
Una Nueva Interpretación Urbana a través del Análisis de la Actividad Comercial (Parte 1)
Las divisiones oficiales de las ciudades, como distritos y barrios, están siendo utilizadas no sólo para gobernar las ciudades sino también para describir el comportamiento de los ciudadanos. De hecho, las estadísticas oficiales y el open data utilizan estas divisiones para agregar la información que publican. Sin embargo, estas divisiones podrían no ser la mejor opción para estos propósitos ya que en la actualidad los ciudadanos no las tienen en cuenta a la hora de moverse por la ciudad.
La iniciativa Urban Analytics de BBVA Data & Analytics, en colaboración con CARTO, muestra cómo se puede aplicar la ciencia de datos, sobre dato anonimizado y agregado, para identificar áreas funcionales, describir dinámicas y establecer comparaciones entre tres grandes ciudades como Madrid, Barcelona y Ciudad de México.
Contexto
Los gobiernos organizan las ciudades en distritos y barrios. Los servicios de correos usan códigos postales. Pero, ¿de verdad estas divisiones sirven para entender la actividad de sus habitantes y visitantes? Al fin y al cabo fueron creadas hace tiempo para múltiples propósitos y raramente se han actualizado aunque los hábitos de los habitantes sí que hayan cambiado. Teniendo en cuenta todo esto, en este proyecto hemos comprobado cómo quedarían divididas las ciudades si se siguiese un criterio de movilidad. ¿Permanecería alguna división oficial sin cambio? ¿Cuál sería el número óptimo de divisiones? Además, también hemos caracterizado las divisiones obtenidas basándonos en patrones de consumo observados en los datos transaccionales.
Fuentes de datos y modelo analítico
Red de conexiones: El primer paso de este proyecto ha sido establecer relaciones entre distintas zonas de las ciudades analizadas a partir de transacciones con tarjeta. En este caso, se optó por describir patrones de movilidad económica identificando consumidores compartidos entre distintas partes de la ciudad. Para ello, cada ciudad fue completamente dividida en celdas hexagonales de 200 metros de lado. Una vez hecho esto, cada vez que una misma tarjeta es utilizada en dos comercios pertenecientes a distintas celdas en un periodo menor a 3 horas se crea una conexión entre estas dos celdas. Esta operación se aplica a todas las transacciones realizadas en cada ciudad durante un año para asegurar que los patrones de consumo estacionales son incluidos. Cada una de estas conexiones recibe el nombre de copago; aquí puedes ver las redes de copagos correspondientes a las ciudades de Madrid, Barcelona y CDMX.

Identificación de áreas funcionales: Cada una de estas redes pesadas y no dirigidas contiene una gran cantidad de información sobre la manera en la que los consumidores se desenvuelven por la ciudad. Por eso, analizar su estructura permite encontrar una nueva manera de dividir la ciudad. En particular, al ejecutar distintos algoritmos de detección de comunidades se obtienen conjuntos de hexágonos fuertemente conectados. En este caso se han aplicado algoritmos basados en distintos enfoques como caminos aleatorios, autovectores principales, optimización de modularidad o propagación de etiquetas para comprobar qué resultados se obtenían.
Todos los algoritmos utilizados comparten la característica de no necesitar como parámetro el número de comunidades que deben devolver ya que la comparativa con el número de divisiones oficiales resulta interesante. Bajo estas condiciones la obtención de clusters similares con distintos algoritmos es una prueba de consistencia que ha servido para seleccionar un algoritmo voraz. Dado que sus resultados son similares a los de otros algoritmos, su elección se debe al menor coste computacional respecto a estos. Este aspecto es especialmente importante para hacer posible su ejecución sobre la red de de Ciudad de México ya que ésta contiene más de 94 millones de copagos. Además, la selección de un mismo algoritmo para todas las ciudades hace posible las comparaciones entre ellas, incluyendo la identificación de áreas gemelas entre ciudades.
Los clusters resultantes, denominados macrocomunidades, tienen un tamaño similar al de los distritos oficiales pero, como cabía esperar, aparecen interesantes diferencias entre ellos. Es este tamaño el que hace que las macrocomunidades sean demasiado heterogéneas para ser descritas mediante atributos de consumo. Por esa razón, el mismo algoritmo de detección de comunidades se aplica a cada macrocomunidad (a la parte de la red de copagos correspondiente) para obtener una división más detallada del territorio. Estas nuevas particiones se denominan comunidades y, esta vez sí, permiten ser caracterizadas mediante atributos de consumo. Vale la pena comentar que los shapefiles correspondientes tanto a macrocomunidades como a comunidades están disponibles para su descarga en la página web del proyecto.
Caracterización de comunidades: Para definir los atributos de consumo que permiten caracterizar cada comunidad se han utilizado todas las transacciones realizadas en la ciudad durante un año. A partir de los datos asociados a las transacciones se construyen más de 25 variables relacionadas con los comercios, los consumidores y el momento de la transacción. Para cada variable, los hexágonos reciben un valor discreto (bajo, medio, alto) que hace referencia a su desempeño comparado con el resto de la ciudad. Por ejemplo, la variable “Turismo nacional” mide el gasto realizado por turistas nacionales en cada hexágono. Una vez calculada, los hexágonos se ordenan y los valores discretos se asignan: alto para los hexágonos en el cuartil superior, bajo para los del cuartil inferior y medio para el resto.
En vez de utilizar directamente estos valores como caracterización de cada hexágono, el objetivo perseguido era encontrar qué características diferencian cada comunidad del resto de la ciudad. Para ello, se ha construido un modelo de clasificación para cada comunidad. Supongamos que queremos saber qué variables distinguen a los hexágonos de la comunidad C de los del resto de la ciudad. El conjunto de entrenamiento estará compuesto por todos los datasets de la ciudad y las variables asignadas anteriormente. La variable objetivo y del modelo de clasificación tendrá un valor binario que informará de si el hexágono pertenece a la comunidad C o no.
Como el objetivo de construir los modelos de clasificación es identificar qué variables son significativas en cada caso, no solo no se elimina el overfitting sino que se fomenta. Por esa razón, y dado que todos los conjuntos de datos están desbalanceados (el número de hexágonos que pertenece a la comunidad es mucho menor que el de los que no pertenecen) se aplica una técnica de over-sampling aleatorio básica para balancear la muestra.
Una vez que los conjuntos de entrenamiento están preparados se entrena un modelo de regresión logística y un árbol de decisión para cada comunidad cuyos valores de significatividad de cada variable nos sirven para identificar aquellas que distinguen cada comunidad del resto de la ciudad.
El último paso del proceso de caracterización consiste en combinar variables para crear los 17 atributos utilizados en la aplicación. Al combinar variables se obtienen atributos que contienen mucha más información. Por ejemplo, el atributo “Ocio cultural” no sólo hace referencia a la existencia de museos y galerías de arte en una determinada zona sino que también informa de que la zona atrae a consumidores que gastan más que la media en cultura. Otro buen ejemplo es el atributo de “Área residencial”. Aunque no se ha utilizado ningún tipo de información adicional, a través de las transacciones se pueden identificar zonas sin actividad en horario laboral, cuyo tejido comercial es limitado y sin presencia de turistas y asignarles este atributo. Así, el atributo “Área residencial” nace de combinar estas tres variables.
La herramienta
Además de consultar las divisiones resultantes del proceso de detección de comunidades, los usuarios pueden manejar una herramienta interactiva que les permitirá seleccionar aquellos atributos en los que están más interesados, combinarlos y comprobar qué comunidades cumplen los requisitos. Por ejemplo, alguien que esté buscando alojamiento podrá buscar zonas donde se desenvuelvan personas de su rango de edad y donde pueda encontrar comercios de proximidad para centrar su búsqueda en una determinada zona.
Por cada atributo, la herramienta muestra dos valores: SI y NO. Los usuarios pueden seleccionar uno de ellos para filtrar el mapa y dejar iluminadas sólo aquellas comunidades que tienen ese valor en el atributo seleccionado. El botón de autostyle (gota de agua sobre cada atributo) permite previsualizar qué comunidades tienen asignado cada valor del atributo sin necesidad de realizar el filtrado. Además, más de un atributo puede ser filtrado a la vez, lo que permite que los usuarios los combinen y generen búsquedas más complejas.
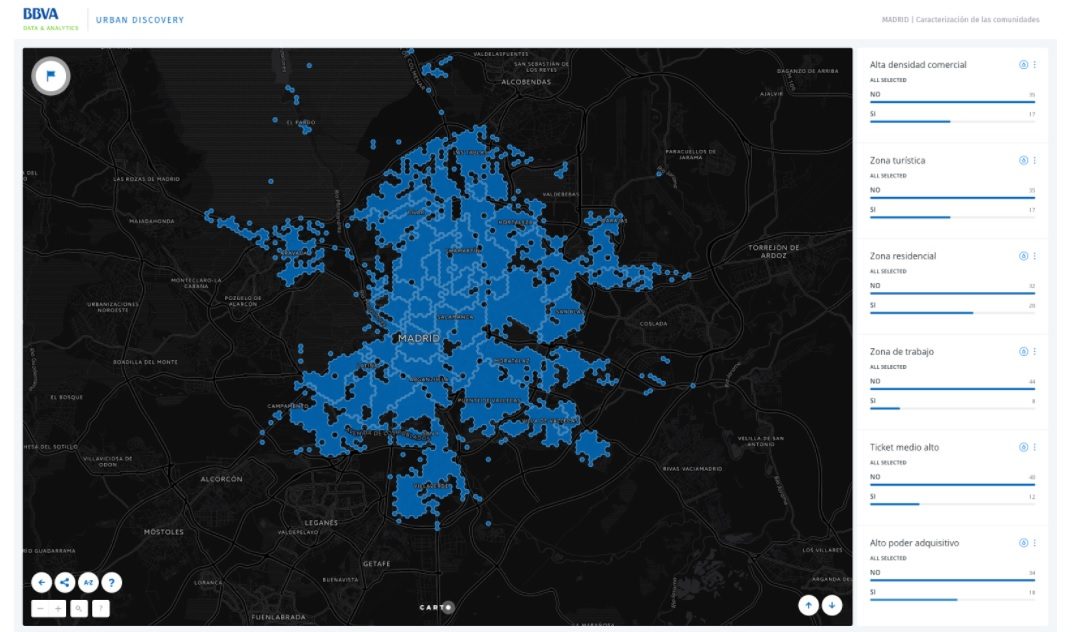
Por último, los usuarios pueden crear sus propias etiquetas para describir la ciudad. Una vez terminado el proceso de filtrado, pueden asignar un nombre al área que permanece iluminada utilizando el botón de la bandera situado en la esquina superior izquierda de la pantalla. Este feedback servirá para comprobar cómo es vista cada ciudad por sus habitantes. Además, aquellas usuarios que utilicen la herramienta de etiquetado podrán saltar a otras ciudades comprobar qué áreas se corresponden con su filtrado, encontrando así áreas gemelas entre ciudades.
Como conclusión, este proyecto muestra cómo se pueden aplicar técnicas de ciencia de datos (análisis de redes y algoritmos de clasificación en este caso) a datos transaccionales geoposicionados para tomar el pulso a grandes ciudades. Además, en este proyecto se ha puesto énfasis en desarrollar una web abierta que no sólo permita a los usuarios (individuos, empresas o la propia administración) navegar por los resultados, sino que además puedan descargar los mapas de divisiones y atributos generados. Desde BBVA Data & Analytics esperamos que estos resultados puedan ser útiles para múltiples aplicaciones.