
IA en finanzas: asignación inteligente de recursos financieros con Deep Reinforcement Learning
En el dinámico panorama financiero, la asignación de presupuestos sigue siendo un reto importante para los gestores de carteras. Métodos tradicionales como las carteras de ponderación fija o la optimización de Markowitz brindan enfoques fiables y sistemáticos.No obstante, sus características rígidas suelen obstaculizar la flexibilidad en mercados impredecibles.
Los recientes avances en inteligencia artificial han creado nuevas oportunidades para abordar este reto, especialmente a través del aprendizaje por refuerzo profundo (DRL, Deep Reinforcement Learning). Este método permite a los modelos aprender y adaptarse al interactuar con entornos dinámicos, lo que lo hace muy adecuado para la optimización de decisiones financieras en tiempo real.
Este artículo explora el uso del DRL en una cartera simplificada de activos financieros. Aunque los resultados son prometedores en un entorno controlado, se trata de un experimento académico con el que pretendemos fomentar una reflexión crítica sobre el potencial y las limitaciones del uso del aprendizaje profundo en finanzas.
Asignación presupuestaria en la gestión de carteras
La asignación presupuestaria en la gestión de carteras se refiere al proceso de distribución de recursos financieros entre distintos activos o estrategias de inversión para alcanzar objetivos financieros, gestionando el riesgo. Es clave para la optimización de carteras, ya que garantiza que el capital se asigne de forma eficiente en función de factores como la rentabilidad esperada, la tolerancia al riesgo, el horizonte temporal y las condiciones del mercado.
Muchos fondos e instituciones financieras utilizan estrategias de asignación presupuestaria de ponderación fija, pero con algunas variaciones en función de sus objetivos de inversión. La asignación con ponderación fija significa asignar una proporción constante de capital a distintos activos o inversiones, reequilibrando periódicamente para mantener esas ponderaciones.
Estas estrategias ofrecen notables ventajas. Por un lado, su previsibilidad y simplicidad facilitan la planificación a largo plazo, mientras que su asignación coherente a diversos activos contribuye a mantener una exposición estable al riesgo. Además, suelen ser rentables, gracias a las bajas comisiones de los fondos pasivos con ponderaciones fijas frente a los gestionados activamente.
No obstante, las estrategias de ponderación fija enfrentan desafíos por su rigidez, que limita su capacidad de adaptarse a los cambios del mercado. Esto puede hacer que ignoren tendencias emergentes u oportunidades de crecimiento, rindiendo peor en entornos dinámicos frente a enfoques adaptativos como los impulsados por IA o modelos basados en factores.
Optimización con aprendizaje por refuerzo profundo
En AI Factory hemos explorado con técnicas avanzadas de aprendizaje por refuerzo profundo (DRL) para obtener una propuesta de asignación presupuestaria a través de diferentes valores financieros (stocks). Este problema de optimización cuenta con varios enfoques, que comenzaron con el desarrollo de trabajos revolucionarios como “Portfolio Selection” de Markowitz (1952), que le valió el Premio Nobel. Desde entonces, se han explorado varias alternativas para atacar este problema de optimización financiera.
Inspirándonos en la metodología descrita en [2] [5], modelamos el mercado bursátil como un entorno dinámico, ideal para adaptarse a condiciones que cambian rápidamente. Aprovechando los datos históricos, nuestro método identifica estrategias que equilibran eficazmente el riesgo y la recompensa, ofreciendo un marco sólido para la gestión de carteras.
Esta aplicación pone de relieve el potencial transformador del aprendizaje por refuerzo en la toma de decisiones de inversión y el desarrollo de estrategias financieras, impulsando la innovación en el sector bancario. No obstante, el contenido presentado en este artículo tiene una perspectiva informativa y orientada a la investigación. Este artículo no constituye asesoramiento financiero, recomendaciones de inversión ni orientación para la gestión de carteras.
En los capítulos siguientes haremos una introducción teórica a la metodología utilizada y, a continuación, mostraremos los resultados de algunas simulaciones realizadas con datos públicos reales.
Metodología
En este trabajo aplicamos aprendizaje por refuerzo profundo para optimizar la asignación de presupuesto en una cartera de activos financieros. Este enfoque se basa en un agente que interactúa con el mercado, aprendiendo a tomar decisiones mediante ensayo y error, con el objetivo de maximizar una recompensa relacionada con el rendimiento de la cartera.
Es bien sabido que los algoritmos DeepRL actuales son capaces de aprender estrategias avanzadas, logradas a través de algoritmos como Deep Q-learning, Policy Gradient, modelos Actor-Critic, junto con trade-off de exploración/explotación. Estas estrategias también pueden trasladarse a aplicaciones industriales como robótica, juegos, finanzas, sanidad, entre otras.
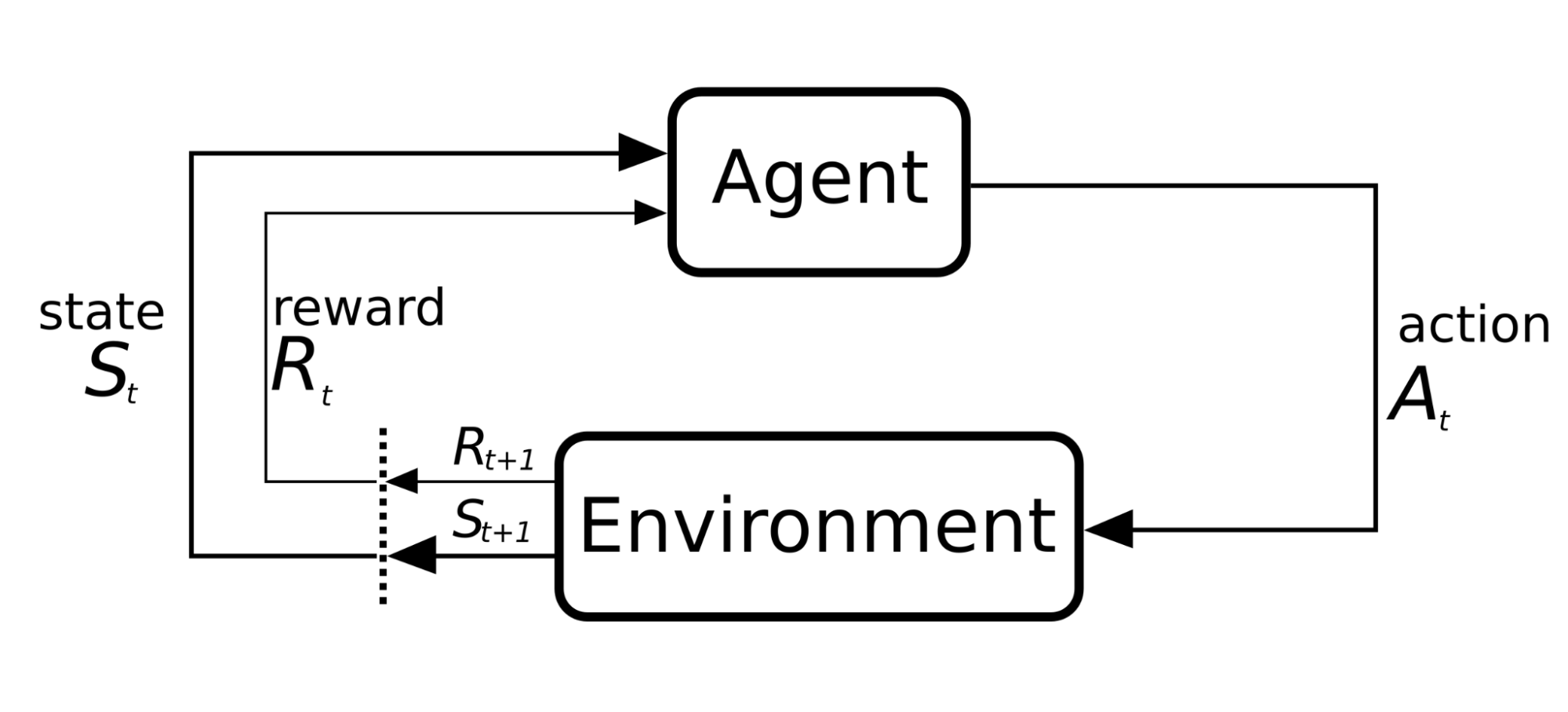
Modelamos el problema como un Proceso de Decisión de Markov (MDP), un marco matemático utilizado para modelar la toma de decisiones secuenciales en entornos inciertos, donde el resultado de cada acción es en parte aleatorio y en parte controlable. En este proceso, el agente observa un estado, realiza una acción y recibe una recompensa en cada paso temporal. Este ciclo puede visualizarse como un proceso iterativo en el que el agente percibe el entorno, actúa y recibe retroalimentación para mejorar su estrategia, tal como se ilustra en la Figura 1.
- Estado (St): representa la información disponible en el tiempo t sobre el mercado y la cartera. Incluye datos como la volatilidad reciente de los activos (por ejemplo, en períodos de 7 y 30 días) y las tendencias de precios en diferentes horizontes temporales (3, 7 y 15 días). También considera cómo está distribuido actualmente el presupuesto entre los activos.
- Acción (At): es la decisión que el agente toma sobre cómo asignar el presupuesto entre los diferentes activos. Esto se expresa como porcentajes asignados a cada inversión.
- Recompensa (Rt): es una medida numérica que refleja el resultado de la acción tomada. En nuestro caso, usamos un indicador financiero que considera el rendimiento ajustado al riesgo de la cartera, conocido como el ratio de Sharpe.
El objetivo del agente es aprender una política, es decir, una estrategia que le indique qué acción tomar dado un estado, con el fin de maximizar las recompensas acumuladas a lo largo del tiempo. Para lograrlo, el agente evalúa las consecuencias de sus decisiones en múltiples etapas, equilibrando la exploración de nuevas opciones con la explotación de estrategias que han demostrado ser efectivas.
Además, para evitar que el agente realice cambios bruscos en la asignación del presupuesto, se incluye una penalización que fomenta ajustes graduales y estables.
Los lectores deben tener en cuenta que las representaciones del estado utilizadas en el Proceso de Decisión de Markov (MDP) pueden ser limitadas y podrían mejorarse con información adicional del mercado o características consideradas relevantes, lo que permitiría al modelo detectar cambios en el mercado. Asimismo, el modelo de red neuronal puede mejorarse modificando su arquitectura para aumentar el rendimiento y captar más señales de los estados de entrada, siempre que se supervisen cuidadosamente métricas de rendimiento como el sobreajuste y la sensibilidad a los hiperparámetros.
Nuestro experimento con cinco activos financieros
Para evaluar el rendimiento del algoritmo, decidimos utilizar cinco activos, obteniendo sus datos históricos mediante la biblioteca Python de Yahoo Finanzas, yfinance: Amazon (AMZN), Alibaba (BABA), BBVA (BBVA), Nvidia (NVDA), y un activo de bajo riesgo como son los bonos del gobierno estadounidense.
La selección de estos activos se basa en su relevancia estratégica y su diversificación geográfica y sectorial. La inclusión del BBVA permite analizar el comportamiento del sector financiero en relación con otras industrias, mientras que la deuda pública estadounidense sirve como referencia de bajo riesgo. Estos activos reflejan tendencias clave del mercado, distintos niveles de riesgo y volatilidad, lo que los hace ideales para evaluar y optimizar el rendimiento del algoritmo.
Para centrarnos en el rendimiento básico del algoritmo, simplificamos las condiciones del mercado excluyendo los costes de transacción en esta fase inicial. Este enfoque nos permite evaluar las capacidades fundamentales del modelo antes de incorporar complejidades del mundo real como las comisiones por transacción. También decidimos comparar la eficacia de los algoritmos frente a otras estrategias, como Equally Weighted Portfolio, y el algoritmo de optimización de carteras de Markovitz, donde maximizamos la ratio de Sharpe utilizando EfficientFrontier.
El conjunto de datos utilizado abarca datos históricos divididos en dos períodos distintos: los datos de entrenamiento abarcan desde el 1 de enero de 2022 hasta el 31 de agosto de 2024, mientras que los datos de prueba cubren el periodo comprendido entre el 1 de septiembre de 2024 y el 31 de marzo de 2025. Todo el código fuente y los cuadernos necesarios para reproducir este ejercicio están a disposición del público en este repositorio de GitHub
Resultados
El conjunto de datos utilizado abarca datos históricos divididos en dos períodos distintos: los datos de entrenamiento abarcan desde el 1 de enero de 2022 hasta el 31 de agosto de 2024, mientras que los datos de prueba cubren el periodo comprendido entre el 1 de septiembre de 2024 y el 31 de marzo de 2025.
Todo el código fuente y los cuadernos necesarios para reproducir este ejercicio están a disposición del público en este repositorio de GitHub.
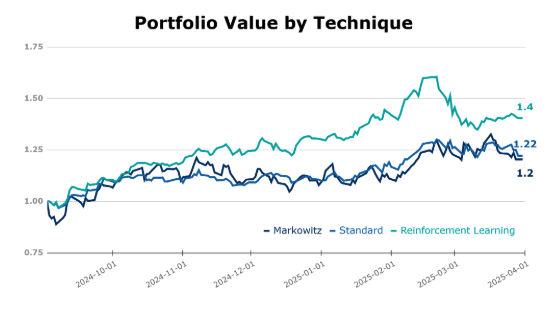
Por otra parte, observando las métricas de la tabla siguiente, el modelo DRL demuestra rendimientos diarios medios significativamente superiores (0,16%) en comparación con Markowitz (0,11%) y Equally Weighted (0,10%), con un ratio de Sharpe superior y un valor en riesgo inferior al nivel de confianza del 95%. Las pruebas Dickey-Fuller aumentadas confirman que todas las estrategias tienen rendimientos estacionales, lo que valida el análisis paramétrico del riesgo y respalda la solidez de su rentabilidad.
| Metric | DeepRL | Markowitz | Equally Weighted |
|---|---|---|---|
| Daily Mean Return | 0.16% | 0.11% | 0.10% |
| Annualized Sharpe Ratio | 2.2462 | 1.0464 | 1.5868 |
| Augmented Dickey-Fuller p-value | < 0.05 | < 0.05 | < 0.05 |
| VaR (95%) | -1.38% | -2.39% | -1.65% |
Para ponerlo en perspectiva, el S&P 500 bajó aproximadamente un 0,65% durante el periodo de prueba, mientras que el NASDAQ 100 cayó alrededor de un 1,51%[6] [7]. Aunque estos resultados son prometedores, es importante señalar que las condiciones del mercado en este experimento eran simplificadas, lo que puede afectar al rendimiento en el mundo real. No obstante, el rendimiento del modelo RL en este entorno controlado parece prometedor y puede indicar potencial para aplicaciones en el mundo real.
En la siguiente figura, podemos ver la distribución de presupuesto que nuestro agente va realizando día a día. Por otro lado, podemos ver cómo los cambios en la distribución del presupuesto de nuestro agente RL son lo menos drásticos posibles, debido a la penalización incluida en nuestra política.
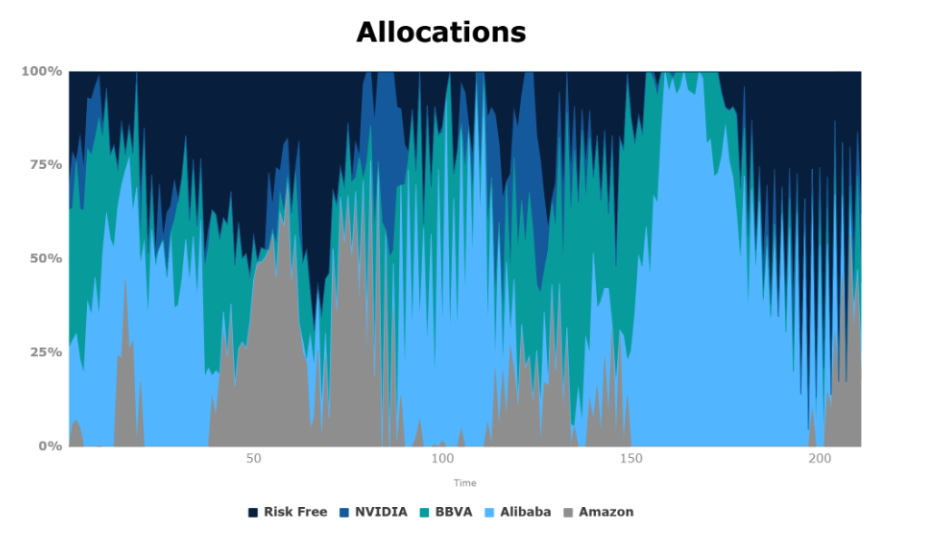
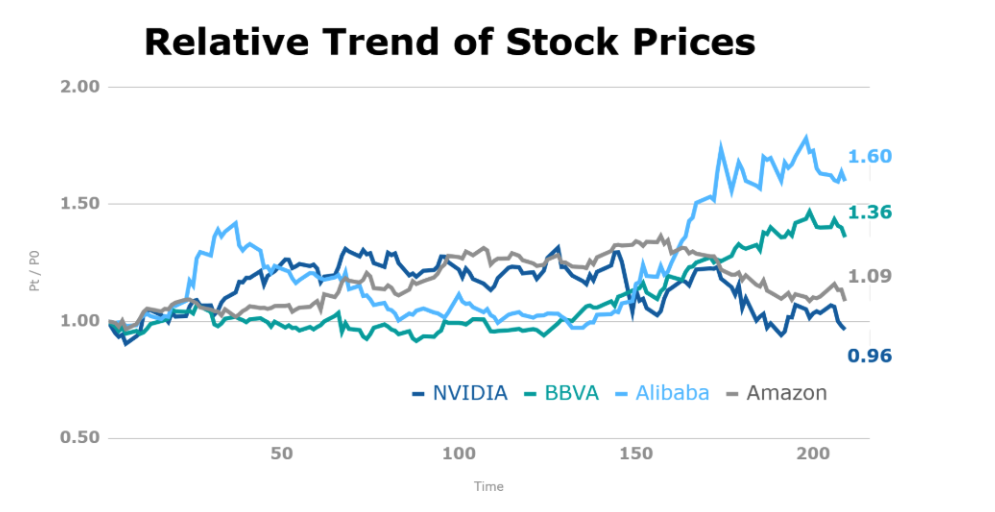
Analicemos detenidamente las decisiones tomadas por nuestro agente. Observamos que en el caso de Alibaba, cuyo precio comienza a caer a los 40 días (ver figura inferior), nuestro agente lo detecta y rápidamente realiza un reajuste en cómo distribuye el presupuesto, reduciéndolo a Alibaba.
El enfoque mostrado es bastante simple, en cuanto al número de acciones, las señales consideradas en nuestras variables de estado, y la suposición de cero comisiones por transacción. Sin embargo, mostramos una forma de empezar a utilizar este tipo de técnicas explicando algunos aspectos teóricos, a la hora de utilizar técnicas como DeepRL, para la toma de decisiones dinámicas en la distribución de presupuestos.
Referencias
- Richard S. Sutton and Andrew G. Barto, Reinforcement Learning An Introduction, The MIT Press. 2014.
- Yves J. Hilpisch, Reinforcement Learning for Finance, O’Reilly Media, Inc. October 2024. Link ↩︎
- Trade That Swing. Average Historical Stock Market Returns for S&P 500: 5-Year up to 150-Year Averages. Accessed January 14, 2025. Link
- Trade That Swing. Historical Average Returns for NASDAQ 100 Index (QQQ). Accessed January 14, 2025. Link
- Benhamou, E., Saltiel, D., Ungari, S., & Mukhopadhyay, A. (2020). Bridging the gap between Markowitz planning and deep reinforcement learning. arXiv preprint arXiv:2010.09108. Link ↩︎
- AMSFlow. NASDAQ 100 Historical Returns. Accessed April 8, 2025. Link ↩︎
- AMSFlow. S&P 500 Historical Returns. Accessed April 8, 2025. Link ↩︎