
Cómo etiquetar datos de forma más rápida utilizando Active Learning
Con la inteligencia artificial somos capaces de traducir textos automáticamente, buscar una imagen similar en Google o incluso dibujar; pero hasta que estos sistemas sean capaces de aprender cosas por sí mismos, seguirán dependiendo de los humanos para que preparen, limpien y etiqueten los datos que los alimentan. Y es que cuando recurrimos a un sistema de inteligencia artificial para automatizar una tarea, por ejemplo la de traducir un texto, es porque un equipo de humanos lo han alimentado con miles o millones de entradas (frases en el idioma original) y salidas (frases en el idioma deseado) verificadas, proceso que se conoce como etiquetado. Esa modalidad de la inteligencia artificial, que funciona “imitando” el proceso mediante el cual entra un dato conocido y sale su etiqueta, es lo que conocemos como aprendizaje supervisado (supervised learning).
En BBVA AI Factory diseñamos productos de datos basados en modelos de aprendizaje automático (machine learning) con el objetivo de automatizar tareas que aporten valor a los usuarios, como clasificar movimientos bancarios o detectar si un mensaje de un cliente es urgente. Para estas tareas, nos encontramos con el reto de tener que preparar y etiquetar conjuntos de datos.
Tanto si las etiquetas se pueden obtener de alguna manera inteligente, como si -en el peor de los casos-, se tienen que introducir manualmente, la obtención de un conjunto de datos etiquetado de suficiente calidad, o de suficiente tamaño, es uno de los cuellos de botella de los sistemas de aprendizaje automático, hasta el punto de que a veces estamos ayudando a etiquetar datos sin saberlo1.
Por estos motivos, hace unos meses lanzamos un proyecto para prototipar un sistema de anotación rápida. El ingrediente para conseguirlo es una técnica estadística llamada active learning.
|
|
Este prototipo es el primero desarrollado dentro del Programa X, una iniciativa interna de exploración e innovación con datos premiada por Fast Company, que amplía su reconocimiento a BBVA AI Factory como uno de los 100 mejores lugares de trabajo del mundo para innovadores y la primera posición en la categoría de pequeñas compañías (menos de 100 empleados). Más información → |
|---|
Prototipando active learning
Active learning es una técnica automática que permite a una persona que está etiquetando datos saber cuáles son los que tienen las etiquetas más valiosas, y por tanto, los que más “vale la pena” etiquetar. Es una técnica que se remonta casi a los principios del aprendizaje automático y que ha demostrado en estudios ser capaz de reducir la cantidad de datos a anotar. Sin embargo, hasta hace poco la mayoría de la documentación se reducía a estudios académicos y había pocos ejemplos documentados del estado de la práctica2 o de sistemas industriales.
Por qué active learning funciona
Para explicar mejor por qué active learning funciona, utilizaremos un ejemplo sencillo. Imaginemos que tenemos muchas cajas cerradas en el suelo de una habitación. Por fuera, estas cajas son exactamente iguales, pero por dentro están pintadas de un color determinado. Nuestra misión es saber de qué color están pintadas las cajas por dentro y anotar esta información. Es decir, disponemos de un conjunto de datos (las cajas) y queremos anotar sus características o información (color). La manera más sencilla y directa de hacerlo es abrir las cajas una a una y observar de qué color están pintadas por dentro.
En el ejemplo anterior podemos abrir fácilmente todas las cajas y anotar sus etiquetas, porque solo hay dos atributos (su posición en los ejes x e y) y un conjunto limitado de cajas. Pero la realidad es que en nuestro día a día nos enfrentamos a conjuntos de datos más complejos, y necesitamos una forma de tener un buen desempeño sin necesidad de invertir grandes esfuerzos en el etiquetado. Volviendo al ejemplo de las cajas, cuando tenemos muchas para abrir, el proceso nos puede llevar más tiempo del esperado y quizás tenemos que recurrir a varios amigos para que nos ayuden en la tarea. En ese momento nos surge la pregunta: ¿sería posible conocer el color de la mayoría de las cajas más rápidamente y sin necesidad de abrirlas todas?
En nuestro caso, sabemos que el orden en el que están situadas las cajas no es aleatorio, sino que su posición está relacionada con el color que tienen en su interior. Intuimos, por tanto, que al final deberíamos ser capaces de distinguir diferentes zonas de cajas según su color, aunque no podemos determinarlo antes de empezar a abrirlas. Así pues, utilizando aprendizaje supervisado y la información de la posición de las cajas, vamos a intentar descubrir sus colores de forma más eficaz. El objetivo del aprendizaje supervisado es anticipar dónde está la separación entre la zona de cajas azules y la zona de cajas rojas. Aunque tenemos muy pocas cajas etiquetadas, pedimos a un modelo clasificador de aprendizaje automático (random forest) que intente separar las dos regiones. El modelo efectúa una primera separación entre ambas zonas, prediciendo qué cajas serían de cada color. Para mejorar la fiabilidad y las predicciones del modelo, tenemos que abrir algunas cajas más.
La ventaja de utilizar active learning es que el propio modelo nos propone qué caja (dato a etiquetar) deberíamos abrir a continuación. Es decir, en lugar de escoger de forma aleatoria el siguiente dato a etiquetar, utilizando esta técnica sabemos qué datos nos aportan más información de cara a mejorar la predicción del modelo. De esta forma, las nuevas cajas que abrimos y etiquetamos suelen situarse en la frontera entre las zonas de diferente color, ya que es aquí donde el modelo (y nosotros) estamos menos seguros del resultado.
A medida que vamos abriendo más cajas, observamos que la predicción del modelo no cambia, estabilizándose en dos zonas claramente diferenciadas; una zona de cajas rojas y otra de cajas azules. Ahora podemos confiar más en la predicción del modelo. Este hecho también nos indica que hemos etiquetado suficientes datos. Aunque esto no indica que conocemos el color real de todas las cajas -sólo podemos afirmar esto para las cajas que hemos abierto-, siguiendo este método sí podemos llegar al mismo nivel de confianza en la predicción de forma más rápida y con mucho menos esfuerzo, esto es, etiquetando muchos menos datos.
El beneficio de active learning
En aplicaciones reales de aprendizaje autónomo, el objetivo es descubrir dónde está la frontera entre las categorías, como hemos visto en el ejemplo anterior. Aplicando active learning podemos hacerlo de forma eficaz porque está constantemente verificando los puntos cercanos a la frontera y corrigiendo el modelo. Es fácil observar cómo, si simplemente hubiésemos levantado las cajas del ejemplo de forma aleatoria, o por ejemplo de izquierda a derecha y de arriba a abajo, hubiésemos tardado más movimientos en descubrir la frontera entre las regiones azul y roja. Por eso, el uso de algoritmos de active learning puede repercutir en un ahorro de tiempo a la hora de etiquetar datos. Esta ganancia se puede representar de manera teórica en la siguiente figura.
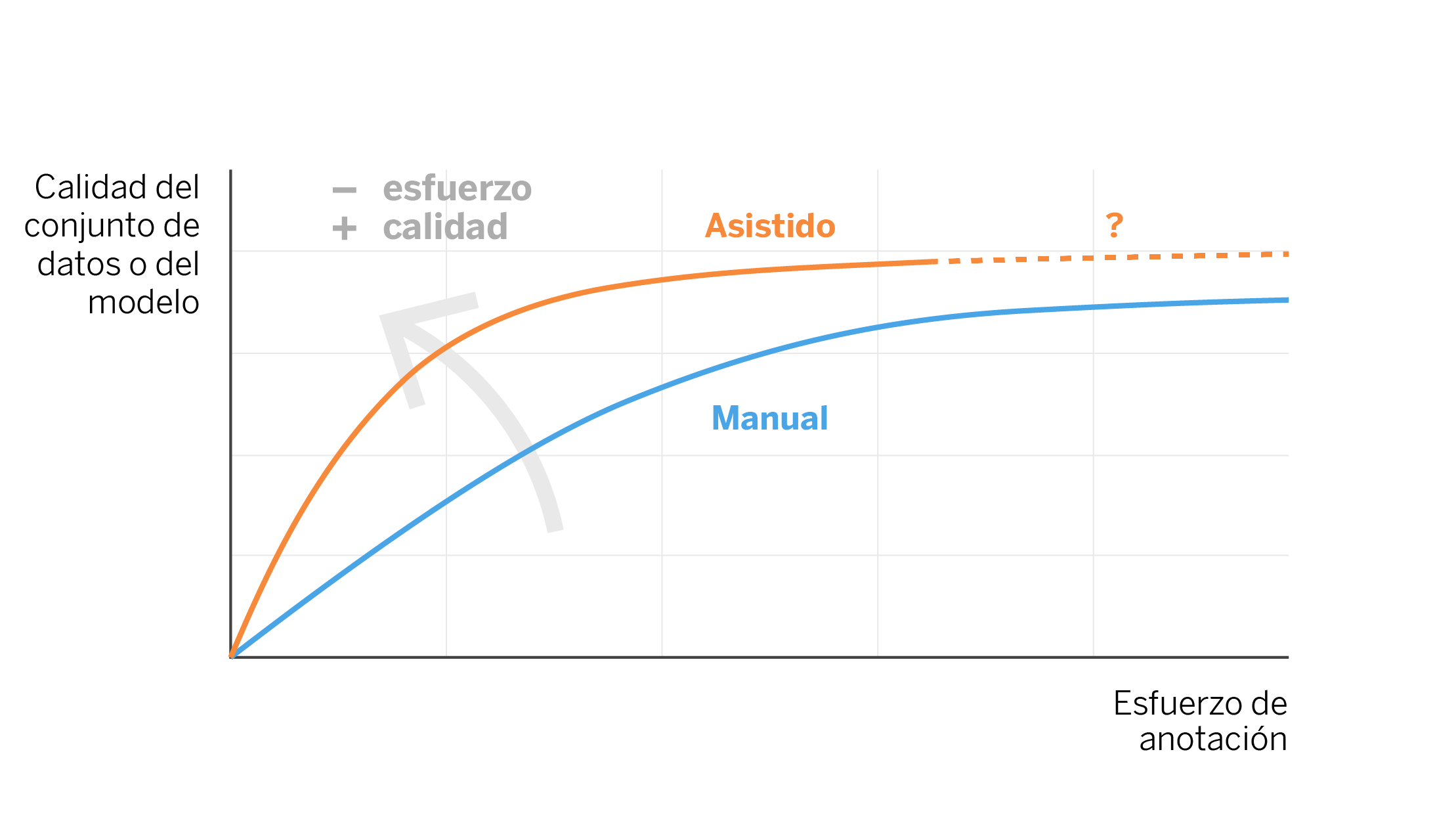
Del ejemplo a la realidad
Aunque la animación anterior es un ejemplo simplificado, el proceso de active learning se puede usar en aplicaciones de clasificación reales, por ejemplo clasificar una conversación. Una diferencia es que en dichas aplicaciones no tenemos dos atributos (posición horizontal y vertical) sino cientos o miles. Por ejemplo, en muchas tareas de clasificación es habitual usar un atributo por cada palabra, que toma como valor el número de veces que ha aparecido en un texto.
Otra diferencia es el número de categorías. Por ejemplo, una conversación se puede clasificar en decenas de categorías, correspondientes a las distintas acciones que puede querer realizar el usuario. Y otra dificultad podría ser que estas categorías fuesen no separables. Esto significaría que, a diferencia del ejemplo anterior donde había una frontera clara entre las regiones azul y roja, las muestras de diferentes categorías se solaparan en el espacio de atributos.
Vamos a aplicar el mismo mecanismo de active learning del ejemplo -que corresponde a una variante básica llamada uncertainty sampling– a un conjunto de datos más complejo. En concreto, la base de datos pública “Banking intents”, que consiste en mensajes cortos de usuarios solicitando realizar una de las 77 acciones posibles en una aplicación de banca. Entrenamos un primer modelo con 2000 muestras etiquetadas, y a partir de aquí realizamos iteraciones de active learning para seguir etiquetando. En cada repetición, solicitamos que se etiqueten 10 conversaciones nuevas, siguiendo el criterio de uncertainty sampling, es decir, aquellas en las que el modelo tiene más dudas. Con las etiquetas disponibles, simulamos cómo iría mejorando el modelo con cada iteración. Observamos cómo esta gráfica coincide con la gráfica teórica que hemos mostrado anteriormente, manifestando una mejora de la productividad en la fase del etiquetado.
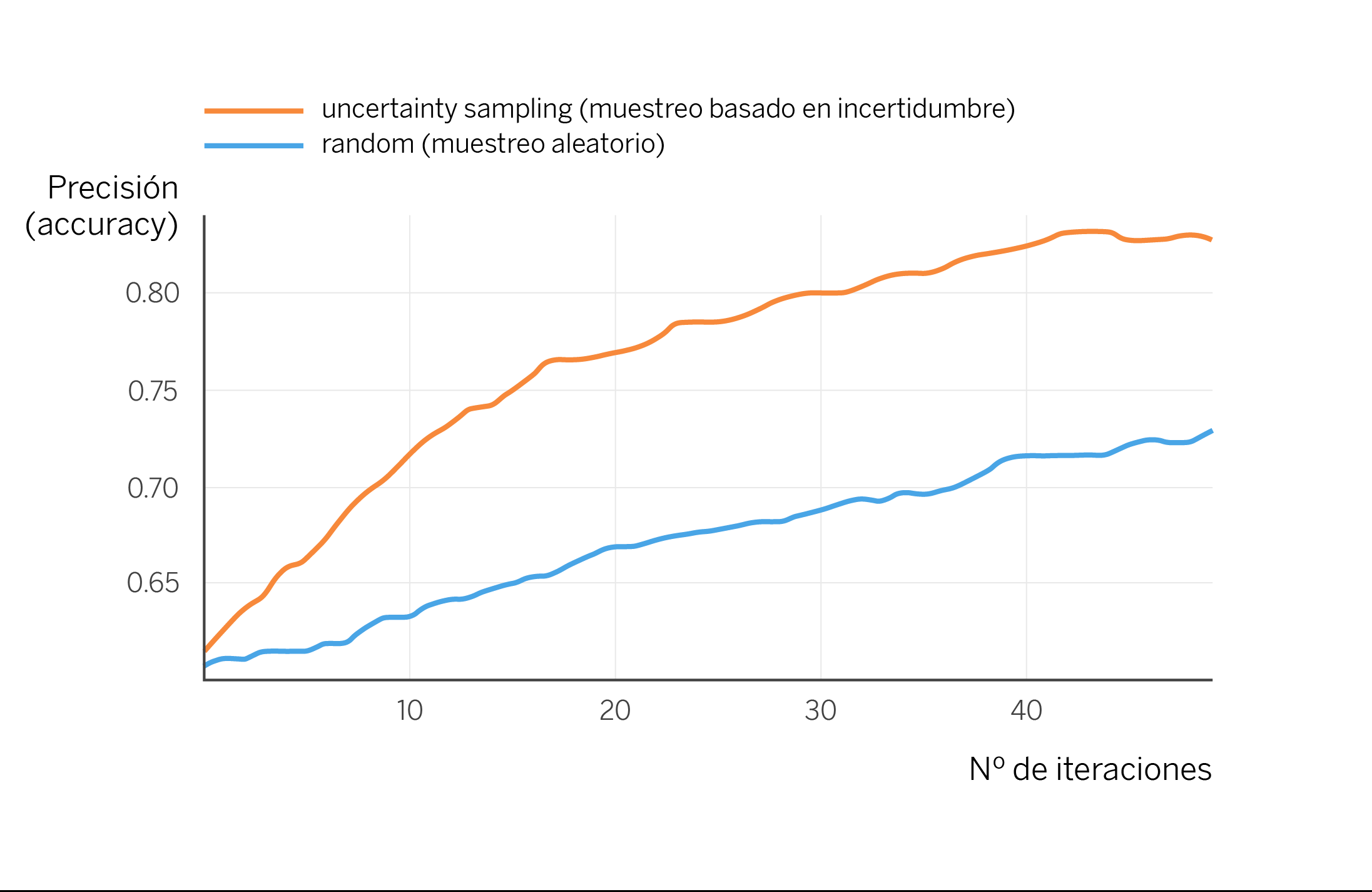
Más allá del ejemplo sencillo
El concepto de active learning lleva décadas demostrando que es viable. Aun así, la variante que hemos explicado es la más básica y no es extraño que en una aplicación industrial requiera más complejidad. A nivel académico, se han diseñado muchos otros mecanismos más complejos que el uncertainty sampling, por ejemplo para adaptarlos a arquitecturas muy recientes como los transformers 3. También existen ciertas precauciones a la hora de desplegar estos sistemas de manera industrial y evitar sesgos 4.
Un claro problema de guiar el proceso de etiquetado exclusivamente con técnicas de active learning mostradas anteriormente es que corremos el riesgo de no descubrir zonas de separación entre las categorías que queremos etiquetar. Imaginemos que en el ejemplo anterior de las cajas existe otro pequeño conjunto de cajas de color rojo en la esquina inferior izquierda. Nuestro modelo ha descubierto que existe una separación de cajas rojas y azules en la parte superior derecha, pero se centra excesivamente en esa zona y podríamos no llegar a descubrir que en la zona inferior izquierda también hay algunas cajas de color rojo. Por esta razón, es muy importante es muy importante combinar estas técnicas de active learning con una estrategia que aporte aleatoriedad y permita “descubrir” comportamientos no esperados por el modelo, como vemos en la siguiente animación.
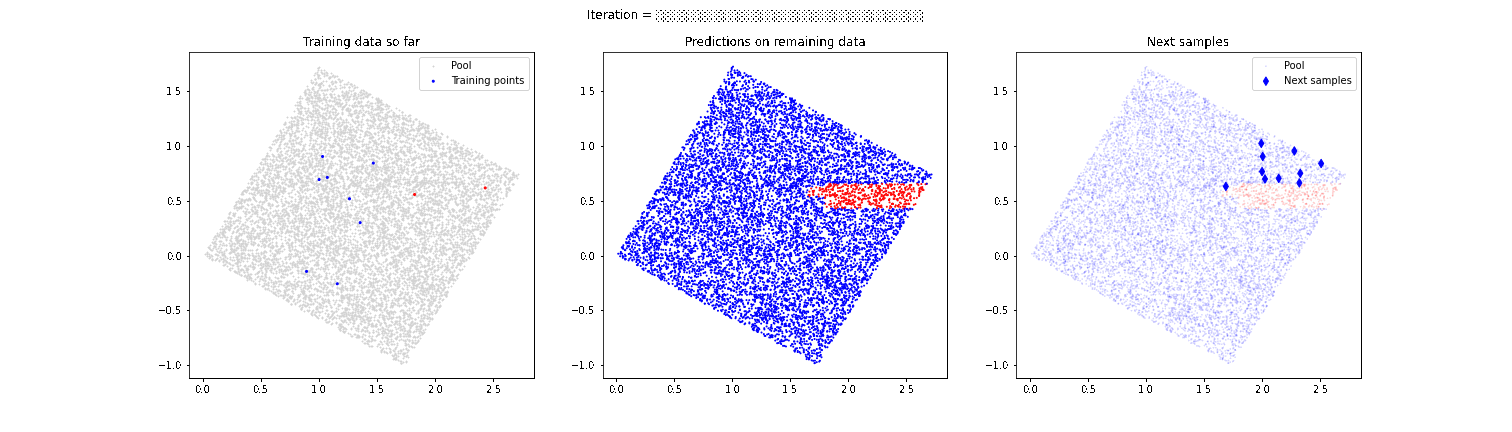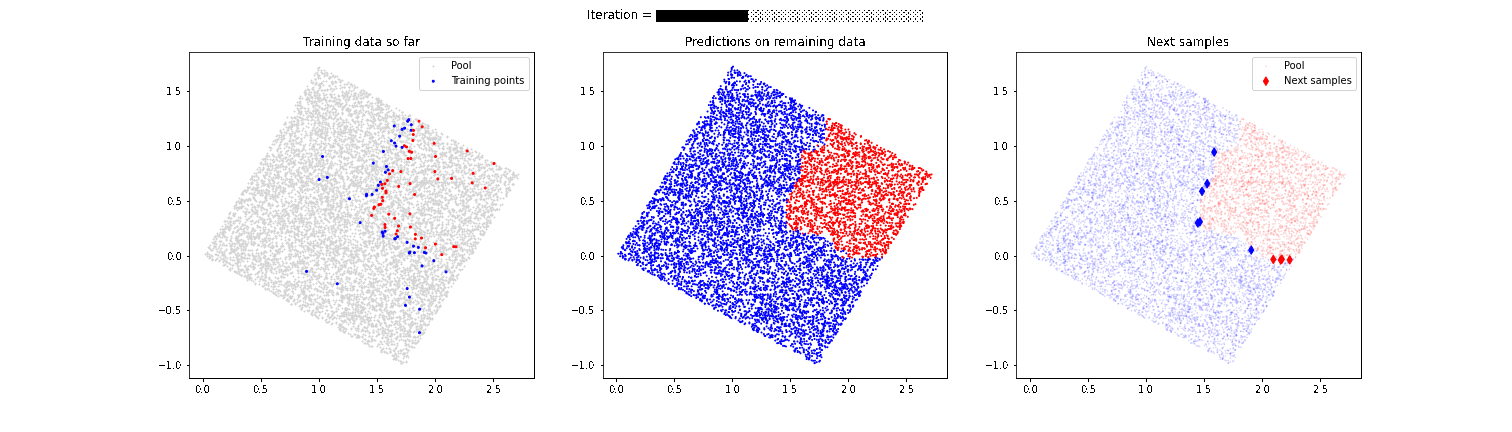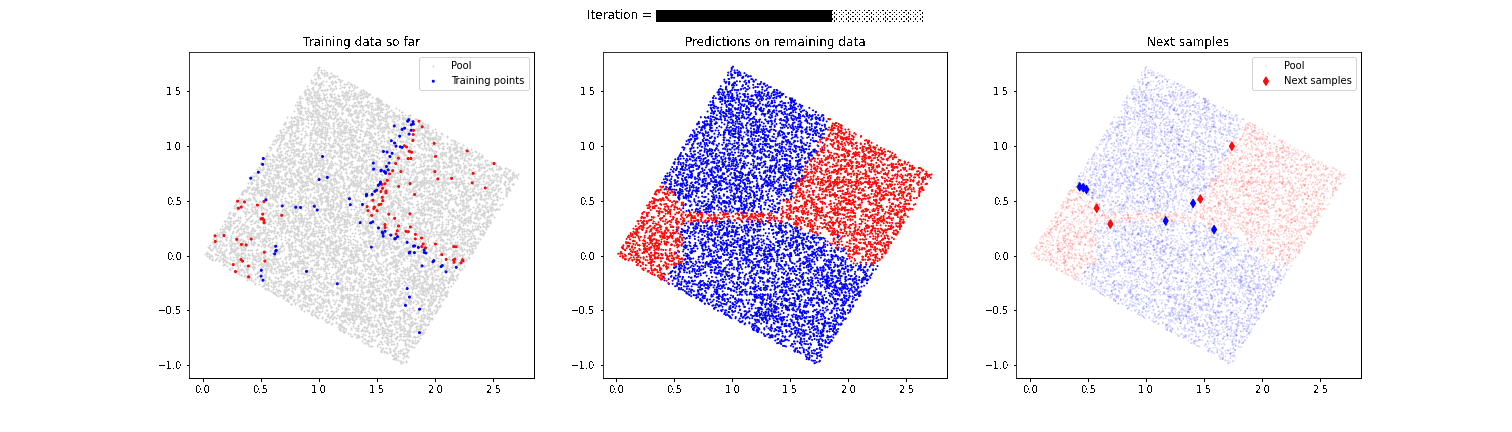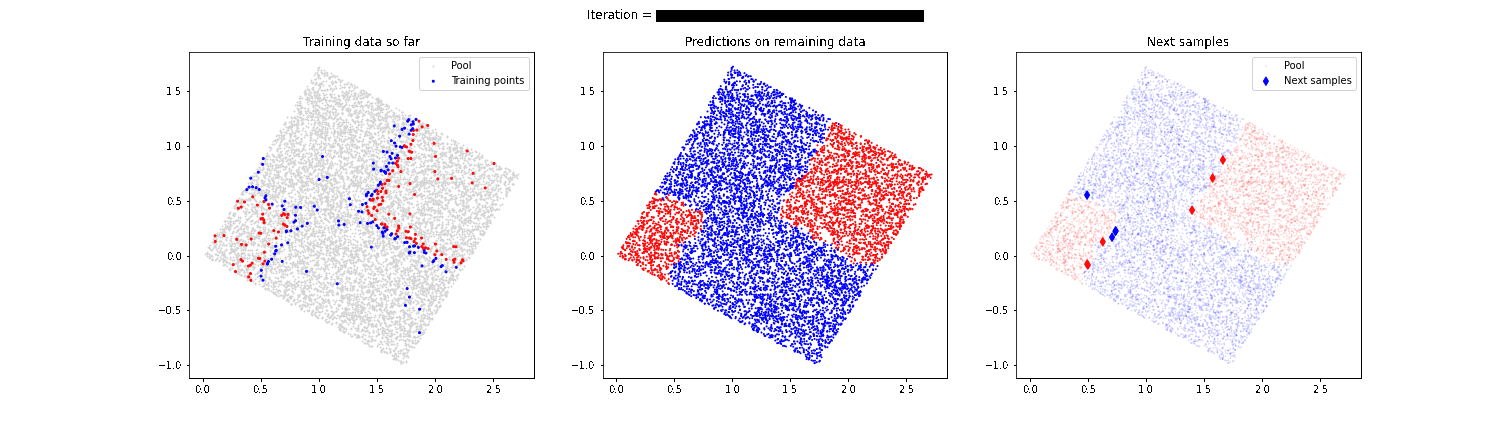
En este caso, el modelo sí es capaz de detectar esa segunda zona de cajas rojas que en un primer momento había pasado desapercibida. En próximos artículos hablaremos más en detalle de estas últimas técnicas más avanzadas, que mejoran el desempeño final del modelo.
Notas
- When we fill out a verification with the reCaptcha system, we help generate tags, such as the location of an object in an image or the transcription of a text, which are then used to train AI systems. ↩︎