
Evaluación de la IA en la era de los agentes: construyendo asistentes fiables y útiles
En artículos anteriores hemos analizado los diferentes tipos de agentes que forman parte de Blue, el asistente virtual basado en IA de BBVA. Sin embargo, hay un aspecto que no hemos abordado hasta ahora: su evaluación, ya sea desde el punto de vista del acierto en las decisiones que toman, como de la idoneidad y utilidad de las respuestas que generan cuando mantienen una conversación con el cliente.
Cuando trabajamos con sistemas basados en grandes modelos de lenguaje (LLM), que tienen la capacidad de generar respuestas nuevas e impredecibles, implementar métodos de evaluación y medir su comportamiento de forma sistémica es esencial para construir soluciones de IA robustas, fiables y verdaderamente útiles.
Estos mecanismos de evaluación nos permiten monitorizar cómo se comporta el sistema en condiciones reales, detectar desviaciones, identificar errores recurrentes y convertir ese aprendizaje en mejoras concretas para las siguientes iteraciones. A su vez, podemos mitigar uno de los riesgos más conocidos de la IA generativa: las alucinaciones, es decir, respuestas plausibles en apariencia pero que no están respaldadas por la realidad. Incluso cuando se emplean arquitecturas como RAG (Retrieval Augmented Generation), diseñadas para apoyarse en bases de conocimiento específicas y reducir ese riesgo, sigue siendo posible que el sistema produzca afirmaciones no sustentadas o incluso contradictorias con el contexto recuperado. Por eso, evaluar de forma continua resulta clave para detectar estos fallos y evitar que se traduzcan en respuestas incorrectas para el usuario.
En este artículo nos centraremos en algunos de los métodos de evaluación que hemos aplicado a los distintos tipos de agentes que forman parte de Blue: el agente informacional, el agente clasificador o de triaje y los agentes especializados. El objetivo es mostrar cómo traducimos la necesidad de evaluación de estos modelos a métricas concretas para medir mejor, aprender más deprisa y ofrecer respuestas cada vez más útiles.
Evaluación del agente informacional: LLM as a judge
El agente de Blue encargado de responder a consultas informativas está basado en una arquitectura de tipo RAG, esto es, una técnica a través de la cual aseguramos que el agente de IA responda a las preguntas del cliente tomando en consideración una base de conocimiento específica validada por equipos de BBVA. De esta forma, nos aseguramos de que Blue aporte información verificada y del ámbito bancario, sin renunciar a las capacidades propias de un LLM para conversar en lenguaje natural.
Para evaluar la calidad de la generación en un sistema RAG no basta con saber si una respuesta “parece correcta”. Lo realmente útil es entender qué decisión ha tomado el agente informacional, en qué punto del proceso se ha podido desviar y cómo debe interpretarse ese fallo.
Con esa idea hemos definido un mecanismo de “self-critique” (autoevaluación) apoyado en el paradigma “LLM as a judge”, donde otro LLM actúa como evaluador de la respuesta generada por el agente informacional. Esta heurística no se limita a asignar un veredicto o nota final sino que organiza la evaluación en una secuencia lógica de comprobaciones que permite distinguir entre, por un lado, preguntas que debían haberse resuelto; por otro, respuestas generadas que, en cambio, debían haber sido fallback (no ser respondidas al no disponer de suficiente contexto o estar fuera del ámbito bancario), y por último, respuestas que, aún siendo aparentemente válidas, no resultan verdaderamente útiles, diagnosticando también por qué no lo son asignándole un tipo de error.
La primera decisión de este mecanismo de evaluación requiere diferenciar los casos en los que el modelo ha producido un fallback de aquellos en los que se ha generado una respuesta sustantiva.
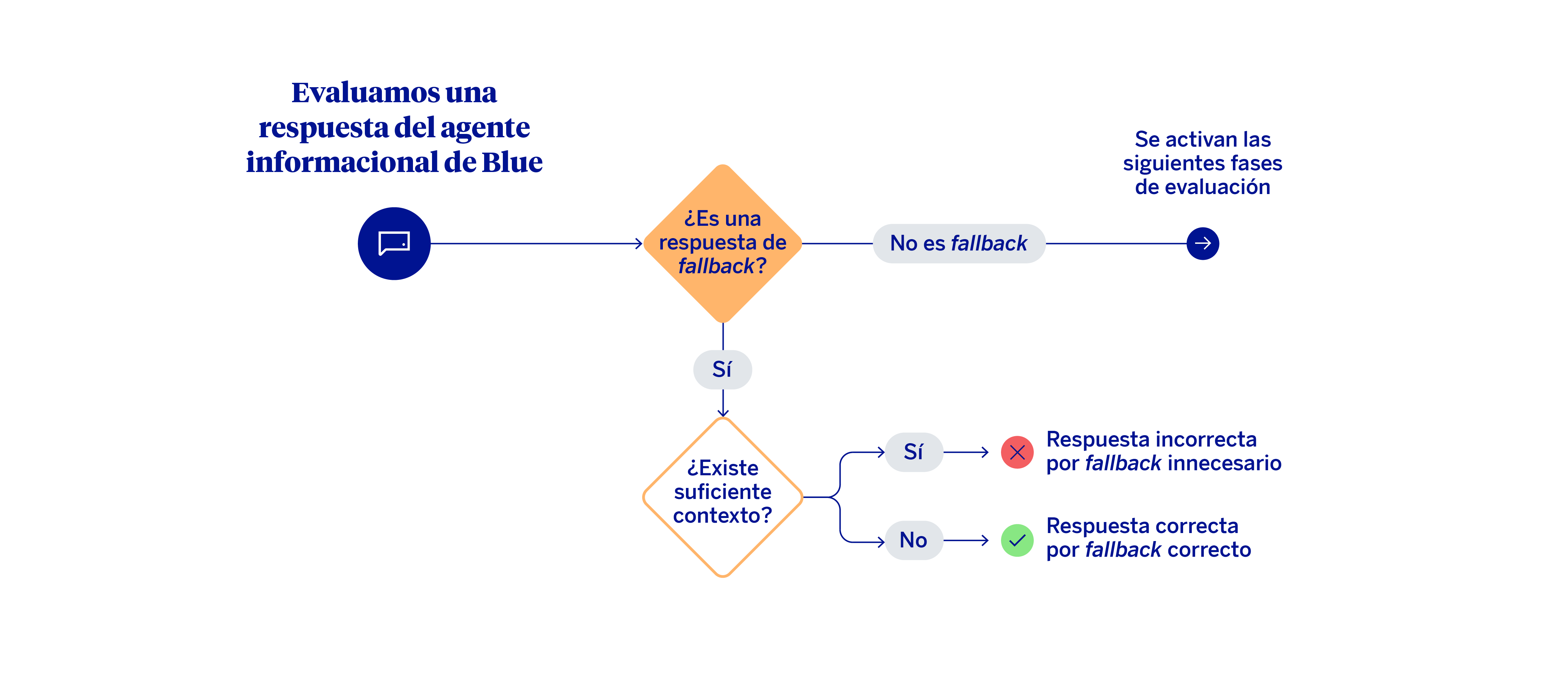
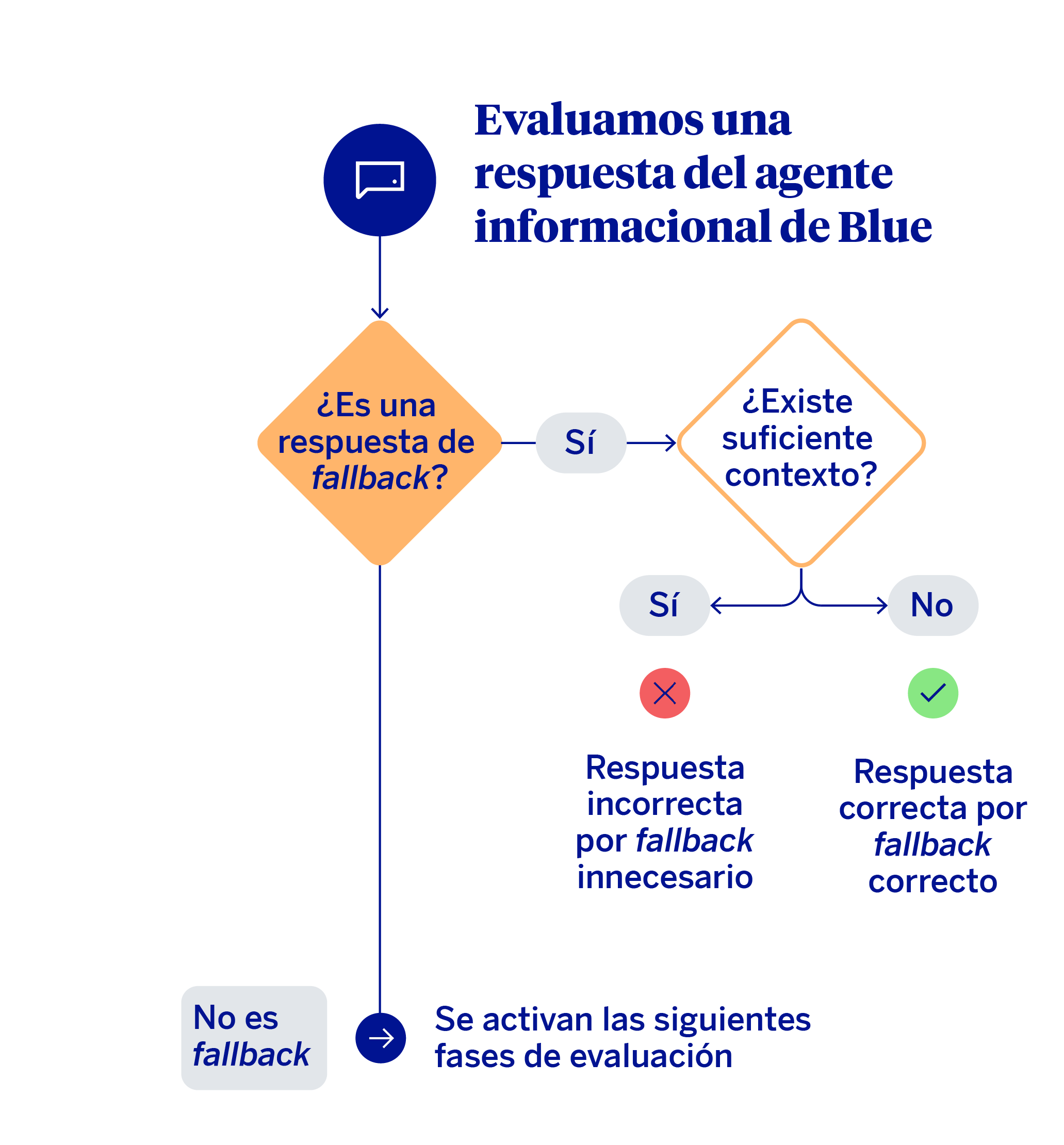
Cuando se produce fallback, la pregunta clave es si realmente el agente disponía o no de suficiente contexto (base documental) para responder. Si el contexto no era suficiente, el comportamiento puede considerarse correcto; por el contrario, si existía información relevante para responder y, aun así, el sistema optó por no hacerlo, entonces estamos ante un fallback innecesario. En estos casos, el sistema debería haber contestado a la consulta. Cuando no hay fallback, es decir, cuando el agente responde a la cuestión específica por la que pregunta un cliente, la heurística avanza hacia una evaluación por niveles.
El siguiente bloque revisa dos métricas básicas: relevancia y verosimilitud. La relevancia comprueba si la respuesta contesta realmente a lo que se pregunta y si mantiene una lógica temática coherente. La verosimilitud, por su parte, examina si la información se ha extraído de los documentos devueltos en el contexto o si por el contrario la respuesta inventa algún tipo de información, pudiendo ser obtenida de su conocimiento propio. Además, hace hincapié en las entidades sensibles o literales como, por ejemplo, instrucciones, importes, referencias o elementos que no deberían resumirse ni alterarse. Estas dos comprobaciones son las primeras porque actúan como filtro de entrada: si una respuesta no es relevante o introduce hechos inverosímiles, no tiene sentido seguir refinando la evaluación con criterios más sofisticados.
Superado ese primer nivel, el mecanismo evalúa una nueva métrica: la utilidad de la respuesta. Aquí ya no basta con que la respuesta sea relevante y verosímil; además debe ser capaz de resolver la necesidad del usuario utilizando la información presente en los contextos sin dejar detalles esenciales. Esta dimensión introduce una idea importante en la evaluación generativa de RAG: una respuesta puede no ser inventada y, sin embargo, seguir siendo deficiente si no aprovecha los fragmentos realmente cruciales para contestar de manera exacta a la pregunta.
Para terminar el flujo, la última validación que se realiza es respecto a la consistencia y coherencia de las respuestas. En esta fase final, se evalúa que la respuesta generada no contenga contradicciones o mezcle información de manera errónea. Si no se ha detectado este tipo de error tampoco en la respuesta —ni tampoco ninguno de los anteriores previamente—, entonces llegaríamos al final del proceso catalogando la respuesta generada por Blue como respuesta correcta.
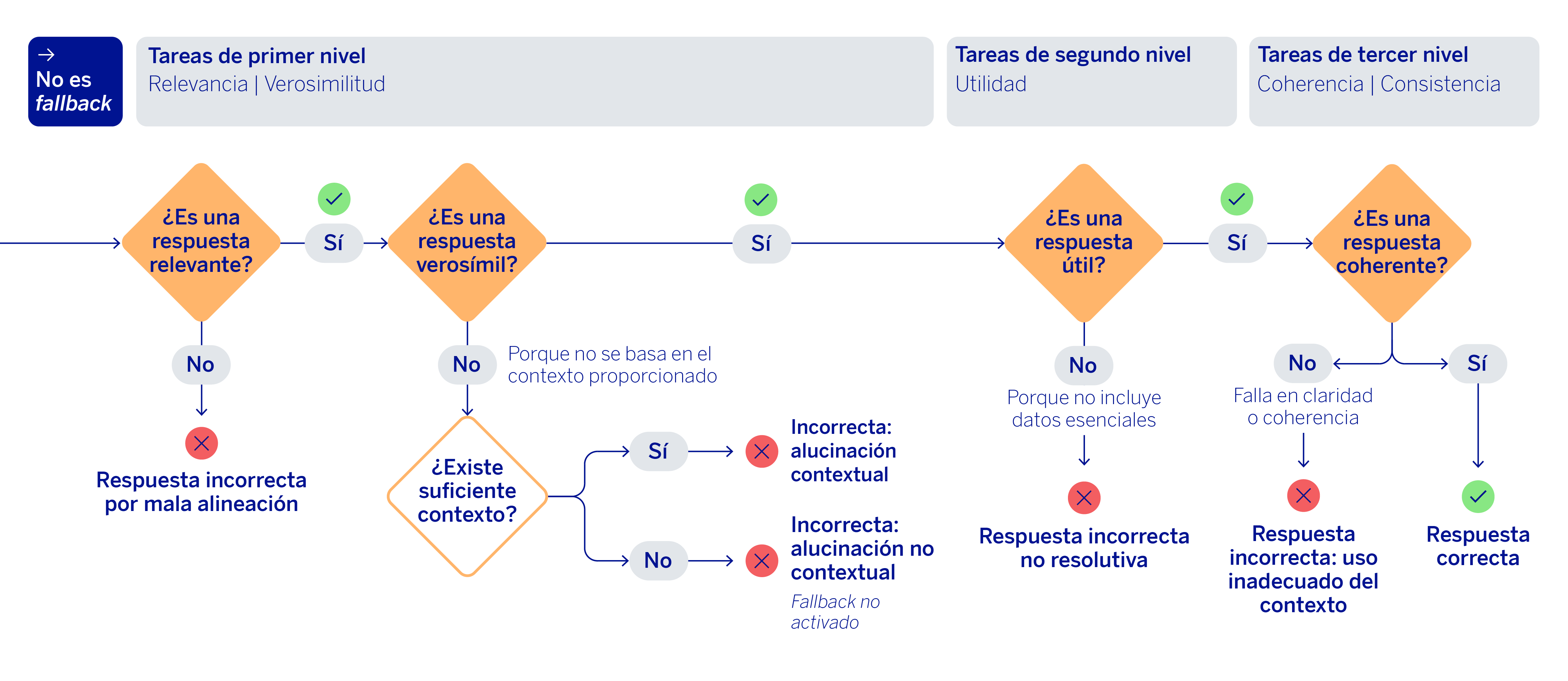
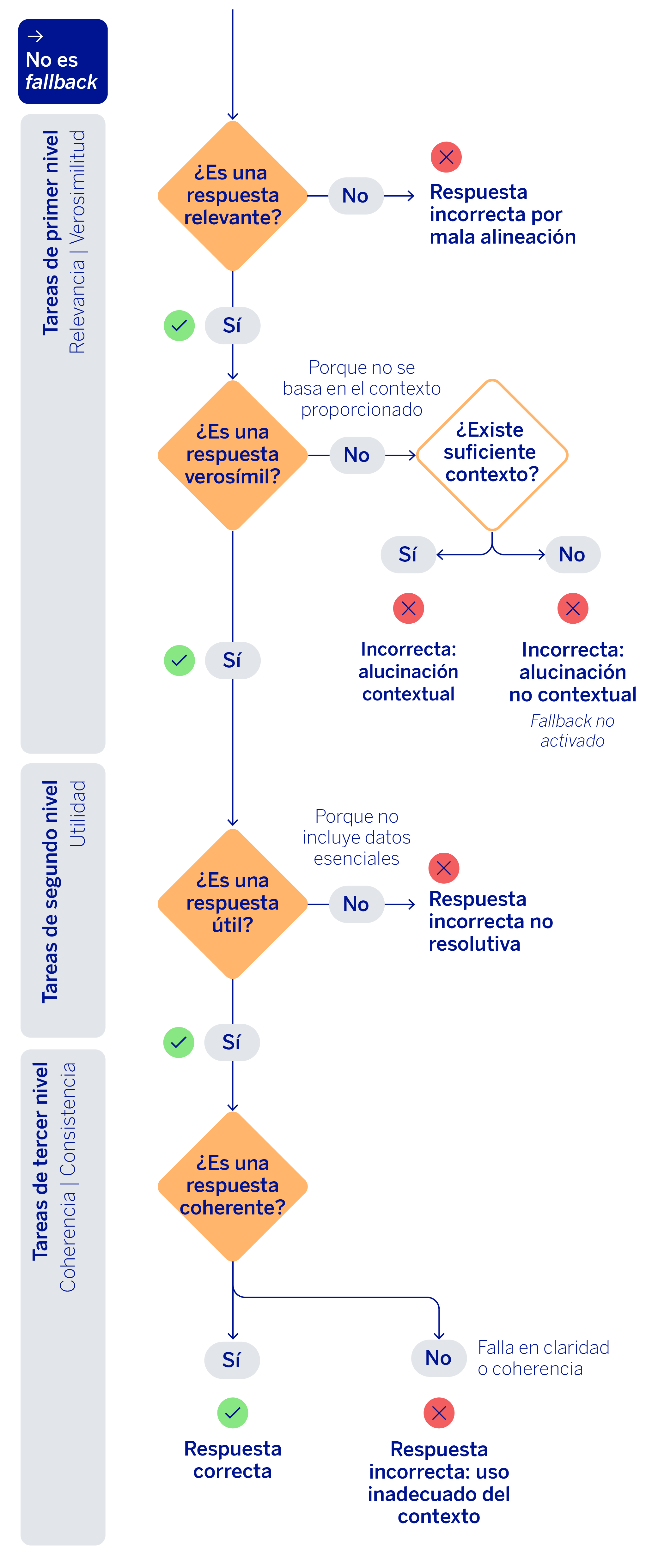
Lo interesante de este enfoque es que transforma la evaluación de una respuesta generativa en una clasificación de errores mucho más útil y accionable que una simple métrica agregada. Es decir, además de detectar que algo ha fallado, podemos saber qué tipo de fallo se ha producido y dónde conviene intervenir.
Evaluación del agente de triaje: el reto de clasificar correctamente la intención del cliente
El agente clasificador o de triaje de Blue se evalúa a través de un conjunto de métricas específicas que permiten medir el porcentaje de consultas donde el sistema identifica correctamente la intención del cliente entre las opciones disponibles. Se trata de métricas habituales para clasificación multiclase, como el ‘f1-score’, el ‘recall’ y la ‘precisión’; tanto micro como macro.


Cada vez que se obtienen métricas de un conjunto de datos o dataset de test, se genera también una matriz de confusión que permite ver qué operativas están funcionando peor. Además, se diferencian los errores entre la etapa previa de filtrado de intenciones y la etapa de clasificación, para saber si un error se debe a que la intención esperada no se ha obtenido en el filtrado o a que, pese a estar, no ha sido elegida por el agente de triaje.
Esto ayuda al equipo de negocio a poder dedicar esfuerzo a mejorar las frases o descripciones de dichas operativas. Como se trata de un sistema de clasificación multiclase, donde el número de clases es muy elevado –más de 150 operativas disponibles, además de herramientas como fallback, clarify, y consulta informativa –, la matriz de confusión es especialmente útil para detectar operativas que se solapan, redundancias en la definición de los distintos dominios y vacíos de conocimiento.
Tasa de desambiguación
Mide el porcentaje de consultas que, con el objetivo de evitar una clasificación errónea, llevan al sistema a solicitar más información al cliente para aclarar su intención. Este indicador muestra la habilidad del sistema para detectar ambigüedades y actuar con prudencia, priorizando la precisión sobre una clasificación rápida.
Para estos casos, existen datasets específicos con registros ya etiquetados como “clarify” que permiten comparar y evaluar si el agente desambigua correctamente cuando es necesario, es decir, si lo etiqueta como “clarify” cuando corresponde. Dado que tratamos la función de clarificar como una operativa más dentro del sistema, las métricas que aplicamos para evaluar si el sistema recurre a esta herramienta son las mismas que las utilizadas para evaluar el resto de operativas.
Además, en el proceso de desambiguación, se analiza el porcentaje de veces que la intención correcta del cliente estaba entre las opciones más probables seleccionadas por el filtrado previo. Este valor indica si el sistema podría haber logrado una clasificación correcta en una interacción posterior.
Tasa de respuestas de fallback
Mide el porcentaje de consultas que el sistema identifica como fuera de su ámbito de actuación. Para evaluarlo, utilizamos datasets previamente diseñados que permiten analizar la eficacia de las salvaguardas o guardrails, determinando en qué casos el sistema debe clasificar una pregunta como fallback.
Dentro de las respuestas de tipo fallback distinguimos diferentes tipologías, según el mensaje que recibe el sistema —como “fuera de alcance”, “insultos” o “no debe responder”—. Para cada una de estas tipologías, el sistema adapta las respuestas generadas: en lugar de utilizar mensajes estáticos o predefinidos, las respuestas se construyen de forma generativa teniendo en cuenta la pregunta del usuario, lo que permite mantener un tono natural y evitar interacciones percibidas como robóticas.
Para la evaluación del fallback generativo hemos generado datasets etiquetados conjuntamente con compañeros de negocio y expertos en experiencia de usuario, y medimos el porcentaje de acierto en cada uno de los tipos. La validación de las respuestas generativas que ofrece el asistente también se hace de forma iterativa con negocio y diseño hasta refinar la forma y el contenido de las mismas. Estos criterios sirven para definir LLMs-as-judges que monitorizan la generación de las respuestas en Blue.
Evaluación de los agentes especializados: detección de entidades
Los agentes especializados son aquellos capaces de ejecutar tareas guiados por el cliente. Para garantizar la correcta ejecución de las operativas, contamos con métricas específicas para evaluar el desempeño de los agentes a la hora de detectar entidades, que son los elementos clave —como el IBAN, el número de una tarjeta, el importe de un Bizum o un contacto de la agenda— imprescindibles para realizar una operativa bancaria. El objetivo de los agentes especializados es recopilar correctamente estas entidades a lo largo de la conversación para finalmente ejecutar la operativa.
El resultado de este proceso que llevan a cabo los agentes especializados es una estructura de datos que permite diferenciar entre:
- Una única operativa: Las entidades –datos o información necesaria– se agrupan en un solo conjunto.
- Múltiples operativas del mismo tipo: Las entidades se separan en diferentes conjuntos, correspondiendo cada uno a una operativa individual.
Para asegurar que estos datos se capturan con precisión, hemos definido métricas que se calculan por cada mensaje que mantiene el agente con el cliente y se agregan en un conjunto de datos, únicamente si la intención ha sido clasificada correctamente. Las métricas clave son las siguientes:
- Exactitud de entidades capturadas: Mide la corrección de los datos recopilados al momento en que la conversación concluye. Para una sola operativa, se evalúa la proporción de entidades correctas sobre el total. Si el cliente solicita varias operativas, se mide cuántas se completaron con todos sus datos de forma precisa.
- Exactitud de entidades vacías: Evalúa que los campos de entidades permanezcan vacíos durante el desarrollo de la conversación, asegurando que el agente de IA no intenta finalizar la recopilación de datos de forma prematura.
- Alucinación de entidades: Identifica los casos en los que el agente predice más entidades de las que realmente son esperadas, lo que indica que ha inventado o inferido información.
- Tasa de identificación del final de conversación: Mide si el agente determina correctamente el momento exacto en que la conversación ha finalizado y se ha recogido todo lo necesario para completar la operativa.
Algunos de los conjuntos de datos que utilizamos para llevar a cabo esta evaluación han sido generados mediante un LLM que simula conversaciones de cliente, y luego etiquetamos y revisamos manualmente. Otros datasets han sido etiquetados directamente por los equipos de negocio y experiencia de usuario.
Blue, un asistente de IA multi-agente que sigue evolucionando
A lo largo de diversos artículos, hemos analizado los diferentes agentes de IA que forman parte de Blue, el asistente virtual de BBVA. Estos agentes, disponibles 24/7, trabajan conjuntamente para ofrecer respuestas adecuadas y útiles a las demandas de los clientes, siendo capaces incluso de ejecutar operativas bancarias sencillas sin necesidad de que el cliente salga del chat ni tenga que navegar por los menús de la aplicación móvil.
Todo esto es posible gracias a su arquitectura multi-agente, que permite coordinar agentes de IA especializados en diferentes tareas, y de esta forma asegurar que ofrecemos respuestas precisas y personalizadas. Actualmente, seguimos trabajando en el refinamiento y evolución de la arquitectura agéntica que hace posible Blue, y que nos permitirá que el asistente sea capaz de llevar a cabo más tareas, contestar a nuevos tipos de consultas y ofrecer una experiencia conversacional aún más fluida.