
Training, an Essential Perk to Retain a Data Scientist Profile
BBVA Data & Analytics’ first milestone was achieved in 2011 when BBVA’s Innovation Unit set up a small research team, committed to using existing data sources to solve business challenges. Several external partnerships with research institutions, other startups, Telecom corporations and public institutions, offered promising results such as the massive identification of highly profitable customers formerly labeled as standard customers, and made visible the need of a solid strategic approach to data discovery and analysis.
That’s how BBVA Data & Analytics was established, in February 2014, as a fully owned subsidiary of BBVA, and mainly for two reasons: we wanted to commercialise non financial products based on data, and to have a more agile and differentiated model of talent attraction and management, from both an operational and cultural point of view.
What did we need at that time?
So we wanted to attract highly skilled and talented people, able to extract value from big amounts of data, make recommendations, identify patterns, propose new explanations to trends and new solutions to problems, and translate it into an understandable language to our colleagues of BBVA’s business units. We needed Data Scientists. And we wanted the top Data Scientists on the market. We imagine how all of you have heard that Data Scientist is the sexiest job in the world. Other than sexy, it was a really new and unknown profile, at that time, and really hard to find and define, especially when it comes to detecting the top tier professionals in the field. A balanced mix between statistics, programming, Big Data tools, machine learning knowledge, problem-solving skills, communication skills and a good intuition to understand and explore the Bank’s problems is no easy task to achieve. Therefore, it was necessary to design a Talent and Culture management model focused on attracting and retaining that talent, once it was found.
Our approach
The first step we took was to acquire a profound understanding of what it means to work as a Data Scientist and what Data Scientists’ aspirations are. For 8 months we interviewed an average of 2 to 3 candidates a day, including staff members in the process. We soon got a pretty good idea of what drivers are key for them. Hence, we designed policies and procedures tailored to approach their needs and expectations in an effective and attractive way. We understood that bespoke management, empowerment and flexibility were paramount.
The market is over-demanding and overpaying this kind of scarce profile and Data Scientists get job offers on a daily basis. However, in general terms, it’s not only about the money! A higher salary is not the key if it doesn’t come along with analytical challenges and a flexible working environment, something we have learned by listening to our Data Scientists.
Likewise, keeping up to date is a must for their professional development and one of their primary concerns. Being able to widen their knowledge, carry on research, publish scientific papers, and ultimately, push the state of the art of the discipline further.
All this while working within a company with real-time projects signifies a major draw for these people, and is available only in very few companies.
These are profiles with very different knowledge and interests, at different levels. Moreover, we truly believe that each of our team members is the best suited to identify and choose the training that best fits his/her needs, motivations and knowledge level. And so, we handed over that decision to them. One of our key competencies is Flexible Responsibility; we like to apply it to everything we do, so the training plan was not going to be an exception. And so, instead of the classical general training catalog, that does not cover for their special needs, we have designed a three axis-based plan of basic, Individual and extraordinary training, allocating a budget for each of them.
Basic training covers the team’s cross-cutting needs, such as proficiency in languages, skills’ development or some technical tool to be used by everyone. Besides, each employee has assigned money per calendar year for individual training, based on his/her personal choice, as long as it relates to our activity. Extraordinary training is budgeted for worldwide events and conferences, or other training exceeding the individually allocated training budget, that the team, in general, can benefit from. Knowledge-sharing, in both general and deep dives sessions and workshops, is a main condition to get your application approved.
How our team chose its training over the years
Since 2015, when our Talent management model became a reality, our Data Scientists had the opportunity to choose how to spend the money assigned per person, each year, to individual and extraordinary training.93% of our data scientists take advantage of their individual training budget, up from 82% in 2016, and throughout 2017, 56% of the employees have spent over 90% of their allocated budget. Back in 2015, online courses were the first training option, with a 30% over the total, while currently presential courses are the main choice, representing 59% of the total.
For data-driven is part of our culture, let’s look at some quantitative figures. In the graph below you can explore the evolution of expenditure categories over the years:
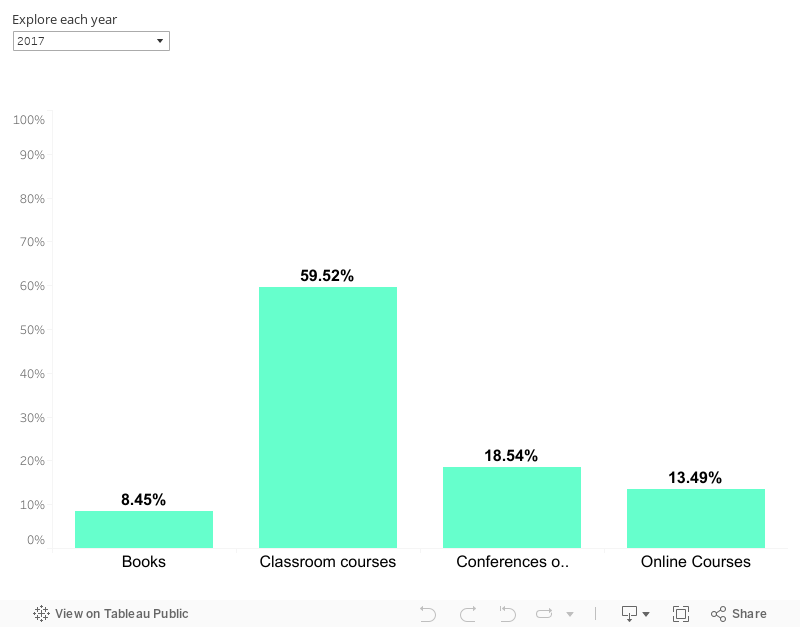
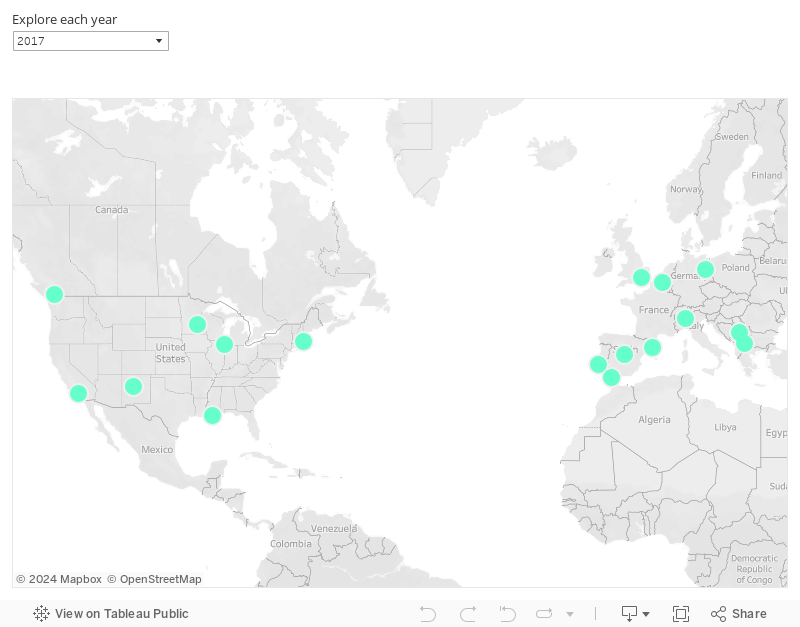
At the same time, our team has the possibility to keep up with the state of the art in Data Science by attending numerous conferences of their choice. Below you can explore where we’ve been:
What we do and what we are is what defines us
All the work we have done is part of a philosophy of continuous learning and personal development process, meant to be agile, based on active and bidirectional listening, and immediate action. With all the policies, procedures and management style we have deployed here, we have created a company culture which is the result of what we do and what we are, and not what we say we should be.
Our team has proposed spontaneously possible training topics, as well as the possibility of inviting Top Tier Data Scientists1 to participate in talks related to cutting-edge techniques and how to apply them to our problems in working sessions with us.
Notes
- Some of these top-level scientists are DJ Patil (Former U.S. Chief Data Scientist at White House Office of Science and Technology Policy), Usama Fayyad (Chief Data Officer & Group Managing Director at Barclays Bank), Le Song (Assistant Professor at Georgia Institute Technology), Kalyan Veeramachaneni (Research Scientist at MIT), Roberto Paredes (Associate Professor at Universidad Politécnica de Valencia), Jordi Vitrià (Full Professor at Universidad de Barcelona and Senior Researcher at Centro de Visión por Computador), Carmen Cadarso Suárez (Full Professor at Biostatech, Universidad Santiago de Compostela), Fernando Pérez-Cruz (Associate Professor at Universidad Carlos III de Madrid), Miguel Romance (Associate Professor at Universidad Rey Juan Carlos de Madrid), Regino Criado (Associate Professor at Universidad Rey Juan Carlos de Madrid), Lisa Gansky (Executive Director at 11FS), Barbara Wixom (Principal Research Scientist Center for MIT CISR), Alex Arenas (Professor at Universidad Rovira i Virgili,), JJ Ramasco (Researcher at IFISC), Yuri Engelhardt (Information designer), Eneko Agirre (Researcher in the area of Natural Language Processing at University of the Basque Country), and recently, José Vicente Rodríguez Mora (Researcher from The Alan Turing Institute), to name a few. ↩︎
- Article written by Ana de Melo e Faro