
What we saw in Graph Analytics in 2019
As we announced in this post, the Graph Analytics Team at the AI Factory delivers graph data assets and creates an internal software library to facilitate the use of graph algorithms at BBVA.
This article aims to summarize what we saw and the progress made in Graph Analytics during 2019. It can be considered as a collection of resources and references that we find relevant for this topic. This includes Open Source code repositories and Commercial tools, scientific papers, conferences, workshops and other types of publications. All of this has inspired our recent work.
Tracking adoption of graph technologies in businesses
The adoption of graph-related technologies by businesses follows a maturity curve which typically goes from the initial phase of using graphs in a single use case to an ideal situation where the company successfully exploits graph data and tools on a recurrent basis. In this process we could distinguish four different phases, which mark the path towards the adoption of graphs:
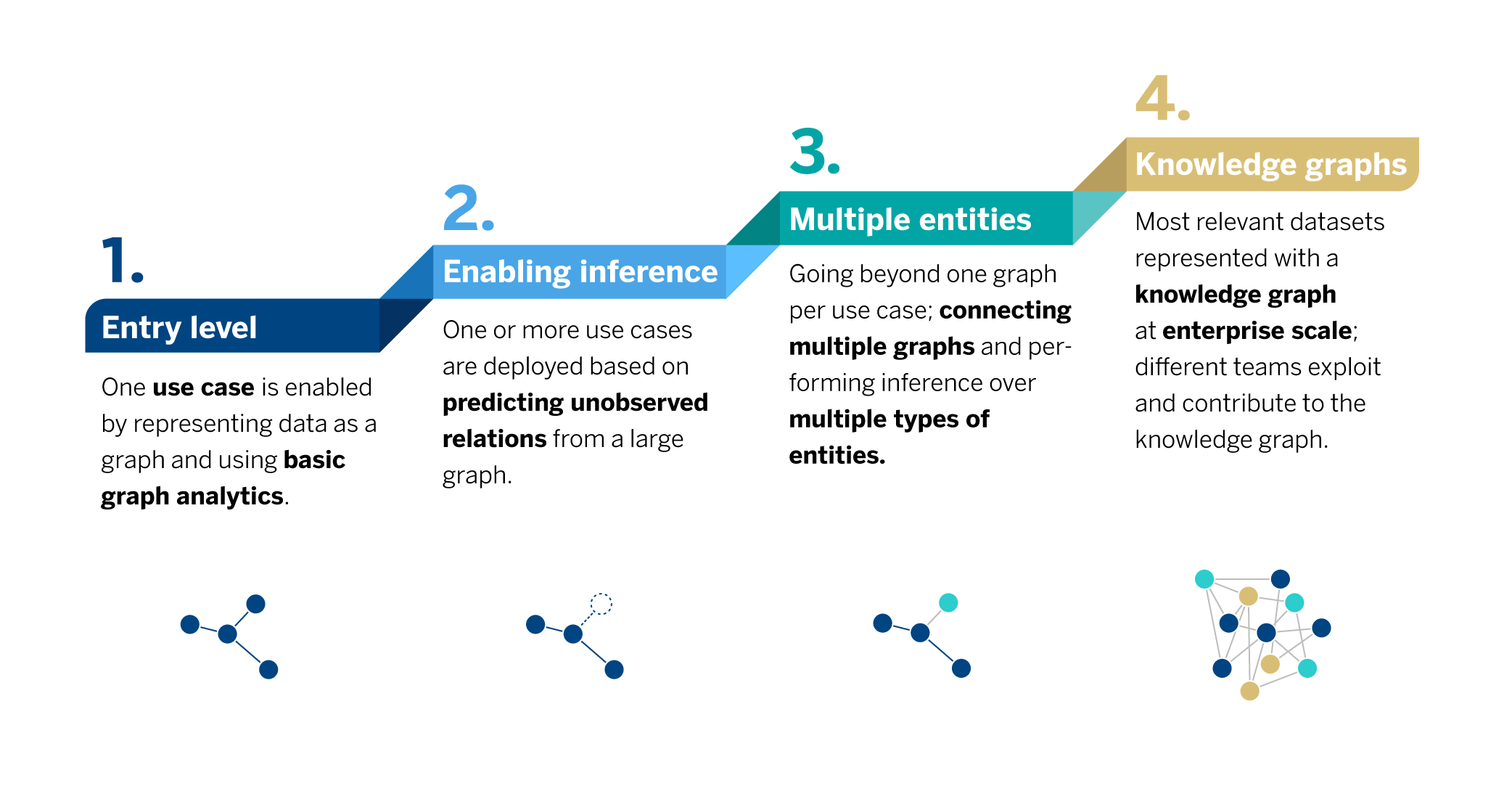
Some players have already presented their proposals for the phases towards graph adoption, i.e. Neo4J’s talk at Spark Summit, or the following article from Forbes.
Some use cases and tools in data science conference
Next, we describe technical updates and advances in Graphs, as presented at relevant conferences during the course of 2019.
Graphs at Spark+AI Summit Europe 2019
The Spark + AI Summit Europe 2019 showcased some use cases of Graph Analytics. Tiger Graph showed how they worked with China Mobile to detect phone-based scams using real-time graph analytics. Using a graph of phone calls of 600M users they create graph features used in a machine learning model classifying a phone call as being a scam call or non-scam call in real-time.
Another example comes from AstraZeneca. This biopharmaceutical company showed how they use a Knowledge Graph in the process of drug discovery, where graph analytics is able to reduce the usual huge costs and time requiredments.
In this same conference, we found out about some changes planned for Spark 3. A new module based on Spark SQL Dataframes will be added to represent graphs using the Property Graph data model. The Property Graph data model allows practitioners to represent graphs with different node and edge types and define relating properties. This provides considerable flexibility when representing graphs. Moreover, the Cypher query language is planned to be added, which will allow for expressive and efficient data querying in property graphs.
Graphs at KDD 2019
At KDD, Alibaba presented their AliGraph platform(in the financial domain, we saw this other example from Capital One). We saw articles proposing graphs to jointly model concepts and instances in a knowledge base, and many deep learning algorithms for graphs, including “OAG: Toward Linking Large-scale Heterogeneous Entity Graphs”, a deep learning algorithm for record linkage in large entity graphs, with GitHub repository.
The MIT-IBM lab released The Elliptic Dataset, a large dataset of financial (bitcoin) transactions, and presented a paper on anti-money laundering at the KDD workshop on Anomaly Detection in Finance.
Graphs Workshops in the top ML conferences
- NeurIPS 2019 Workshop about “Graph Representation Learning”
- ICLR 2019 Workshop about “Representation Learning on Graphs and Manifolds”
- ICML 2019 Workshop about “Learning and Reasoning with Graph-Structured Representations”
Graphs in Recommender Systems
The relations between heterogeneous nodes in graphs has proven to be a rich source of information for recommender systems and entity representation. Some recent examples:
- Collaborative Similarity Embedding for Recommender Systems1. In The World Wide Web Conference (pp. 2637-2643). In this paper, authors present a “unified framework that exploits comprehensive collaborative relations available in a user-item bipartite graph for representation learning and recommendation.” To determine relations between these two types of entities, the authors make use of proximity relations that capture both explicit (user-item) and implicit (user-user and item-item) relations.
- N2VSCDNNR: A Local Recommender System Based on Node2vec and Rich Information Network2. IEEE Transactions on Computational Social Systems, 6(3), 456-466. In this paper, authors presented a “novel clustering recommender system based on node2vec technology and rich information network.” Specifically, their proposal (i) transforms bipartite graphs to the corresponding single-mode projections (i.e., user-item relations to user-user and item-item ones); (ii) learns node representations using node2vec; and (iii) links users’ and items’ clusters to obtain personalized recommendations.
Other papers we found relevant
A review of the state of the art where they provide a taxonomy which groups graph neural networks into four categories:
- graph recurrent neural networks,
- graph convolutional neural networks
- graph autoencoders
- spatial-temporal graph neural networks
Another review that addresses the following topics:
- Hyperbolic Graph Embeddings
- Logics & Knowledge Graph Embeddings
- Markov Logic Networks Strike Back
- Conversational AI & Graphs
- Pre-training and Understanding Graph Neural Nets
Graph Inference using conditional probabilities: Variational Spectral Graph Convolutional Networks. The authors propose a “Bayesian approach to spectral graph convolutional networks (GCNs) where the graph parameters are considered as random variables. We develop an inference algorithm to estimate the posterior over these parameters and use it to incorporate prior information that is not naturally considered by standard GCN.”
Tutorials and books
- Neo4J book with practical examples in Neo4j and Apache Spark.
- Dissemination vídeo from Neo4J at Spark Summit.
- Knowledge Graphs tutorial
Commercial tools
- Amazon Neptune
- Tiger Graph: Native Parallel Graph Platform
- Graphext, a platform for graph data analysis and visualization (that you don’t need a strong technical background to use).
Open Source Code Repositories
- Upenn GNNs
- Tutorial for Knowledge Graphs in linguistic
- Notebooks from a workshop at AMLD 2019 about Network Science, Spectral Graph Theory, Graph Signal Processing, and Machine Learning.
- A multi-agent simulator of anti-money laundering
- Open source library based on TensorFlow that predicts links between concepts in a knowledge graph. Developed by Accenture.
- Graph algorithms performance comparation with GPUs
- Knowledge Graph open source tool: Blue Brain Nexus. A very interesting initiative and an opportunity to put into practice at a workshop atApplied Machine Learning Days 2019