
Análisis de la actividad comercial en un barrio: un ejercicio práctico con mercury-graph
Mercury-graph es una librería open-source en Python diseñada para facilitar la construcción, exploración y modelado de grafos (redes de datos). Su objetivo es permitir a los analistas y científicos de datos trabajar con estructuras de grafos de manera eficiente, proporcionando herramientas para la visualización interactiva, la detección de comunidades y la aplicación de técnicas avanzadas como los embeddings y las matrices de transición.
Lo que hace a mercury-graph especialmente útil es su capacidad para transformar datos estructurados en insights accionables mediante el modelado de relaciones implícitas. Al aprovechar la estructura del grafo, se pueden descubrir patrones de conectividad, similitudes entre nodos y comportamientos emergentes dentro de la red. Esto resulta clave en una variedad de aplicaciones, entre ellas el análisis de relaciones comerciales y de mercado.
En este artículo, exploraremos cómo utilizar mercury-graph en un caso de uso práctico: el análisis de la actividad comercial en un barrio. A través del modelado de comercios como nodos y las relaciones entre ellos como conexiones en un grafo, veremos cómo extraer información relevante que puede ser utilizada para entender patrones de consumo, detectar afinidades entre negocios y mejorar estrategias de recomendación y expansión comercial.
Contexto del problema: Explorando los comercios en un barrio urbano
Las ciudades están llenas de pequeños ecosistemas comerciales. Los patrones de consumo y la relación entre comercios que se generan pueden ser analizados a través de técnicas de grafos, permitiéndonos comprender mejor cómo se estructuran estos entornos y cómo evolucionan con el tiempo.
Uno de los aspectos clave de este análisis es la interconectividad de los comercios dentro de un barrio. Los clientes no suelen visitar tiendas de manera aislada, sino que realizan recorridos por distintos establecimientos según sus necesidades, preferencias y hábitos de consumo.
En el siguiente ejercicio, cargaremos los datos, construiremos un grafo, lo visualizaremos y aplicaremos técnicas avanzadas como los “embeddings”, que permiten representar relaciones en un espacio matemático para encontrar similitudes entre comercios.
Explicamos el dataset
El dataset que emplearemos como ejemplo, “Comercios de Chamberí”, representa la actividad comercial de este emblemático barrio madrileño mediante una estructura de grafo. Cada nodo es un comercio con atributos, nombre, sector, precio medio y facturación. Las aristas representan la relación entre negocios según el número de clientes que comparten.
Al analizar esta red, podemos responder preguntas como: ¿Qué negocios tienen una clientela similar? ¿Qué tipo de comercio puede beneficiarse de una colaboración con otro? ¿Cuáles son los puntos neurálgicos del comercio en el barrio?
Se trata de un dataset generado con IA, diseñado con unos pocos comercios para ilustrar el uso de la librería, manteniendo una estructura realista basada en relaciones comerciales.
Instalamos la librería
Para seguir este hands-on, recomendamos utilizar Jupyter Lab, ya que nos permitirá visualizar los grafos de manera interactiva. Si aún no lo tienes instalado, puedes hacerlo con:
pip install jupyterlab anywidget
Una vez instalado, puedes iniciarlo con:
jupyter lab
Además, instalaremos la librería mercury-graph, que utilizaremos en los ejemplos. Para ejecutar cada fragmento de código en este tutorial, crea un nuevo notebook en Jupyter Lab y ejecuta la siguiente celda:
!pip install mercury-graph
Cargamos los datos
El siguiente paso es cargar el dataset “Comercios de Chamberí”, que está disponible en formato CSV. Utilizaremos pandas, una librería en Python ampliamente utilizada para manipulación de datos.
El dataset se compone de:
- Nodos: representan los comercios e incluyen información como nombre, sector, precio medio y facturación.
- Aristas: representan las relaciones entre comercios, es decir, cuántos clientes han visitado ambos establecimientos.
Podemos cargar los datos directamente desde los archivos CSV alojados en el repositorio del proyecto:
import pandas as pd
nodes = pd.read_csv('https://raw.githubusercontent.com/BBVA/mercury-graph/refs/heads/master/tutorials/data/chamberi_nodos.csv', sep = '\t')
edges = pd.read_csv('https://raw.githubusercontent.com/BBVA/mercury-graph/refs/heads/master/tutorials/data/chamberi_aristas.csv', sep = '\t')
Construimos el grafo
Con los datos cargados, podemos construir el grafo utilizando mercury-graph en una sola línea.
import mercury.graph as mg
G = mg.core.Graph(edges, keys = {'directed': False}, nodes = nodes)En este caso:
- edges define las conexiones entre los nodos, indicando cuántos clientes comparten dos comercios.
- nodes, que es un argumento opcional, contiene la información detallada de cada comercio.
- keys es un diccionario de nombres de columna, en este caso ya son los que espera mercury-graph.
Además, {‘directed’: False} especifica que el grafo es no dirigido, es decir, la relación entre los comercios es bidireccional.
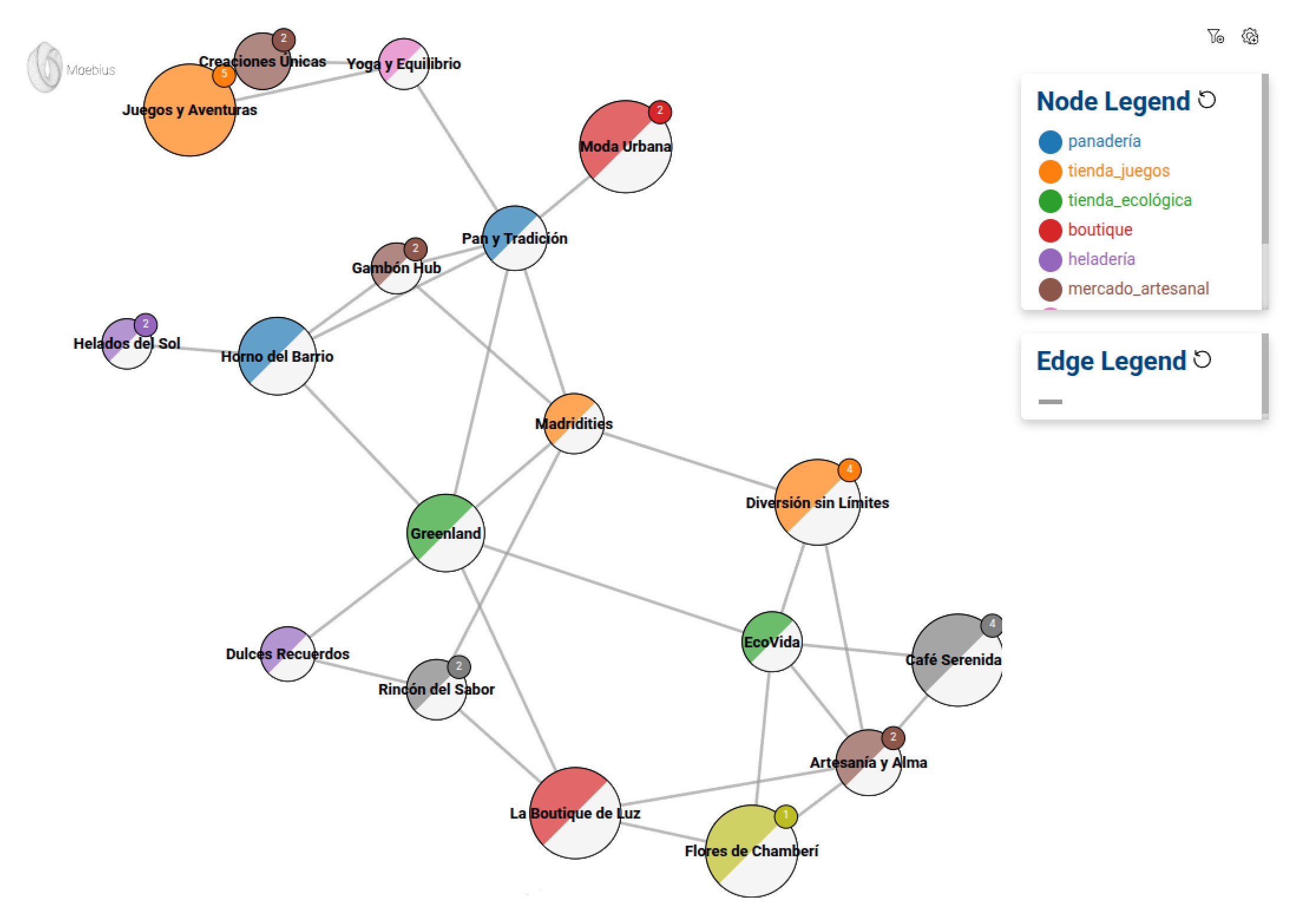
Lo exploramos visualmente
Para visualizar el grafo, utilizaremos Moebius, el módulo de visualización de mercury-graph. Crearemos una configuración básica que nos permitirá inspeccionar la red de comercios.
M = mg.viz.Moebius(G)
node_conf = M.node_or_edge_config(text_is = 'id', color_is = 'actividad', size_is = 'facturación', size_range = [20000, 100000])
edge_conf = M.node_or_edge_config(text_is = 'weight')
M.show('Greenland', 2, node_conf, edge_conf)- Moebius(G) inicializa la visualización sobre el grafo.
- node_or_edge_config define cómo se muestran los nodos y las aristas.
- text_is=’id’: muestra el identificador de cada nodo.
- color_is=’actividad’: asigna un color distinto según la actividad del comercio.
- size_is=’facturación’: ajusta el tamaño del nodo según su facturación, con valores entre 20.000 y 100.000.
- M.show(‘Greenland’, 2, node_conf, edge_conf) permite explorar el grafo partiendo desde el nodo Greenland y expandiéndose hasta sus vecinos en dos niveles.
Con esto, obtenemos una visualización interactiva del grafo y podemos empezar a analizar relaciones comerciales. Podemos jugar con ella para familiarizarnos con el dataset y la librería.
Las aristas vistas como movimientos de clientes
Hasta ahora, hemos representado la relación entre comercios usando un grafo donde las aristas indican cuántos clientes han visitado ambos establecimientos. Sin embargo, estos datos solo reflejan una pequeña parte de la realidad: sabemos de algunos clientes que comparten comercios, pero no de todos. ¿Cómo podemos estimar relaciones adicionales con la información limitada que tenemos?
Aquí es donde aplicamos una idea clave: modelar los movimientos de los clientes como una cadena de Markov. Esto significa que podemos imaginar que un cliente se mueve de un comercio a otro con una cierta probabilidad basada en los datos observados. En otras palabras, si dos tiendas comparten clientes, es probable que un cliente de la primera tienda también termine visitando la segunda.
Para hacerlo, transformamos nuestro grafo en una matriz de transición, que nos dice con qué probabilidad un cliente pasará de un comercio a otro en un solo paso. Pero, lo interesante es que podemos extender esta idea: si aplicamos repetidamente la transición (siguiendo la lógica de los amigos de mis amigos son mis amigos), podemos descubrir relaciones indirectas entre comercios que inicialmente no parecían conectados.
¿Por qué esto es útil? Porque nos ayuda a regularizar el dataset, es decir, a suavizar la información limitada que tenemos y hacer mejores inferencias. Aunque solo observamos directamente unos pocos movimientos de clientes, esta técnica nos permite extender el conocimiento y estimar conexiones que serían evidentes si tuviéramos una visión más completa en el tiempo y más datos de compras.
Para convertir nuestro grafo en una matriz de transición y empezar a explorar estos movimientos de clientes, usamos mercury-graph de la siguiente manera:
T = mg.ml.Transition().fit(G)
T.to_pandas()Esto nos da una representación del flujo de clientes entre los comercios, que podemos usar para simular recorridos y analizar la proximidad entre tiendas más allá de los datos originales.
Simulación de recorridos de clientes
En el paso anterior, hemos construido una matriz de transición, que nos indica la probabilidad de que un cliente pase de un comercio a otro en un solo paso. Pero, ¿qué pasa si queremos analizar los recorridos de los clientes después de varios movimientos? Es decir, no solo dónde podrían ir después de visitar un comercio, sino también dónde podrían terminar después de varios pasos intermedios.
Matemáticamente, esto equivale a elevar la matriz de transición a una potencia. Por ejemplo, si multiplicamos la matriz por sí misma 10 veces (es decir, la elevamos a la potencia 10), obtenemos una nueva matriz que nos dice qué conexiones existen tras 10 pasos de movimiento del cliente.
¿Por qué esto es útil? Porque nos permite descubrir nuevas relaciones entre comercios que no eran evidentes en los datos originales. Si, después de 10 pasos, hay una alta probabilidad de que un cliente termine en una tienda con la que inicialmente no tenía conexión directa, podríamos considerar que esos comercios tienen una relación fuerte y agregar una nueva arista al grafo.
Esta sería una forma de enriquecer el dataset, simulando cómo se moverían los clientes si tuviéramos más datos. Con mercury-graph, podemos calcular esta simulación con:
T.to_pandas(10)Esto nos devuelve una matriz con las probabilidades de transición tras 10 pasos, permitiéndonos identificar nuevas conexiones relevantes entre comercios. Estas conexiones podrían ser utilizadas para mejorar recomendaciones, analizar patrones de consumo o incluso rediseñar estrategias comerciales basadas en la afinidad entre tiendas.
Embeddings
Hasta ahora, hemos explorado las relaciones entre los comercios usando grafos y matrices de transición. Ahora vamos a introducir otra herramienta poderosa: los embeddings.
Un embedding es una representación matemática de cada nodo (en este caso, cada comercio) en forma de un vector en un espacio de muchas dimensiones. La idea es que estos vectores reflejen la estructura del grafo: comercios que están conectados o que tienen recorridos similares deberían tener embeddings similares.
¿Cómo se calculan los embeddings?
Inicialmente, cada comercio recibe un vector de números aleatorio, sin ninguna información útil. Luego, el algoritmo de embeddings entrena estos vectores simulando caminos aleatorios por el grafo. Durante este entrenamiento:
- Si dos comercios aparecen frecuentemente en los mismos caminos, sus embeddings se acercan.
- Si dos comercios rara vez se encuentran en los mismos caminos, sus embeddings se alejan.
Con el tiempo, estos vectores dejan de ser aleatorios y empiezan a reflejar la estructura del grafo: capturan relaciones que pueden no ser evidentes a simple vista.
El verdadero poder de los embeddings está en cómo podemos utilizarlos:
- Similitud: podemos calcular qué comercios son más parecidos basándonos en la distancia entre sus embeddings.
- Búsqueda de patrones: los comercios con embeddings similares pueden compartir comportamientos o públicos, aunque no estén directamente conectados en el grafo.
- Relaciones aritméticas: en algunos casos, incluso podemos hacer operaciones con embeddings para descubrir nuevas relaciones.
Con mercury-graph, podemos calcular los embeddings de los comercios así:
E = mg.embeddings.GraphEmbedding(dimension = 50, n_jumps = 1000).fit(G)
E.embedding().as_numpy()Aquí, dimension=50 significa que cada comercio será representado con un vector de 50 números, y n_jumps=1000 indica que simularemos 1000 recorridos aleatorios por el grafo para entrenar los embeddings.
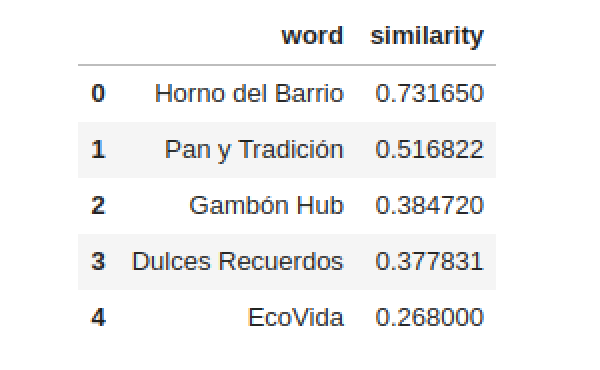
Una vez calculados, podemos usarlos para encontrar comercios similares:
E.get_most_similar_nodes('Greenland') Esto nos devolverá una lista de los comercios más parecidos a “Greenland” según la estructura del grafo, lo que nos permite hacer recomendaciones, detectar comunidades ocultas y analizar patrones de consumo.
Un poco más allá: detección de comunidades con Louvain
Además de analizar similitudes entre comercios, podríamos dar un paso más y detectar comunidades dentro del grafo. Un enfoque popular para esto es el algoritmo de Louvain, que agrupa nodos en función de la densidad de sus conexiones internas comparadas con las externas.
Este método es útil para identificar grupos de comercios con alta afinidad entre sí, lo que podría ayudar en estrategias de segmentación o análisis de mercado. Sin embargo, su implementación requiere manejar datasets más grandes y utilizar herramientas como Spark, PySpark y GraphFrames, lo que excede el objetivo de este hands-on.
Si quieres explorarlo en otro contexto, en mercury-graph se utilizaría con una sola línea de código:
L = mg.ml.LouvainCommunities().fit(G)Conclusión
En este hands-on, hemos visto cómo los grafos pueden ayudarnos a descubrir patrones en datos comerciales, más allá de lo que sería posible con enfoques tradicionales basados en tablas.
Usando mercury-graph, hemos podido:
- Construir y visualizar una red de comercios basada en clientes compartidos.
- Explorar cómo los clientes pueden moverse entre establecimientos utilizando una matriz de transición.
- Usar este modelo para estimar nuevas relaciones entre comercios más allá de los datos observados.
- Aplicar embeddings para representar la estructura del grafo en un espacio matemático y encontrar similitudes entre nodos.
Además, mencionamos cómo técnicas avanzadas como Louvain podrían ayudarnos a detectar comunidades dentro del grafo en análisis más amplios.
Este ejercicio ha sido solo una introducción a todo lo que se puede hacer con mercury-graph. En problemas reales, podríamos aplicar estas técnicas para optimizar estrategias comerciales, mejorar recomendaciones o entender mejor la dinámica de un mercado. El análisis de grafos es una herramienta poderosa, y con mercury-graph, su implementación en Python es más accesible que nunca.