
Focusing on embeddings: our latest X Project
Imagine using an application like a music platform or a video streaming service. Whenever you click on a song or watch a video, the app records every action as an event. Later, instead of simply remembering which songs or videos you liked, the app uses this information to understand your preferences and suggest relevant content.
Embeddings come into play at this point in the context of navigation data. Instead of treating each song or video as independent, we can use an embedding to represent each event in a numerical space. This numerical space has special properties: for example, songs or videos with similar characteristics or that similar users are interested in will be close to each other.

We can define an embedding as a numerical representation that captures the relationships and similarities between different elements. These can be songs or videos, as in this case, but also documents, words (where their meaning or semantic relationship is captured), navigation events, or transactions. With these numerical representation embeddings provide, models can predict user preferences and needs, thus offering more personalized recommendations. In addition, different models can learn and reuse an embedding for various tasks.
This last aspect has been one of the main incentives to launch our third X project, the BBVA AI Factory innovation program, with which we seek to turn ideas into tools that different teams can use.
In this case, we wanted to standardize and make users’ navigation data in the BBVA app available to all teams as embeddings to be easily used in their models. Knowing how our customers use mobile banking is handy when adapting our models to improve their experience with digital channels or suggest actions and products that meet their needs.
Why do we use browsing data in the form of embeddings?
User browsing data in the BBVA app provides valuable information that allows us to improve the Machine Learning models we develop. Specifically, we are enhancing prediction and the ability to recover debt on the one hand and customer segmentation according to their digital behavior on the other.
Until now, however, navigation data has been scattered in various tables, making it difficult to understand and process. The process of correctly using this type of data can become a costly task for data scientists, who must correctly understand the different tables and fields available, see what specific information can help their use case, and perform the necessary transformations so that this data is in a consumable format for a Machine Learning model (feature engineering). This process is sometimes performed in a very similar way by different teams, producing a duplicated effort.
In this context, generating navigation embeddings helps us to summarize this information and facilitate its use by different teams. In addition, we speed up the time a data scientist needs to incorporate this information in developing his model.
Embeddings: trends and types
In recent years, there has been a growing and prevalent trend in Natural Language Processing (NLP) to use embeddings to convert text into a numerical representation. These are known as word embeddings. Thanks to them, Machine Learning algorithms can take advantage of the semantics and context of each word, resulting in a significant improvement in the performance of these algorithms in tasks such as machine translation, text classification, and similar.
This trend is driven by the 2013 publication of Word2Vec1, a neural network-based algorithm that uses a large corpus of text to learn associations between words.
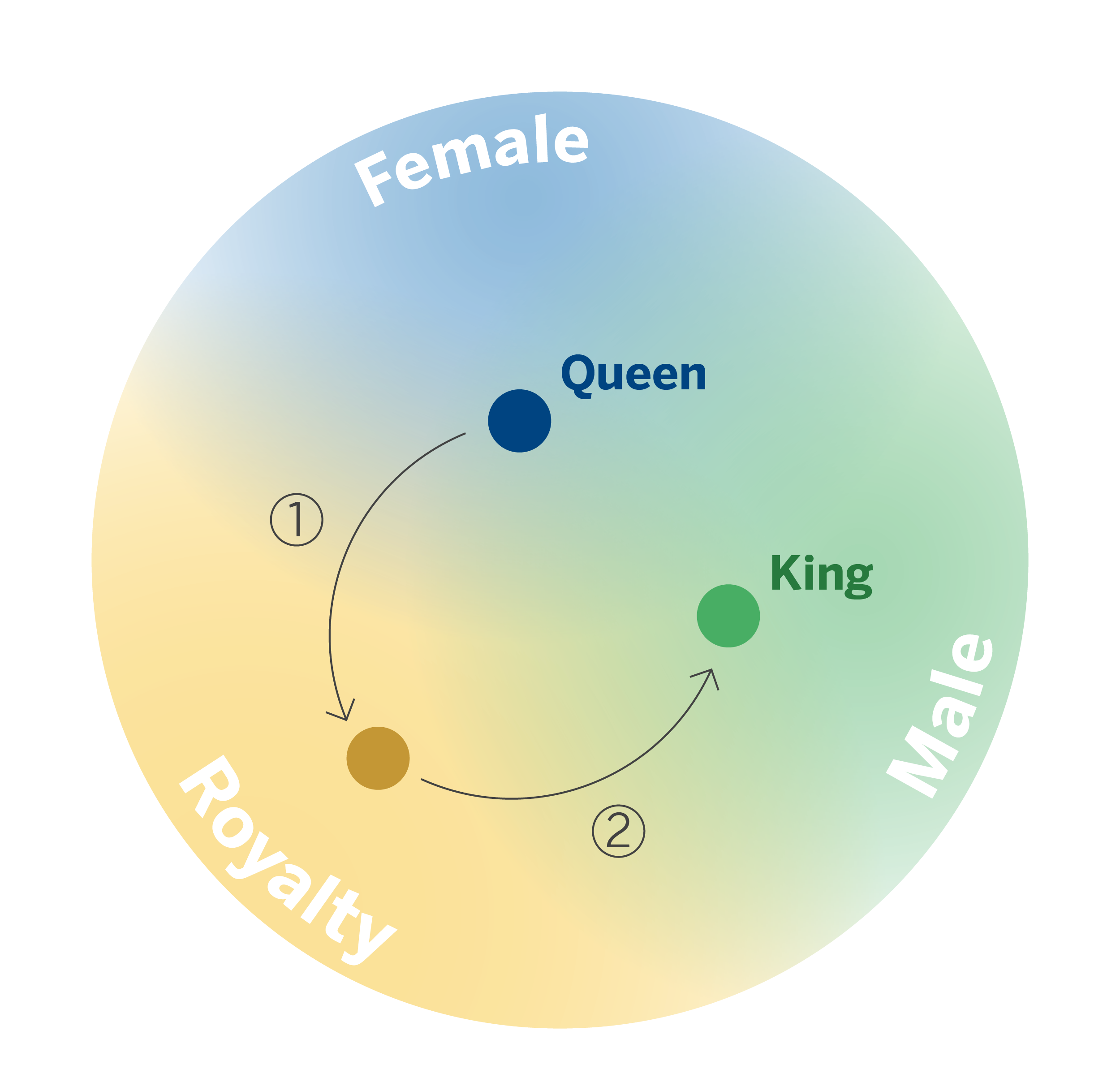
Beyond their outstanding performance in NLP, embeddings have found application in diverse areas and types of data, encompassing images, audio, time series, and product and customer information, among others. Moreover, the successful adaptation of techniques and knowledge from the NLP field has been observed in these additional areas, highlighting Prod2Vec2 and Meta-Prod2Vec3, which illustrate how to use Word2Vec with any element as long as we can define its respective context.
For example, we can represent the different products in a catalog through an embedding or vector that summarizes the information about each product. As with words of similar meaning, related products will generate similar vectors.
There are many ways to create embeddings, and new methods are frequently proposed. In the following, we will limit ourselves to summarizing some of the most commonly used methods in the industry.
Word2vec
Word2vec has been a widely used method for creating word embeddings. Its popularity and usefulness led to its use outside Natural Language Processing (NLP).
Any type of data that sequences can represent is suitable for use with the Word2vec algorithm. Consider the following example: we have user sessions on a web page, where each event in the session represents a product. When applying the Word2vec algorithm, it is helpful to think of the products as “words” and the sessions as “documents.” Thus, we will obtain embeddings for the different products so that products that are frequently visited one after the other will have a similar embedding.
Autoencoders
Autoencoders are neural network architectures that allow us to compress a vector of high dimensionality, i.e., with an excessive number of elements, and usually disperse it to another vector of much lower dimensionality. This method allows us to generate a dense vector of reduced dimensionality containing, for example, a summary of all the information we have about a user. This new vector can, therefore, be used as an embedding.
RNN and Transformers
Architectures based on recurrent neural networks can model sequential data, and their internal representation can be used to embed the input sequence.
More recently, transformer-based architectures have proven more effective in modeling sequential data, explaining why these architectures can also be used to generate embeddings. Specifically, we could use the vectors resulting from the last layer of the encoder of a transformer to create embeddings.
Graphs
In some cases, we can represent our data in a graph, that is, in the form of nodes related to each other by edges. For example, we have bank accounts that perform transactions. In that case, we can represent this data in a graph where the nodes represent the accounts and the edges reflect the transactions from one account to another.
It is possible to apply algorithms from a graph to generate an embedding for each of its nodes. In this case, embeddings can capture information such as the relationships and topology of a node.
One of the first methods proposed to generate embeddings of the nodes of a network was DeepWalk4, which is based on combining other existing algorithms such as Random Walk and Word2Vec. Node2vec5 was a proposed enhancement to the DeepWalk algorithm that offered more significant control over graph exploration. More recently, Graph Neural Networks architectures such as GraphSage6 or Deep Graph Informax7 have been proposed for node embedding generation.
Embeddings in banking
While embeddings have been frequently documented in large technology companies (Spotify, Netflix, Instarcart, Airbnb), their use has been less frequent in the banking industry.
One of the most outstanding works comes from the Capital One team. In this case, credit card transactions are represented by a graph, which reflects the bank account information associated with each card and the merchant where the purchase is made. After that, techniques for creating embeddings of a graph’s nodes are applied to obtain an embedding for each account and merchant. The objective is that accounts that make purchases at the same type of merchants end up having a similar embedding, and merchants with customers with similar purchasing habits will generate a similar embedding in the same way.
In their results, we can see some interesting facts. As a curious fact, we see that the embeddings closest to the airline “Delta Air Lines” are other airlines such as “United Airlines” or “American Airlines.”
Notes
Cover image generated with DALL·E. Prompt: Create a widescreen 16:9 aspect ratio abstract art piece featuring a large, central ‘X’ shape with a circle surrounding it. The background should be a consistent off-white, bone color. The ‘X’ is composed of interlocking lines that are part of a detailed network of geometric shapes, nodes, and lines, similar to a constellation chart. The nodes, linked by straight lines, are highlighted with subtle pastel colors like pale orange, light yellow, and soft teal. A prominent circle encases the ‘X’, creating a focal point within the complex network. The circle should be well-defined but harmoniously integrated with the rest of the design elements, maintaining the artwork’s sense of balance and unity.
References
- Tomas Mikolov, Kai Chen, G. Corrado, and J. Dean. 2013. Efficient estimation of word representations in vector space. In Proceedings of the International Conference on Learning Representations (ICLR’13). ↩︎
- M. Grbovic, V. Radosavljevic, N. Djuric, N. Bhamidipati, J. Savla, V. Bhagwan, and D. Sharp. E-commerce in your inbox: Product recommendations at scale. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’15, pages 1809–1818, New York, NY, USA, 2015. ACM. ↩︎
- Flavian Vasile, Elena Smirnova, and Alexis Conneau. 2016. Meta-Prod2Vec: Product embeddings using side-information for recommendation. In RecSys. ACM, 225–232. ↩︎
- B. Perozzi, R. Al-Rfou and S. Skiena, “Deepwalk: Online learning of social representations”, Proc. ACM SIGKDD 20th Int. Conf. Knowl. Discov. Data Mining, pp. 701-710, 2014. ↩︎
- A. Grover and J. Leskovec, “Node2vec: Scalable feature learning for metworks”, Proc. ACM SIGKDD 22nd Int. Conf. Knowl. Discov. Data Mining, pp. 855-864, 2016. ↩︎
- Hamilton William L., Ying Rex, and Leskovec Jure. 2017. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems. 1025–1035. ↩︎
- R. D. Hjelm, A. Fedorov, S. Lavoie-Marchildon, K. Grewal, P. Bachman, A. Trischler, et al., “Learning deep representations by mutual information estimation and maximization”, Proc. Int. Conf. Learn. Represent., pp. 1-24, 2019, [online] Available: https://arxiv.org/abs/1808.06670↩︎