Mercury was created to facilitate large-scale code reuse within BBVA. As a result, we have achieved the development of new data-driven products in a more efficient way. By adopting open-source principles, Mercury has increased the contribution of quality code. The bank’s data scientists can view, comment on, document, and improve the code. This library has also encouraged the sharing of ideas and knowledge, fostering a robust internal community culture.
Mercury’s analytical components are functional and productive, and are always aseptic to specific business cases. While capable of addressing a broad range of issues, many of the analytics solutions offered by Mercury are focused on solving typical financial sector problems. For example, we provide analytical components designed to facilitate the explainability and ensure the robustness of Machine Learning models, which are essential for complying with industry regulations. Additionally, we offer algorithms on transactional data to predict events or evaluate risks based on past events.
Four years ago, we created this Python library at BBVA AI Factory. Two years later, in 2021, its use was extended to the entire Data Science community of the bank. Now, we open up Mercury to the entire community so anyone interested in software development can use its components, contribute ideas, provide feedback, or help to resolve possible bugs. The Mercury core team will evaluate all contributions to guarantee the quality and relevance of the library’s components.
This step aims to encourage the use of the library and increase the number of contributions from the entire community of data scientists, developers, and software practitioners, including BBVA professionals who already use Mercury components in their daily work. Their contributions will now have a greater impact.
We believe that making some of the work we do available to everyone makes us more transparent and demonstrates how we approach working with data, with a focus on software development best practices. The data available in Mercury is intended to illustrate the different functionalities, so no confidential information is included.
The six packages already available in Mercury Library
Data scientists and Machine Learning engineers use the analytical components in Mercury to develop BBVA’s new AI-based products. The following six packages are currently available in Mercury:
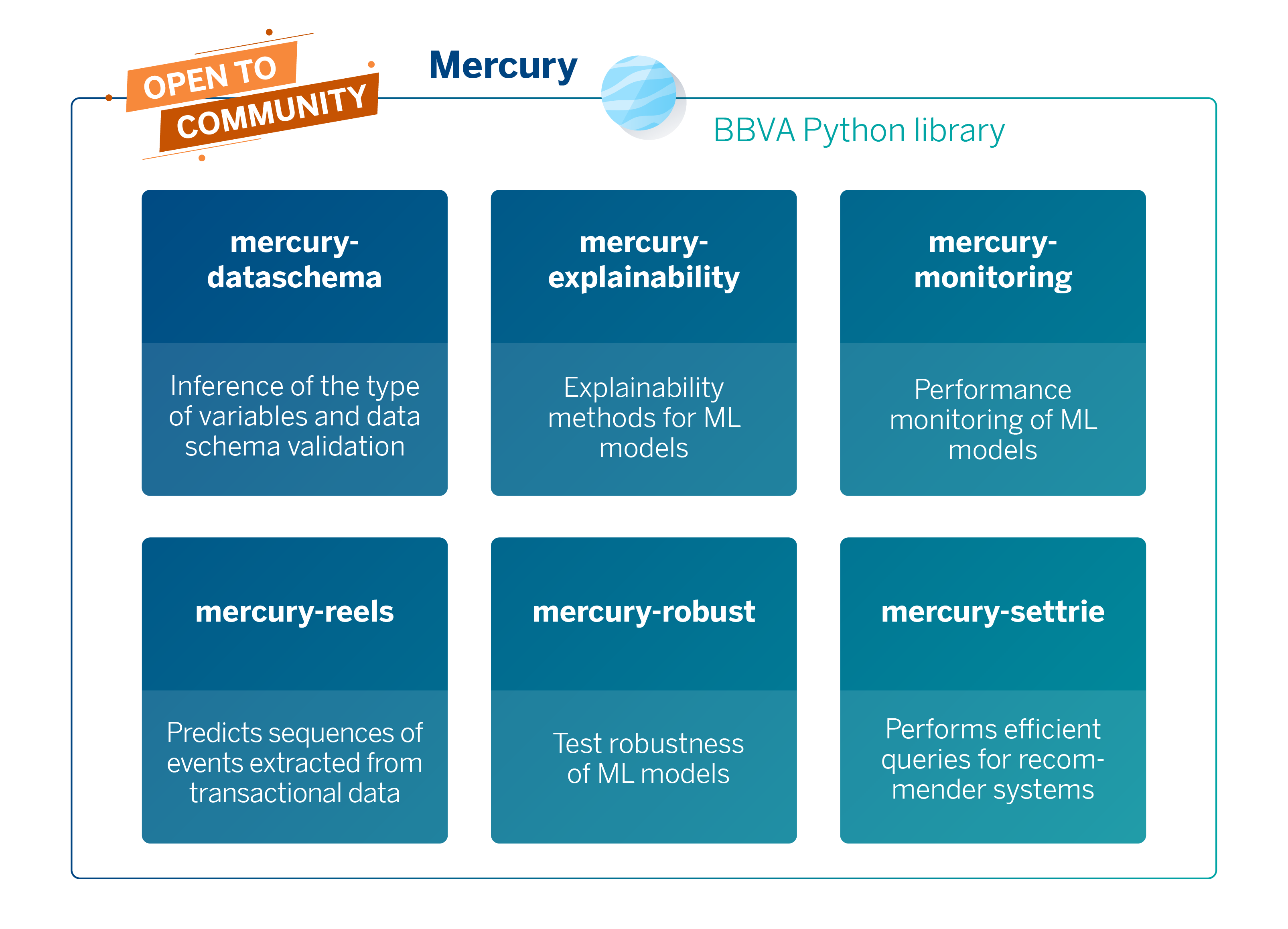

- Mercury-dataschema is a package that automatically infers the type of variables in the data and performs advanced analytics calculations, making it very useful for validating data schemas.
- Mercury-explainability is a collection of methods and techniques that facilitates algorithm explainability. Facilitating the interpretation and inspection of Machine Learning models ensures compliance with financial services regulations and positively impacts understanding of how these models work. These methods can be applied to tasks ranging from credit risk detection to creating financial product recommendation systems.
- Mercury-monitoring is a tool dedicated to monitoring the performance of Machine Learning models. Its functionality includes detecting changes in the distribution of incoming data or data drift, as well as estimating the accuracy of the model at the time of inference. It can also preemptively detect possible degradations of the models, allowing for retraining to avoid malfunctioning.
- Mercury-reels was created to analyze transactional web browsing data. It has natural applications in cybersecurity, as well as in any situation where it is possible to predict events or assess risks based on past events.
- Mercury-robust is a framework designed to conduct robustness tests on datasets and Machine Learning models. These tests detect undesirable conditions, such as mislabeled data in a dataset or a model that is excessively sensitive to deviations in the input data. Additionally, the Mercury tools help to verify that the model meets ethical or fairness criteria.
- Mercury-settrie is a C++ library for working with containers of sets. Settrie was developed to improve the algorithm for our recommender system. It has direct application in text indexing, allowing for efficient document search.
We contribute to the community
At BBVA, like in most technology companies, we use a lot of open-source libraries and tools to develop models or software solutions. Examples of these libraries and tools are Spark, Scikit-learn, and TensorFlow. Mercury is our way of contributing back to the community that has supported our company’s growth and success with the development of data-driven solutions.