
Teaching machines to assist BBVA financial advisors
In the field of technology, experimentation and innovation are key aspects in our job. This is particularly true when it comes to developing AI-based solutions. At BBVA AI Factory we are committed to allocating specific time slots to experimenting with state-of-the-art technology and also to working on ideas and prototypes that can later be incorporated into BBVA’s portfolio of AI-based solutions. These are what we call innovation sprints.
In one such sprint, we asked ourselves how we could help financial advisors in their conversations with clients. The BBVA managers, who help and advise clients in managing their finances, sometimes search for responses to the most common FAQs within pre-defined answer repositories. This confirmed to us the potential of developing an AI system that could suggest to them possible answers to client questions and respond with a single click. The idea behind this system would be to save them time typing answers that do not require their expert knowledge, thus allowing them to focus on those that provide the most value to the client.
So we got down to work. Once the problem was defined, different ways of addressing it soon began to emerge. On the one hand, we thought of a system to search for the most similar question in the historical data to the one posed by the client, and, subsequently, to evaluate whether the answer given at the time is valid for the current situation. On the other hand, we also tried clustering the questions and suggesting the pre-established canonical answer for the cluster to which the question belongs. However, these solutions required too much inference time or were overly manual.
Eventually, the solution that proved to be the most efficient from the point of view of both inference time and the ability to suggest automatic answers to a number of questions on different topics (without carrying out prior clustering), was the sequence to sequence models, also known as seq2seq models.
¿What is seq2seq?
Seq2seq models take a sequence of items from one domain and generate another sequence of items from a different domain. One of its paradigmatic uses is the automatic translation of texts; a trained seq2seq model enables the transformation of a sequence of words written in one language into a sequence of words that maintains the same meaning in another language. The basic architecture of seq2seq consists of two recurrent networks (decoder and encoder), called Long-Short Term Memory (LSTM).
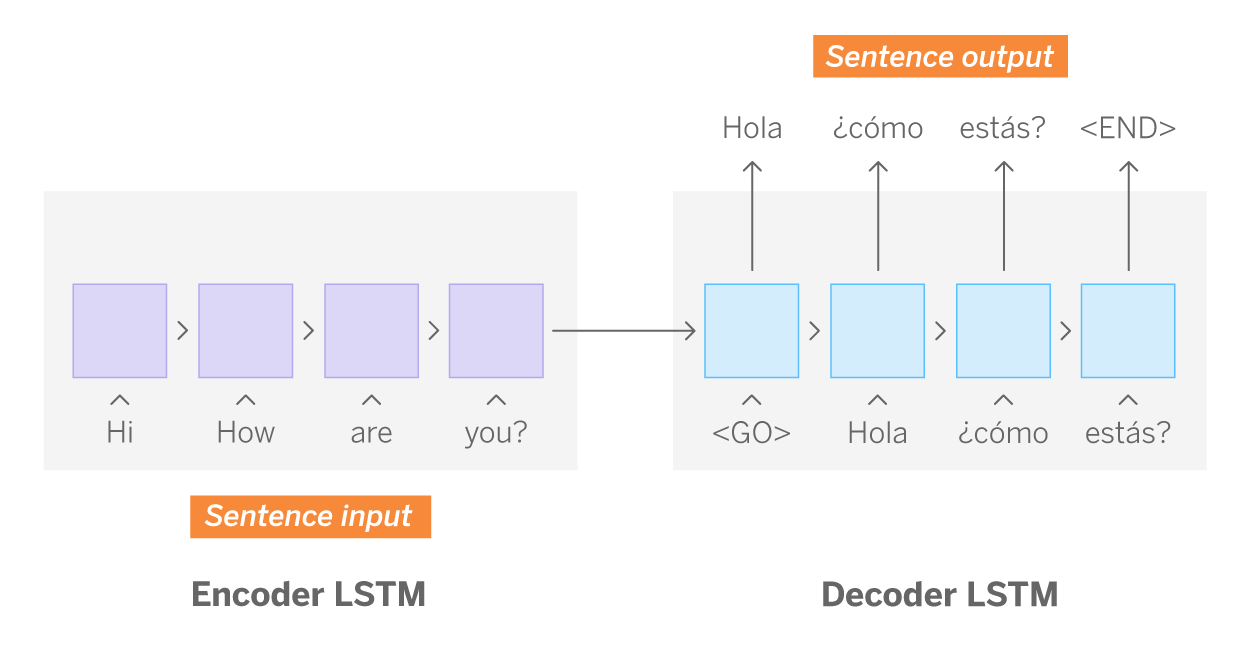
LSTM networks are a type of Neural Network in which each of its cells (hidden units) processes, in order, an element of the sequence. In this case, the representation of a word. The peculiarity of these Neural Networks is that they keep the relevant information of the previous cell, while discarding the information that is not relevant for the following cells. In this way, the network learns not only from isolated data, but also from the information inherent to the sequence, which it accumulates cell by cell. This feature is especially significant in text, since word order is important for constructing correct sentences syntactically and semantically. Technically, it is also a great advantage, since it considerably reduces the computational cost. To learn more about LSTMs we recommend reading this post by Christopher Olah.
To illustrate the concept, let’s think of language models whose purpose is to predict what the most likely next word will be. For example: “Mary was late to ____ own birthday party”. In this case, an important thing to “remember” (information that passes from one cell to the next) is the gender of the last-mentioned subject, so that the network can determine that the word ‘her’ is more likely than ‘his’ to be the correct word.
As mentioned above, the seq2seq architecture is composed of two LSTMs networks: encoder and decoder. Returning to the case of machine translation, the mission of the encoder network is to learn the structure of the given English sentences (input sequences), while the decoder does the same with the Spanish sentences (output sequences). The decoder also learns the relationship between both sequences. In this way, the result of the last cell of the encoder is a vector, called thought vector. This stores the information of the previous cells and therefore, it is a mathematical representation of the English sentence, i.e., the input sequence. Finally, the decoder uses these vectors together with the response also encoded in mathematical representation for training. During training, the network learns the patterns that allow it to associate an input sequence with an output sequence.
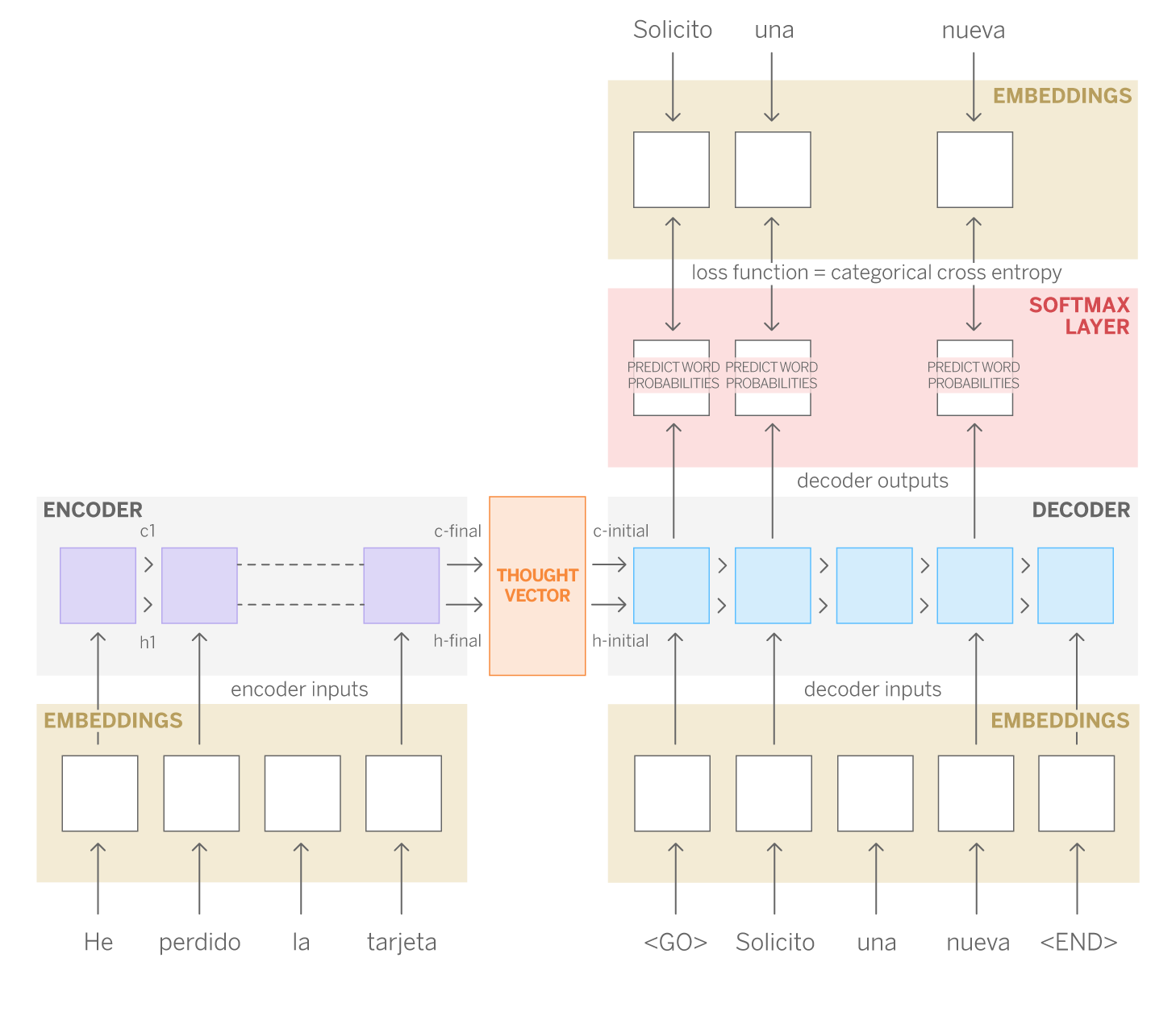
How have we applied seq2seq to build our answer suggestion system?
Although translation is one of the most obvious applications, the advantage of these models is that they are very versatile. Transferring their operation to our case, we could “feed” the encoder with the clients’ questions (sequence 1), and the decoder with the answers given by the managers (sequence 2).
This is exactly what we did. We selected from our history more than a million short conversations initiated by the client with their manager (no more than four messages). With this dataset, we performed a classic pre-processing (lowercase, remove punctuation marks) and discarded greetings and goodbyes using regular expressions. This step is useful because one of the hyper parameters of LSTM networks is the length of the sequence to be learned. This is why, by removing this non-relevant information, we can take better advantage of the learning capacity of the model for more diverse or variable sequences, as well as reduce the computational cost of learning longer sequences. Prior to the preprocessing phase, the data arrives anonymized based on our own NER (Named Entity Recognition) library so that sensitive data such as name, phone, email, IBAN (and certain non-sensitive entities such as amounts, dates or time expressions) are masked and treated homogeneously. Consequently, the model gives them the same importance.
Once the network is trained, we use some test questions (not included in the training) and manually evaluate the suggestion of our system. As we can see in the following example, the model is able to suggest a suitable answer to client questions.

However, when the question is related to a client’s particular situation, the suggested answer is not entirely satisfactory. This is because the model does not take into account the specific context of each client.
For example, in the case shown below, the system proposes a response that could be correct but does not consider whether the card has in fact already been sent to the client. This contextual information is currently not contemplated by the model. One of the next steps in this research would be to obtain the model to learn how to generate the response message according to the current situation of the client in a specific case.

Finally, there are also some cases in which the model answer suggested to the manager is erroneous, as it is not related to the question asked by the client.

How do we validate our seq2seq model?
Evaluating the result of an automatically generated text is a complex task. On the one hand, it is impossible to manually evaluate a relatively large test set of questions and answers. In addition, if we wanted to optimize the model, we would subsequently need some or other method to measure the quality and appropriateness of the answers suggested by the model automatically.
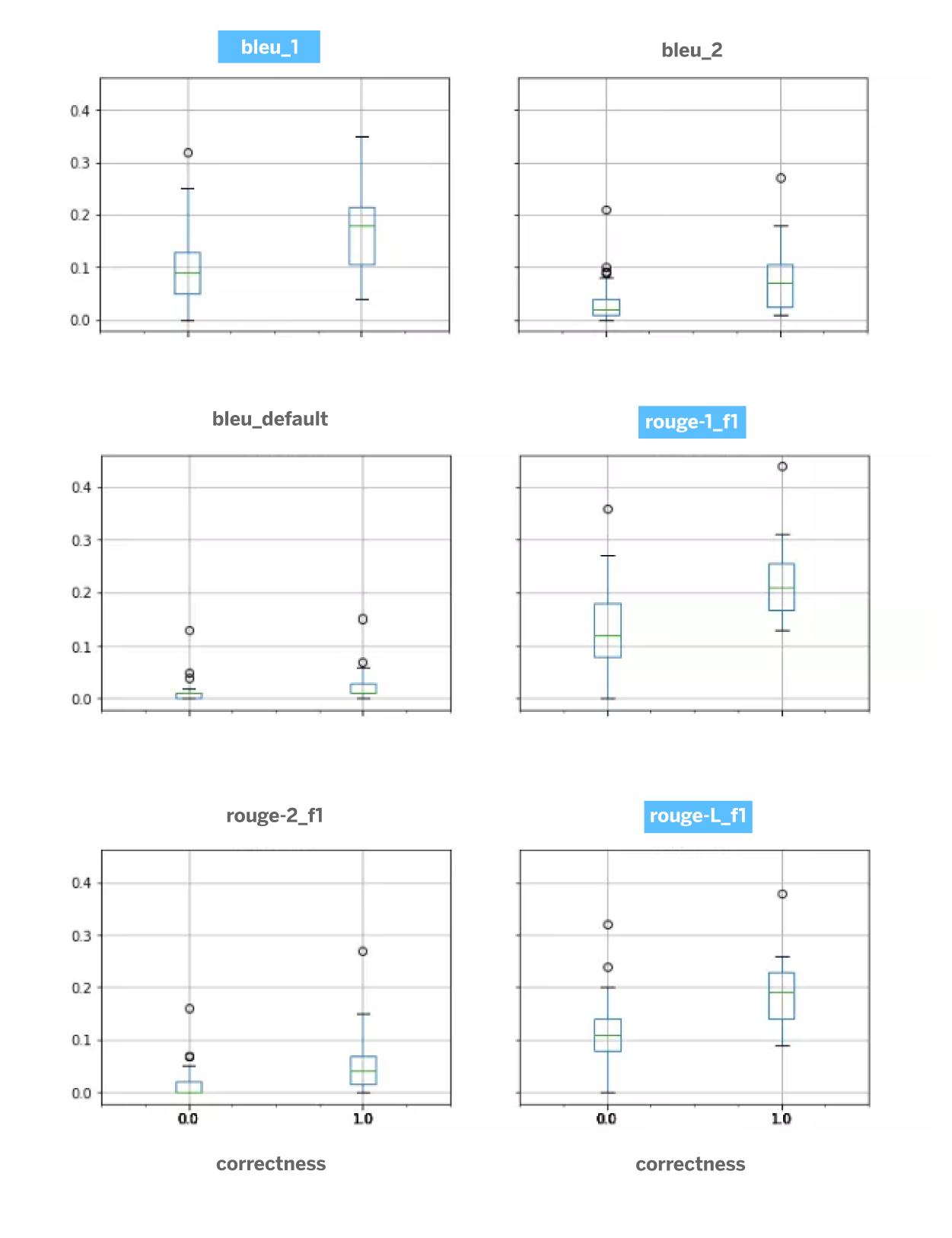
However, we are able to make a manual evaluation that allows us to ascertain – with a small set of messages and according to our criteria as clients1. We use two criteria for manual evaluation: answerability and correctness. The first of these qualitative metrics determines in which degree a question can be answered, in order to check what the business impact would be, and the second evaluates whether the answer suggested by the model is correct or not, which gives us an idea of the quality of our seq2seq model. With this evaluation we found that not all client questions can be solved with this approach at the moment. The main reason lies in the need to take into account contextual information, either previously provided by the client, previously commented by a specific manager or personal and financial information of the client. – which answers are appropriate and which are not. Subsequently, the correlation is calculated between our manual evaluation and the evaluation obtained by sets of automatic metrics such as Rouge, Blue, Meteor or Accuracy.
The following figure represents the correlation between the manual evaluation (false: wrong answer, true: correct answer) and the values of the automatic metrics. In a first analysis we observe that bleu_1, rouge_1 and especially rouge-L are the metrics that best align with the human criteria. This is important for the optimization of the seq2seq architecture and for the automatic evaluation of the system. Although this study would require further research, we consider it sufficient for this prototyping phase.
With these first tests performed with seq2seq (we have omitted some failed experiments and other decisions made along the way), we have been able to demonstrate the enormous potential of this technique in the context of client-manager communications at BBVA. A seq2seq-based system is able to suggest answers to simple client questions. However, for many other tasks, such as answering questions related to the specific context of a client, it is much better to opt for a direct contact with our BBVA managers.
Notes
- We use two criteria for manual evaluation: answerability and correctness. The first of these qualitative metrics determines in which degree a question can be answered, in order to check what the business impact would be, and the second evaluates whether the answer suggested by the model is correct or not, which gives us an idea of the quality of our seq2seq model. With this evaluation we found that not all client questions can be solved with this approach at the moment. The main reason lies in the need to take into account contextual information, either previously provided by the client, previously commented by a specific manager or personal and financial information of the client. ↩︎