelos Sparse con skglm
Los autores presentan un nuevo algoritmo rápido para estimar modelos lineales generalizados (GLM) dispersos con penalizaciones separables convexas o no convexas. Los autores lanzan un paquete flexible, compatible con scikit-learn, que maneja fácilmente penalizaciones personalizadas.
4. SketchBoost: Gradient Boosted Decision Tree rápido para problemas con múltiples salidas
Los autores presentan nuevos métodos para acelerar el proceso de entrenamiento de GBDT en el escenario de múltiples salidas, cuando la salida es altamente multidimensional. Estos métodos se implementan en SketchBoost, que a su vez se integra en la implementación GPU de GBDT basada en Python y fácilmente personalizable denominada Py-Boost.
⎋ Poster
⎋ Paper
⎋ Repositorio
⎋ Presentación
5. Benchopt: Benchmarks de optimización reproducibles, eficientes y colaborativos
Los autores presentan Benchopt, un framework para automatizar, reproducir y publicar benchmarks de optimización en aprendizaje automático a través de lenguajes de programación y arquitecturas de hardware. Está escrito en Python, pero es compatible con muchos lenguajes de programación.
6. AutoWS-Bench-101: Benchmarking de Weak Supervision automático con 100 etiquetas
Weak supervision (WS) es un potente método que permite crear conjuntos de datos etiquetados para entrenar modelos supervisados cuando los datos etiquetados son escasos o inexistentes. Sustituye el etiquetado manual de datos por la agregación de múltiples estimaciones de etiquetas ruidosas pero baratas (noisy-but-cheap). Los autores presentan AutoWS-Bench-101, un framework para evaluar técnicas automatizadas de WS en configuraciones difíciles de WS.
7. Pythae: Unificando autocodificadores generativos en Python: un caso de uso de evaluación comparativa
Los autores presentan Pythae, una biblioteca Python versátil que proporciona tanto una implementación unificada como un framework dedicado que permite el uso directo, reproducible y fiable de modelos autocodificadores generativos (autoencoder models). En particular, ofrece la posibilidad de realizar experimentos de referencia y comparaciones entrenando los modelos con la misma arquitectura de red neuronal de autocodificación (autoencoding neural network).
8. SnAKe: Optimización Bayesiana con Pathwise Exploration
Inspirándose en aplicaciones del ámbito de la química, los autores proponen un método para optimizar funciones de caja negra (black-box functions) en un entorno novedoso en el que el gasto de evaluar la función puede aumentar significativamente al realizar grandes cambios de entrada entre iteraciones, y bajo un entorno asíncrono (lo que significa que el algoritmo tiene que decidir sobre nuevas consultas antes de que termine de evaluar los experimentos anteriores).
⎋ Poster
⎋ Paper
⎋ Repositorio
9. RKHS-SHAP: Valores Shapley para métodos Kernel
Los valores de Shapley se han aplicado previamente a diferentes tareas de interpretación de modelos de aprendizaje automático, como modelos lineales, conjuntos de árboles y redes profundas, pero faltaba una extensión para los métodos kernel. En este trabajo, los autores proponen un método novedoso para calcular valores de Shapley para modelos basados en kernel e incluyen tanto un análisis teórico como una amplia evaluación experimental.
⎋ Poster
⎋ Paper
⎋ Repositorio
10. Explicar las preferencias con valores de Shapley
En este trabajo, los autores proponen Pref-SHAP, un framework de explicación de modelos basado en el valor de Shapley para datos de comparación por pares. Para demostrar la utilidad del método, lo aplican a diversos conjuntos de datos sintéticos y del mundo real (¡incluidos datos de batallas Pokémon!) y demuestran que se pueden obtener explicaciones más ricas y perspicaces frente al baseline.
⎋ Poster
⎋ Paper
⎋ Repositorio
BONUS!
En su discurso de apertura, Geoff Hinton ofreció sus reflexiones sobre el futuro del aprendizaje automático y habló de sus últimas investigaciones sobre el algoritmo “Forward-Forward” (FF), una alternativa al algoritmo de Backpropagation con motivaciones biológicas. Las ideas principales de la ponencia se resumen ingeniosamente en este hilo de twitter. Será interesante ver la influencia de este nuevo enfoque en la comunidad del ML en los próximos años.
Esperamos que esta selección resulte útil y sirva como estímulo para echar un vistazo a las ponencias y probar las implementaciones. Después de tres años y dos ediciones virtuales tras la pandemia, ha sido genial volver a estar en persona en NeurIPS y sentir ese subidón de explorar los últimos avances y líneas de investigación en la comunidad de ML con sólo caminar por los pasillos y pasar de sesión en sesión. En general, la interacción con académicos y profesionales, y el descubrimiento de trabajos asombrosos, han servido para el crecimiento intelectual, la inspiración y para tratar de estar al día en el apasionante y a la vez vertiginoso campo del Machine Learning.
Notas
- En 2019 presentamos un artículo científico en NeurIPS cuyo objetivo era modelar la incertidumbre utilizando Deep Learning para obtener grados de confianza en las predicciones. Más información: Artículo científico | Nota | Vídeo ↩︎