
The first building block of our AI assistant: a RAG-based information agent
Agentic or multi-agent AI architectures allow us to build more comprehensive conversational assistants, as they are capable of addressing a wider variety of tasks. One of the core capabilities of any AI assistant is responding to informational queries submitted by customers or users.
In our use case, informational queries are those that can be answered in the same way for all customers using the bank’s general information, that is, without the need to access customer-specific data.
In this article, we will delve into the workings of what we have called the information agent; the first generative AI–based agent that we implemented across our customer interaction channels. The primary function of this agent is to provide accurate responses to generic queries related to the banking domain, as well as to BBVA’s procedures or products.


The knowledge base: a key element for the information agent
The information agent’s ability to generate useful and appropriate responses does not depend just on the capabilities of the LLM (large language model) being used, but also—and to a great extent—on the quality of the information available to the agent for producing those responses. In the literature, this information is commonly referred to as the knowledge base, or KB.
The information agent’s knowledge base is composed of a broad set of answers to BBVA’s frequently asked questions (FAQs), which include both relevant public information and details about the bank’s products, services, and procedures. This documentation is reviewed and approved by BBVA’s internal teams, who ensure that the information is accurate and kept up to date.
To enable the agent to use this information optimally, we preprocess it and index it in a vector database. This allows us to compare the customer’s message with the available content and determine which entries (FAQs) best match the query. After a period of experimentation, we decided to use only the FAQ titles, rather than the full text, for retrieval purposes. In other words, we encode and generate an embedding for each FAQ title, thereby capturing its semantic information. This embedding is then compared with the embedding of the customer’s query, allowing us to retrieve and prioritize the most relevant content to construct the response.
How does the information agent work? The step-by-step process within the AI assistant workflow
When a user sends a query to our assistant, it does not reach the information agent directly; instead, it first goes through a routing process that we covered in a previous article. This process is carried out by the classifier agent and essentially consists of identifying what the user wants to do. If the routing agent determines that the query is informational, the task is routed to the information agent.
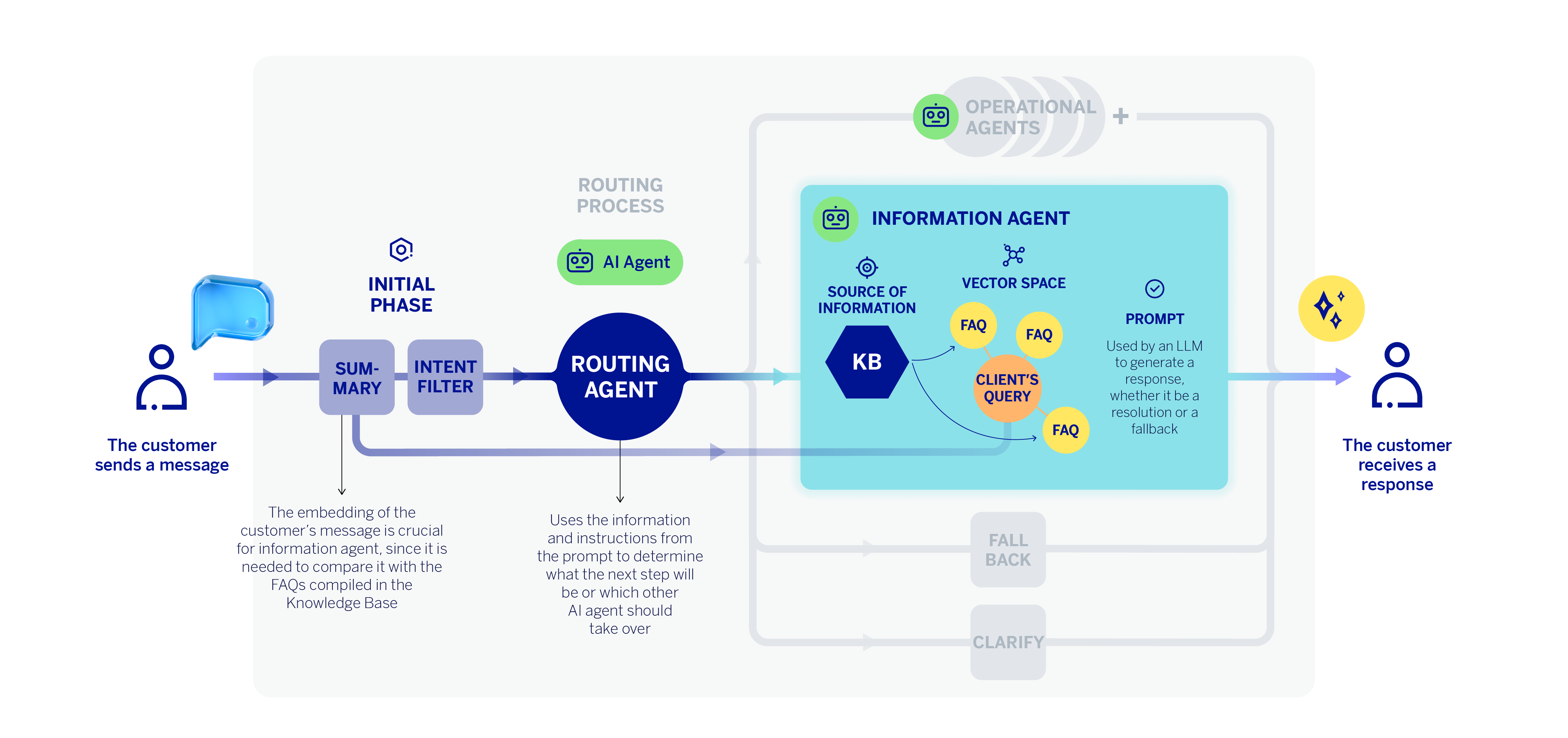
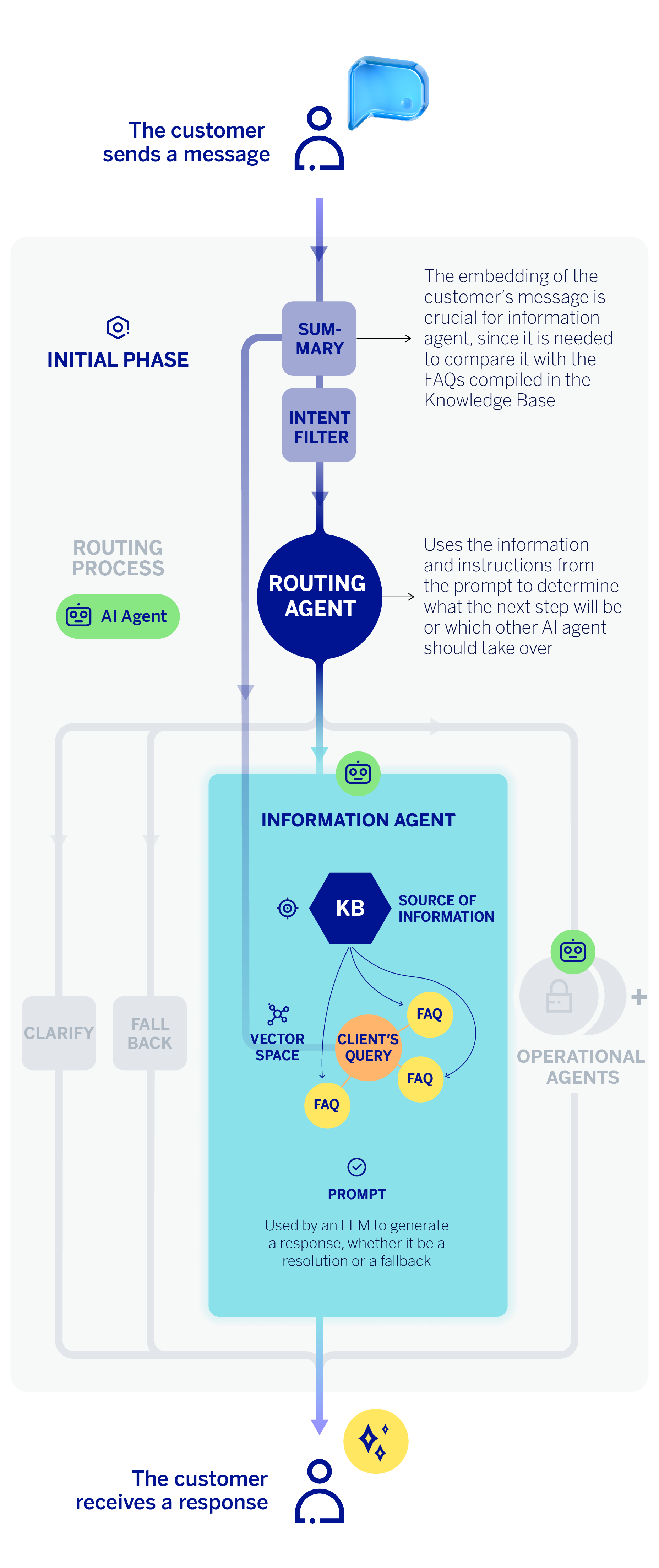
However, there is still a prior step. We are at the initial stage of the assistant’s workflow, immediately after receiving the customer’s message. The virtual assistant’s first step is to encode that message, generating an embedding that captures its semantic information. Since the assistant can understand the customer in natural language, sometimes the customer’s query is expressed across several messages—in other words, as a dialogue. In that case, an LLM summarizes the entire conversation into a single message that incorporates all the contextual information from the exchange. This “summary” or reformulation of the conversation is what gets encoded in such cases.
The embedding of the customer’s message is crucial for the classifier or routing agent, but also for the information agent, since it is needed to compare or “match” it with the FAQs that can best answer the customer’s request for information. In this way, we can perform a semantic comparison between the embedding of the customer’s message and our vector knowledge base containing the FAQ information. Using cosine similarity, we return the top n FAQs whose titles are the closest semantic match to the customer’s query.
Once this process is completed, the information agent’s LLM receives a prompt that includes: the customer’s reformulated or contextualized message, the most semantically similar FAQs—obtained from the previous step—and a set of instructions designed by the technical team. When the LLM has sufficient information and the requirements are met, it generates a response grounded in the knowledge base, which is then sent directly to the customer as the answer to their query.
The instructions or parameters included in the prompt are intended to ensure that the information agent’s responses meet a sufficient level of quality, and therefore they must be:
- Relevant, so that they address the topic of the question.
- Plausible, meaning the generative component must use only information from the FAQs and not add extra content drawn from the model’s internal knowledge. In addition, any entities it provides—such as phone numbers, email addresses, amounts, or hyperlinks, among others—must be correct.
- Helpful, that means, complete and capable of resolving the customer’s request.
- Consistent, with no contradictions.
- Comprehensive, avoiding the omission of important contextual information in the responses.
Generation of non-informational responses
When the model determines that it is not in a position to generate an informational response based on the knowledge base (KB), it replies with predefined messages depending on the underlying reason.
| Ambiguous fallback | Guardrail fallback | Knowledge-gap fallback |
| When the question is unclear or overly terse and the model cannot understand the customer’s intent, a disambiguation message is returned, with the aim of gathering more information from the customer. | When the query does not fall within the banking domain, does not apply to BBVA, or the model determines that it should not be answered, a message is returned informing the customer that it cannot respond to that question, but that it can answer others related to the bank. | When the question is well formulated and the model understands the customer’s issue but cannot find any related information in the contextual FAQs, the agent informs the user that it lacks the necessary information to provide an answer. |
| Ambiguous fallback | When the question is unclear or overly terse and the model cannot understand the customer’s intent, a disambiguation message is returned, with the aim of gathering more information from the customer. |
| Guardrail fallback | When the query does not fall within the banking domain, does not apply to BBVA, or the model determines that it should not be answered, a message is returned informing the customer that it cannot respond to that question, but that it can answer others related to the bank. |
| Knowledge-gap fallback | When the question is well formulated and the model understands the customer’s issue but cannot find any related information in the contextual FAQs, the agent informs the user that it lacks the necessary information to provide an answer. |
With that in mind, it is important to optimize the generation of either an informational response or a fallback so as not to degrade the conversational experience. An excessive use of fallback responses can give the impression that the virtual assistant does not understand the customer. However, we must also ensure that responses meet quality standards. Precisely for this reason, one of the advances aimed at preserving conversationality is distinguishing different fallback messages according to their underlying cause.
Conclusions: toward a useful and accurate informational responses in an AI assistant
One of the main takeaways from the implementation of this informational assistant is the importance of maintaining a rigorous, regularly updated FAQ knowledge base, since this is ultimately the information the assistant relies on to generate responses for customers. Moreover, by analyzing responses categorized as “knowledge-gap fallback” we uncovered relevant questions that had not previously been considered. As a result, we proposed creating new, useful information to complement what we already had.
The incorporation of RAG into informational agents has significantly improved the quality of responses provided by virtual assistants such as Blue, BBVA’s chatbot. By being able to query a knowledge base (KB), these agents can retrieve up-to-date information on BBVA’s procedures, terms, or products, without confusing it with information from other companies or providing incorrect data. This ability to answer queries with current information in natural language, combined with the capability to execute banking operations through the orchestration of different agents, is what gives agentic AI–based assistants their transformative power.
References
- Reginald Martyr, RAG Architecture Explained: A Comprehensive Guide [2025]. ↩︎