
AI Evaluation in the Age of Agents: Building Reliable and Useful Assistants
In previous articles, we have analyzed the different types of agents that make up Blue, BBVA’s AI-powered virtual assistant. However, there is one aspect we have not covered thus far: their evaluation, both in terms of the accuracy of the decisions made, as well as the appropriateness and usefulness of the responses generated during a conversation with a customer.
When working with systems based on large language models (LLM), which can generate new and unpredictable responses, implementing evaluation methods and measuring their performance is critical in order to build robust, reliable and truly useful AI solutions.
These evaluation mechanisms allow us to monitor how the system performs in real conditions, detect deviations, identify recurring errors and turn these insights into concrete improvements for future iterations. We can also mitigate one of the best-known risks of generative AI: hallucinations, or answers that seem plausible, but are not grounded in reality. Even when using Retrieval Augmented Generation (RAG) architecture, which is designed to rely on specific knowledge bases and reduce this risk, it remains possible that the system could produce unfounded statements or even statements that contradict the retrieved context. Therefore, continuous evaluation is critical to detect these errors and prevent them from translating into incorrect responses for the user.
In this article, we will focus on some of the evaluation methods applied to the different types of agents that make up Blue: the informational agent, the classification or routing agent and specialized agents. The goal is to show how we translate the need to evaluate these models into concrete metrics to measure more effectively, learn faster and deliver increasingly useful responses.
Evaluation of the informational agent: LLM as a judge
The Blue agent tasked with responding to informational queries is based on RAG architecture. This technique ensures that the AI agent takes into account a specific knowledge based validated by BBVA when answering customer questions. This way, we guarantee that Blue provides verified banking information without losing the LLM capabilities to converse in natural language.
When evaluating the quality of generation in a RAG system, knowing whether a response “seems correct” is not enough. What is actually useful is understanding what decision the informational agent made, at what point in the process it may have deviated and how to interpret this failure.
With this idea in mind, we have come up with a ‘self-critique’ mechanism based on the “LLM as a judge” paradigm, where another LLM evaluates the responses generated by the informational agent. This heuristic is not limited to assigning a verdict or final score. Instead, it organizes the evaluation into a logical sequence of checks that allow us to distinguish between questions that should have been answered, on the one hand; and generated responses that should have been marked as fallback (not answered due to a lack of context or being outside the scope of banking) on the other, and finally responses that while seemingly valid, are not actually useful, also diagnosing why by assigning an error type.
The first decision in this evaluation mechanism involves distinguishing between the cases where the model produced a fallback from those where it generated a substantive response.
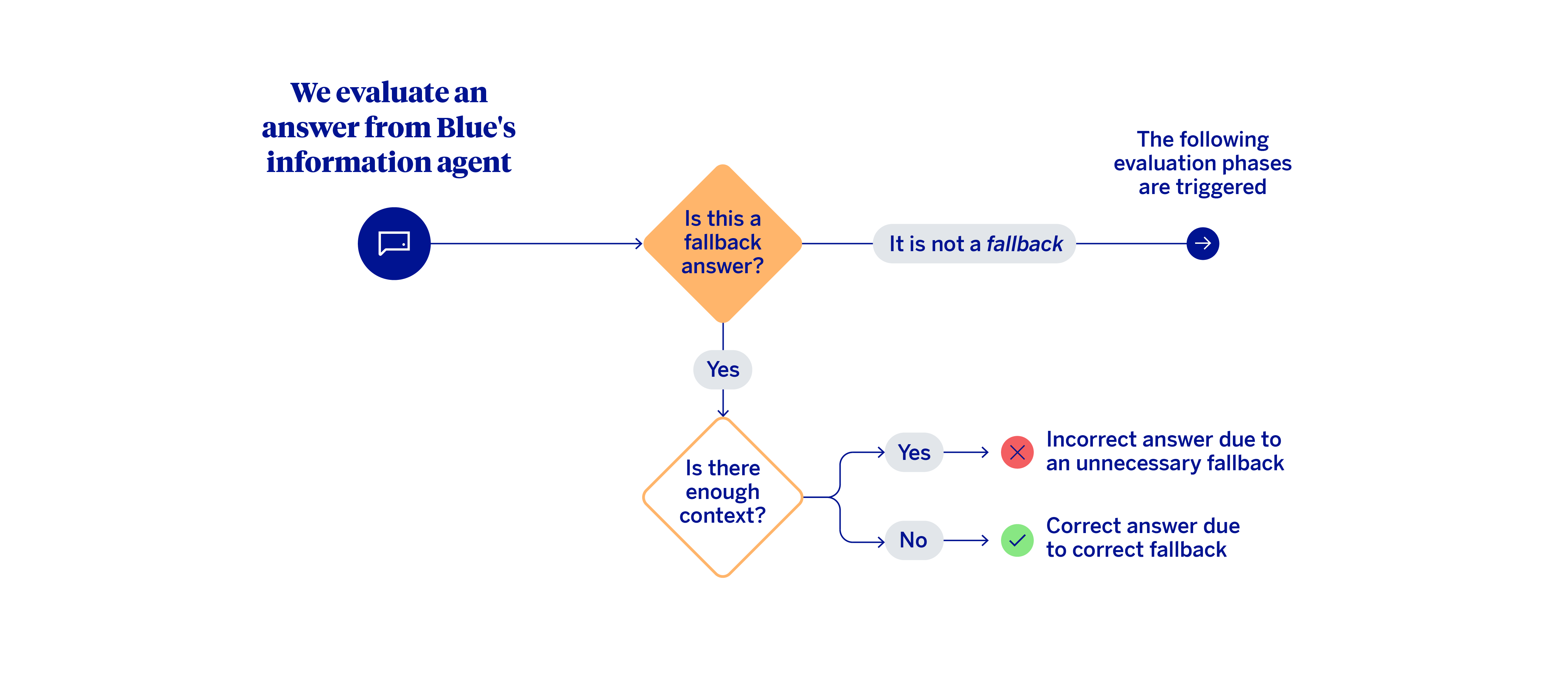
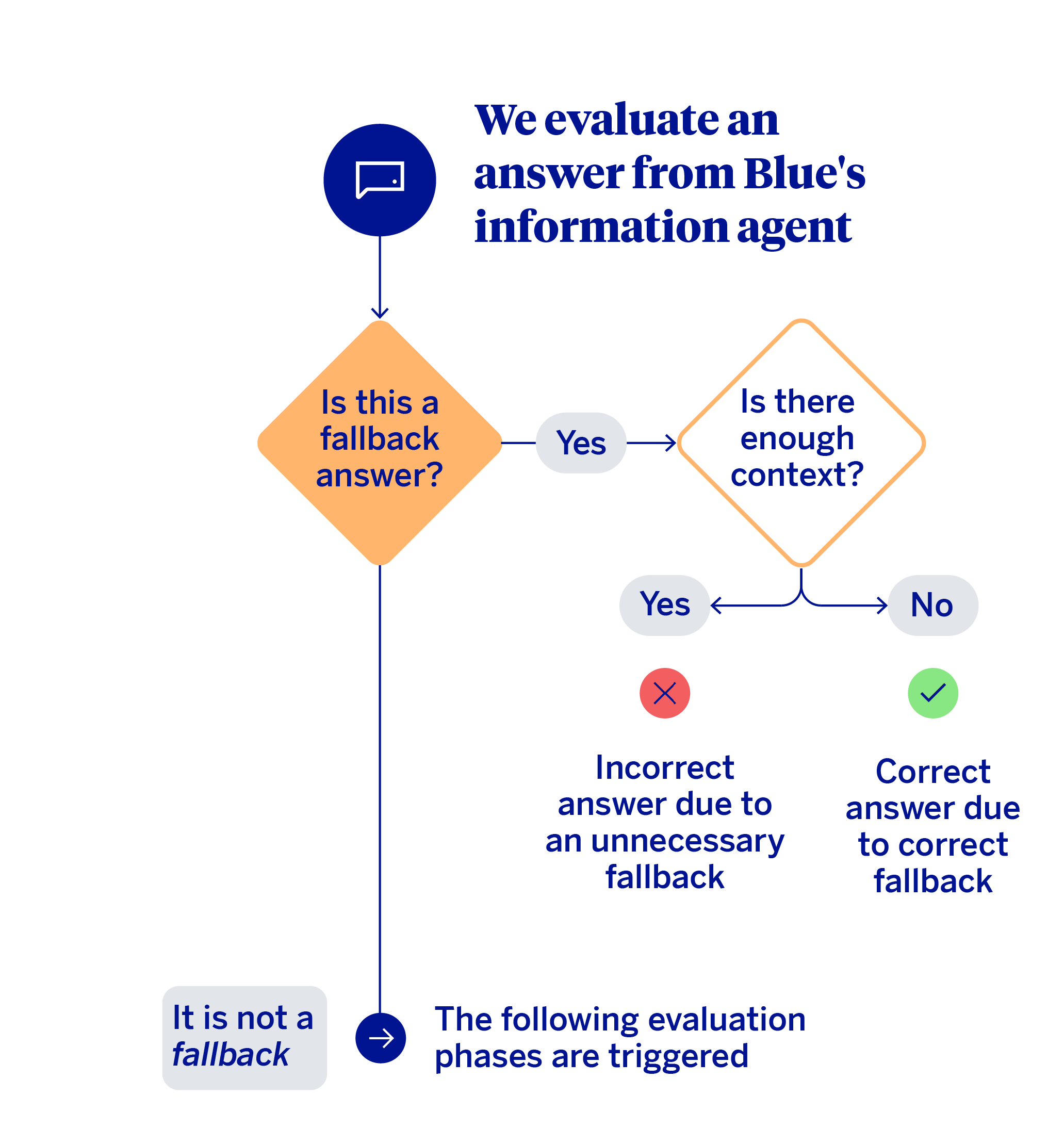
When a fallback occurs, the key question is whether or not the agent actually had sufficient context (knowledge base) to answer. If the context was insufficient, performance could be considered correct. On the other hand, if there was relevant information to respond to the query, and the system still opted not to, then it was an unnecessary fallback. In these cases, the system should have answered the query. When there is no fallback, meaning the agent responds to the specific question the customer asked, the heuristic proceeds to a multi-level evaluation.
The next section checks two basic metrics: relevance and grounding. Relevance reviews whether the response actually answers what was asked and maintains a coherent, thematic logic. Meanwhile, grounding analyzes whether the information was taken from documents provided in the context, or whether the response fabricates some information, potentially drawing on its own internal knowledge. Furthermore, it places emphasis on sensitive or literal elements in particular, such as instructions, amounts, references or aspects that should not be summarized or altered. These two checks come first because they act as a primary filter: if a response is not relevant or introduces ungrounded claims, it does not make sense to continue refining the evaluation with more sophisticated criteria.
After passing this first level, the mechanism evaluates a new metric: the usefulness of the response. At this stage, it is no longer enough for the response to be relevant and grounded, it also must be able to address the user’s need using the information available in the context, without omitting essential details. This dimension introduces an important concept into the generative evaluation of RAG systems: a response may not be fabricated and yet it could still be deficient if it fails to take advantage of the truly critical fragments needed to answer the question accurately.
To complete the flow, the final validation conducted is related to the consistency and coherence of the responses. This final stage evaluates whether the generated response contains contradictions or combines information incorrectly. If this type of error is not detected in the response, or in any of the previous steps, then the process concludes by classifying the response generated by Blue as correct.
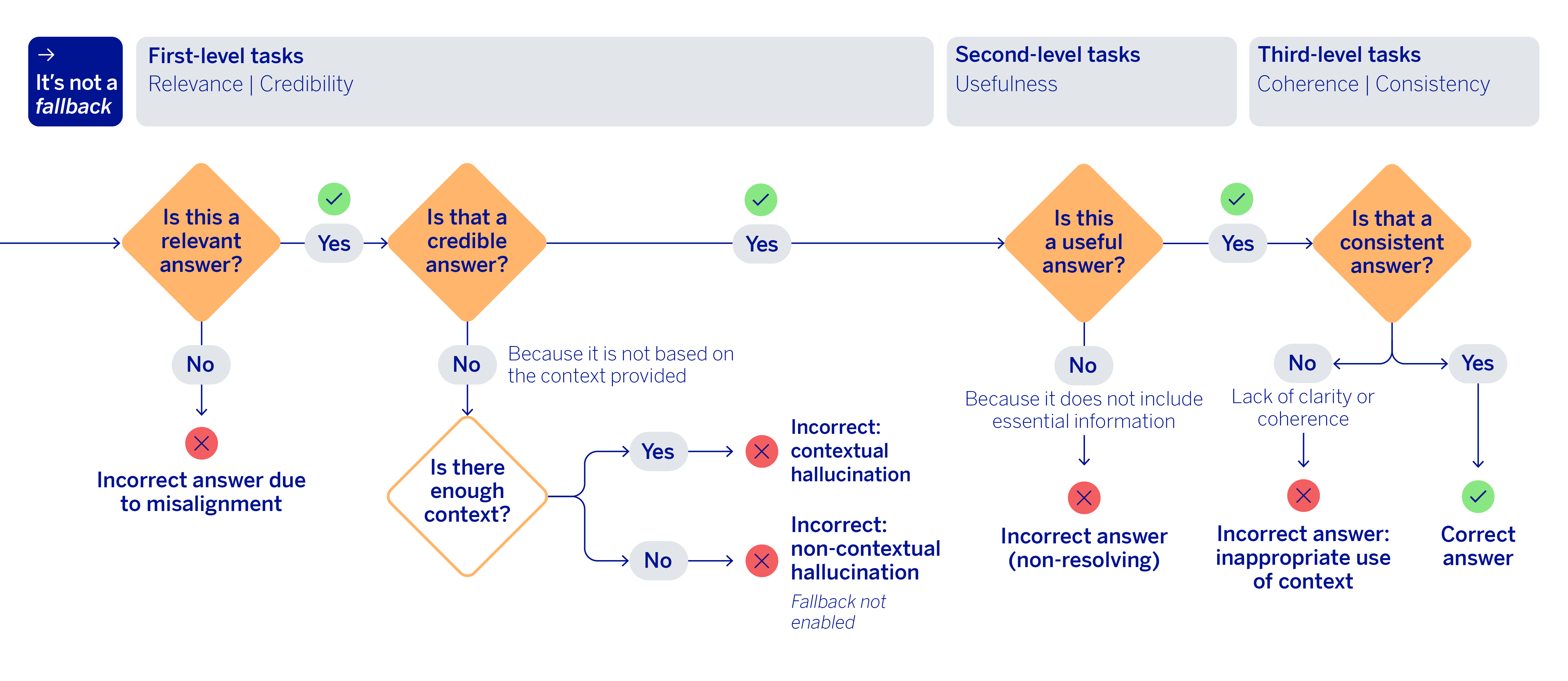
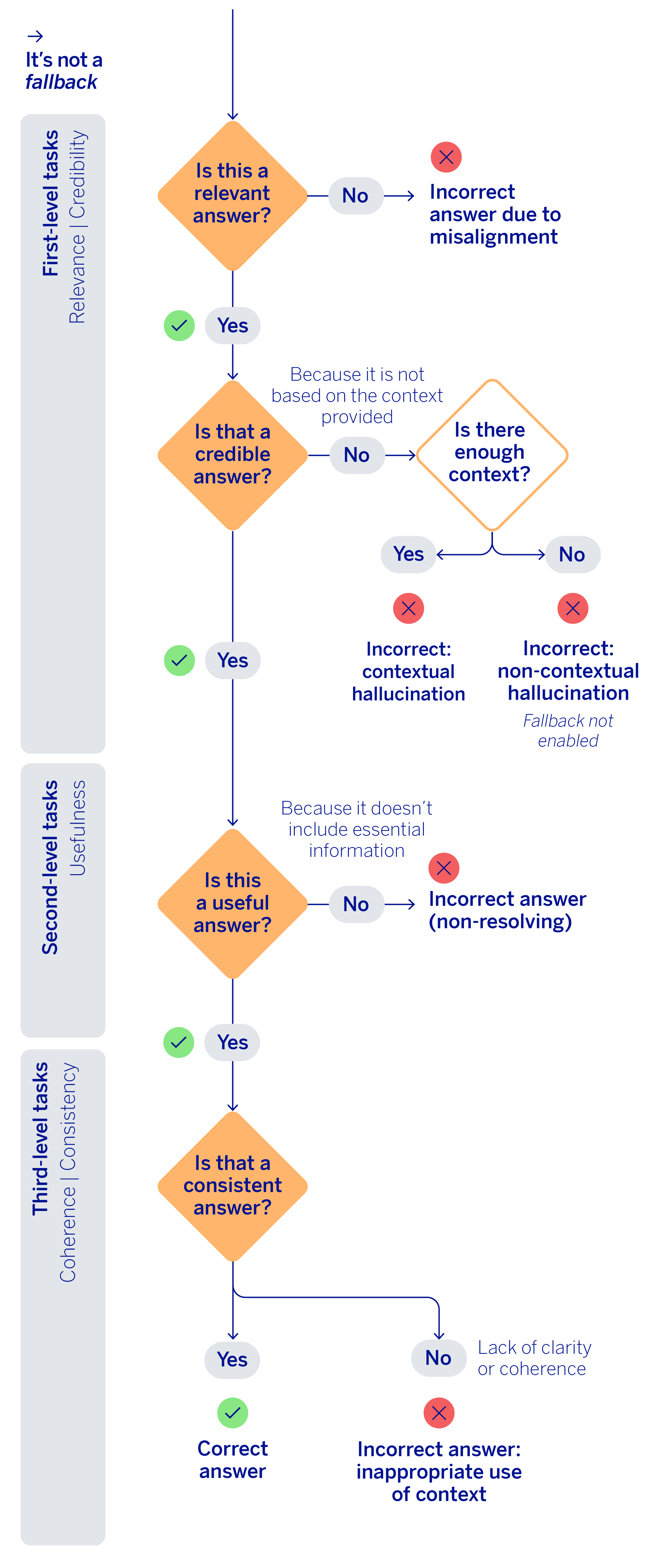
The interesting part of this approach is that it transforms the evaluation of a generative response into an error classification, which is far more useful and action-oriented than a simple aggregated metric. In other words, apart from detecting that something has failed, we can find out what kind of error occurred and where intervention is needed.
Evaluation of the routing agent: the challenge of correctly classifying customer intent
Blue’s classification or routing agent is evaluated using a series of specific metrics to determine the percentage of queries where the system correctly identifies customer intent among the available options. These are standard metrics for multiclass classification, such as the F1 score, recall and precision, both at the micro and macro levels.


Every time metrics are obtained from a test dataset, a confusion matrix is also generated, making it possible to see which operations are performing poorly. Furthermore, errors are distinguished by the prior intent filtering stage and the classification stage to determine whether an error is due to the expected intent not being retrieved during filtering or whether it was not selected by the routing agent, despite being available.
This helps the business team focus their efforts on improving the phrasing or descriptions of these operations. As this is a multi-class classification system, with a very high number of classes – over 150 – as well as ‘fallback,’ ‘clarify’ and ‘informative query’ tools, the confusion matrix is particularly useful to detect overlapping operations, redundancy in the definitions of the various domains and knowledge gaps.
Disambiguation rate
This measures the percentage of queries that lead the system to request more information from the customer to clarify their intent and avoid a classification error. This indicator reveals the system’s ability to detect ambiguity and act cautiously, prioritizing precision over a rapid classification.
For these cases, there are specific datasets with records already labeled as ‘clarify,’ which allows us to compare and evaluate whether the agent correctly disambiguates when needed, meaning whether it labels it as ‘clarify’ when appropriate. As we treat the clarification function as just another operation within the system, the metrics we use to evaluate whether the system uses this tool are the same ones we use to evaluate all other operations.
In addition, we also analyze the percentage of times that the customer’s correct intent was among the most likely options selected during the initial filtering. This value indicates whether the system could have delivered a correct classification in the interaction.
Fallback response rate
This measures the percentage of queries the system identifies as outside its scope. To evaluate it, we use previously designed datasets that allow us to analyze the efficiency of the guardrails, determining in which cases the system should classify a question as fallback.
There are different types of fallback responses depending on the message the system received – as ‘outside its scope,’ ‘insults’ or ‘do not answer.’ For each type, the system adjusts the generated responses. Instead of using static, predefined messages, the responses are built generatively, taking into account the user’s question. This maintains a natural tone and keeps the interactions from sounding robotic.
To evaluate generative fallback, we have created datasets that were labeled in collaboration with business colleagues and user experience experts, and we measure the percentage of accuracy of each type. Validation of the assistant’s generative responses is also conducted iteratively with business and design to refine both the form and content. These criteria serve to define LLMs-as-a-judge that monitor Blue’s response generation.
Evaluation of specialized agents: entity detection
Specialized agents are agents that are capable of executing tasks with customer guidance. To ensure the operations are carried out properly, we have specific metrics to evaluate agent performance when detecting entities. They are key elements, such as an IBAN, card number, Bizum amount or contact, that are essential to carry out a bank transaction. The purpose of the specialized agents is to correctly collect these entities throughout the conversation to eventually perform the transaction.
The result of this process conducted by the specialized agents is a data structure that makes it possible to distinguish between:
- A single transaction: Entities – necessary data or information – are grouped into a set.
- Multiple transactions of the same kind: Entities are separated into different sets, each set corresponding to an individual transaction.
To ensure that this data is captured accurately, we have defined metrics that are calculated for every message the agent and customer exchanged. They are aggregated into a dataset, only if the intent was correctly classified. Key metrics include the following:
- Precision of captured entities: This measures the accuracy of the compiled data when the conversation concludes. For a single transaction, it evaluates the proportion of correct entities out of the total. If the customer requests several transactions, it measures the number that were completed with all data recorded accurately.
- Precision of empty entities: This evaluates the entity fields that remain empty when engaging in conversation, ensuring that the AI agent does not attempt to gather the data prematurely.
- Entity hallucination: This identifies cases where the agent predicts more entities than are actually expected, indicating that it has fabricated or inferred information.
- End of conversation detection rate: This measures whether the agent correctly determines the exact moment when the conversation has ended and all necessary information has been collected to complete the transaction.
Some of the datasets we use to carry out this evaluation were generated by an LLM that simulates customer conversations, which we then label and review manually. Other datasets were directly labeled by the business and user experience teams.
Blue, a multi-agent AI assistant that continues evolving
Throughout a series of articles we have analyzed the different AI agents that make up Blue, BBVA’s virtual assistant. These agents, which are available 24/7, work together to provide appropriate, useful responses to customer requests. They are even able to perform simple bank transactions without the customer leaving the chat or having to navigate app menus.
All this is possible thanks to its multi-agent architecture, which enables the coordination of AI agents specialized in different tasks, thus ensuring that we offer accurate, personalized responses. We continue to work on refining and evolving the agent architecture that powers Blue, which will allow the assistant to handle more tasks, answer new kinds of queries and offer an even more seamless conversation experience.