
Mercury-Monitoring: componentes analíticos para monitorear modelos de ML
El crecimiento de la Inteligencia Artificial en los últimos años ha sido vertiginoso. Su repentina proliferación refleja el exponencial desarrollo de sistemas basados en esta tecnología, la cual tiene un impacto cada vez mayor en todas las esferas de nuestra vida cotidiana. En concreto, en BBVA se utilizan soluciones de Machine Learning para dar servicio a nuestros clientes diariamente. Estos métodos permiten la creación de sistemas como la clasificación de movimientos bancarios o la detección del nivel de urgencia de un mensaje de un cliente.
El desarrollo de estos sistemas implica múltiples validaciones previas a su despliegue para asegurar que los modelos funcionan correctamente en entornos de producción. Sin embargo, cuando se pone en marcha un modelo, los equipos responsables deben reparar en su funcionamiento, ya que éstos suelen operar en entornos muy dinámicos: el comportamiento de los clientes cambia constantemente, la actividad económica puede verse impactada por diversas circunstancias, los estafadores hallan nuevas técnicas para evitar los sistemas de detección de fraude, entre otras contingencias.
Por todo esto, el rendimiento de los modelos puede degradarse. En otras palabras, las salidas de estos sistemas, entendidas como los resultados que arrojan los modelos, pueden volverse incorrectas rápidamente, lo cual acentúa el riesgo de producir daños en el negocio o derivar en polémicas reputacionales para la organización.
En este escenario, la monitorización de modelos es una práctica esencial en la fase operacional de un proyecto de ciencia de datos, pues nos ayuda a detectar problemas en tiempo real, prevenir la degradación de su precisión a través de predicciones, y asegurar que los modelos se comportan según lo previsto a lo largo del tiempo. El uso de herramientas innovadoras que faciliten dicha monitorización se vuelve imprescindible para garantizar la calidad y estabilidad de los sistemas.
Mercury-Monitoring para evaluar el desempeño de los modelos
Dentro de BBVA hemos desarrollado Mercury, una librería de Python que hemos liberado recientemente. Ésta contiene componentes con potencial de ser reutilizables en diferentes etapas de los proyectos de ciencia de datos. Actualmente, la versión open-source de Mercury está dividida en seis paquetes, cada uno enfocado en una temática concreta, los cuales se pueden utilizar de manera independiente.
Hoy dedicamos este espacio para conocer más de cerca mercury-monitoring, un paquete que consta de componentes analíticos especialmente diseñados para facilitar la monitorización de modelos de Machine Learning.

Este paquete ha sido usado internamente para evaluar el impacto del data-drift (dígase de los cambios en las distribuciones de los datos) en el categorizador de movimientos en cuentas y tarjetas de BBVA. Un ejemplo concreto ocurrió en el año 2020, durante la etapa más fuerte de la pandemia de Covid-19, cuando pudimos observar importantes desviaciones en categorías de gasto como viajes, medios de transporte, hoteles y peajes.
Además, nos ha servido para monitorizar el drift en la generación de variables transaccionales que posteriormente se consumen en modelos de riesgo crediticio, entre otras muchas aplicaciones.
Creemos que la iniciativa de liberar este paquete como open-source permitirá que toda la comunidad pueda beneficiarse, para también mejorar y ampliar sus funcionalidades. Por el momento, sus principales capacidades están relacionadas con una amplia variedad de técnicas para la detección de data-drift y con la estimación del rendimiento de un modelo en producción cuando todavía no se disponen de etiquetas.
A. Detección de Data-Drift
El término data-drift hace referencia a cuando los datos que recibe un modelo en el momento de inferencia cambian respecto a los datos utilizados para entrenar el modelo. Esto puede hacer que el modelo deje de funcionar correctamente y, por lo tanto, realice predicciones imprecisas.
¿Por qué se produce el Data-Drift?
El Data Drift se puede producir por varias causas, entre las que destacamos:
- Si ocurren cambios en el entorno donde “vive” el modelo. Por ejemplo, desviaciones en la actividad económica, nuevos productos introducidos por la competencia, o nuevas técnicas de fraude creadas por los estafadores;
- En casos de alteración en algún proceso, donde por ejemplo podrían variar las unidades que reciben las entradas o inputs del modelo;
- Cuando ocurren cambios relacionados con la estacionalidad. Por ejemplo, si estamos tratando con un clasificador de texto para detectar la temática de los mensajes de los clientes, puede haber un incremento puntual de dudas relacionadas con la declaración de la renta por tratarse de los meses en los que se debe presentar.
Tipos de Data-Drift
En la mayoría de casos, la detección de drift se realiza entre dos conjuntos de datos: el conjunto de datos “source”, el cual suele utilizarse para entrenar un modelo, y el conjunto de datos “target”, los datos que el modelo se encuentra una vez desplegado en producción.
Existen multitud de recursos que describen de manera más extensa los diferentes tipos de data-drift123, pero, de manera genérica, podemos distinguir:
| Concept Shift (o Concept drift) Ocurre cuando el contexto para el cual el modelo ha sido entrenado cambia durante el tiempo. |
Covariate Shift (O Feature drift) Este caso ocurre cuando la distribución de las variables de entrada de un modelo cambian a lo largo del tiempo respecto a los datos utilizados durante el entrenamiento. |
Label Shift (o prior probability shift) Se produce cuando la distribución de las variables de entrada se mantiene, pero cambia la variable target. |
| Ejemplo Si un modelo se entrena para detectar transacciones fraudulentas, éste se despliega en producción y posteriormente los estafadores cambian sus técnicas, será mucho más complicado que el modelo consiga detectarlas. |
Ejemplo Podemos considerar un modelo que predice la probabilidad de un cliente de comprar cierto producto. Si los ingresos de los clientes cambian una vez el modelo se ha desplegado en producción, el modelo puede volverse más impreciso, pues se encontraría con una distribución de datos de entrada diferente a la que había sido entrenado. |
Ejemplo Entre 2022 y 2023 se ha producido un incremento histórico de los tipos de interés debido a los altos niveles de inflación. Por ello, cada vez más clientes con ahorros están prefiriendo amortizar parcialmente sus créditos a tipo de interés variable. Supongamos que tenemos un clasificador que infiere la operativa que el cliente desea realizar al comunicarse con su gestor. En el entorno actual es bastante más probable que, ante el mismo contenido del mensaje, dicho clasificador otorgue más probabilidad a la operativa de amortización parcial anticipada de lo que lo hubiera hecho antes (antes de la subida de tipos era una operativa casi residual). |
|
En términos matemáticos 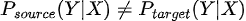 aún teniendo 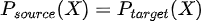 Es decir, la relación entre las variables de entrada inputs del modelo X y la variable a predecir Y cambia. |
En términos matemáticos 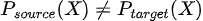 aunque 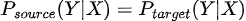 Es decir, aunque la relación entre las variables de entrada X y la variable target Y permanece igual, cambia la distribución de alguna o algunas variables de entrada. |
En términos matemáticos 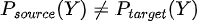 aunque 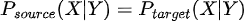 Es decir, aunque la relación entre las variables de entrada X y la variable target Y permanece igual, sí cambia la distribución de salida Y (a diferencia del covariate shift donde cambiaba la entrada) |
1. Concept Shift (o Concept drift)
Ocurre cuando el contexto para el cual el modelo ha sido entrenado cambia durante el tiempo.
Ejemplo
Si un modelo se entrena para detectar transacciones fraudulentas, éste se despliega en producción y posteriormente los estafadores cambian sus técnicas, será mucho más complicado que el modelo consiga detectarlas.
En términos matemáticos
aún teniendo
Es decir, la relación entre las variables de entrada inputs del modelo X y la variable a predecir Y cambia.
2. Covariate Shift (O Feature drift)
Este caso ocurre cuando la distribución de las variables de entrada de un modelo cambian a lo largo del tiempo respecto a los datos utilizados durante el entrenamiento.
Ejemplo
Podemos considerar un modelo que predice la probabilidad de un cliente de comprar cierto producto. Si los ingresos de los clientes cambian una vez el modelo se ha desplegado en producción, el modelo puede volverse más impreciso, pues se encontraría con una distribución de datos de entrada diferente a la que había sido entrenado.
En términos matemáticos
aunque
Es decir, aunque la relación entre las variables de entrada X y la variable target Y permanece igual, cambia la distribución de alguna o algunas variables de entrada.
3. Label Shift (o prior probability shift)
Se produce cuando la distribución de las variables de entrada se mantiene, pero cambia la variable target.
Ejemplo
Entre 2022 y 2023 se ha producido un incremento histórico de los tipos de interés debido a los altos niveles de inflación. Por ello, cada vez más clientes con ahorros están prefiriendo amortizar parcialmente sus créditos a tipo de interés variable. Supongamos que tenemos un clasificador que infiere la operativa que el cliente desea realizar al comunicarse con su gestor. En el entorno actual es bastante más probable que, ante el mismo contenido del mensaje, dicho clasificador otorgue más probabilidad a la operativa de amortización parcial anticipada de lo que lo hubiera hecho antes (antes de la subida de tipos era una operativa casi residual).
En términos matemáticos
aunque
Es decir, aunque la relación entre las variables de entrada X y la variable target Y permanece igual, sí cambia la distribución de salida Y (a diferencia del covariate shift donde cambiaba la entrada)
En la práctica, es difícil determinar qué tipo de data-drift se está produciendo. Conocerlo es más útil para el ámbito académico que para el de una aplicación industrial. Además, en ocasiones incluso podrían darse varios tipos de drift simultáneamente. Independientemente del tipo, lo más importante es detectar si existe drift y tomar acciones para mitigar sus efectos.
¿Qué hacer cuando se encuentra data-drift?
La acción más evidente al detectar que el rendimiento de nuestro modelo pueda estar siendo afectado por drift es reentrenarlo con nuevos datos. En el caso de no contar con mecanismos para detectarlo, podríamos plantearnos reentrenar nuestros modelos de manera regular con nuevos datos; sin embargo, en algunos modelos esto puede suponer un alto coste computacional, por lo que no suele ser una opción efectiva.
Otras estrategias incluyen el uso de modelos de aprendizaje adaptativo o modelos que sean robustos ante cambios en las distribuciones de datos.
La existencia de data-drift no siempre implica que el rendimiento del modelo se esté deteriorando, por lo que también trabajamos en estimar la resistencia al drift de los diferentes modelos de Machine Learning.
¿Qué componentes en mercury-monitoring permiten la detección de data-drift?
Existen varias estrategias para la detección de data-drift. Podemos distinguir entre métodos que detectan drift al tratar individualmente cada una de las variables de un dataset, y los que consideran todas las variables de manera conjunta; es decir, su distribución conjunta.
|
Componentes para detectar drift observando las variables de manera individual |
Componentes para detectar drift observando las variables de manera conjunta |
Estos componentes, además de ofrecer un resultado booleano, es decir, binario (sí/no), de si se ha detectado drift o no, también devuelven un puntaje con la cantidad de drift. Esto permite monitorear a lo largo del tiempo la cantidad de drift en los datos. |
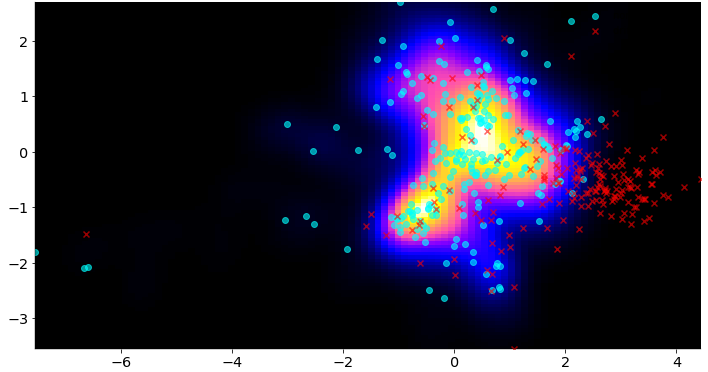
|
Componentes para detectar drift observando las variables de manera individual
- KSDrift: Realiza un test Kolmogorov-Smirnov para cada variable, y si detecta drift en al menos una de ellas, el resultado de detección de drift será positivo.
- ChiDrift: De manera similar, este test ejecuta un test chi-square de independencia entre distribuciones en cada una de las variables.
- HistogramDistanceDrift: En este caso, se calcula la distancia entre histogramas para cada una de las variables, para así detectar si hay drift en ellas. Esta distancia puede ser calculada de distintas maneras; por ejemplo, es posible utilizar la Hellinger Distance o la Jeffreys Divergence.
Estos componentes, además de ofrecer un resultado booleano, es decir, binario (sí/no), de si se ha detectado drift o no, también devuelven un puntaje con la cantidad de drift. Esto permite monitorear a lo largo del tiempo la cantidad de drift en los datos.
Componentes para detectar drift observando las variables de manera conjunta
- DomainClassifierDrift: Entrena un clasificador para detectar si una muestra proviene del dataset de referencia (el de entrenamiento) o del dataset de inferencia. Si el clasificador consigue un rendimiento lo suficientemente bueno, entonces el componente indicará que se ha detectado drift.
- AutoEncoderDriftDetector: Este método está basado en autoencoders. Primero, se sacan varias muestras del dataset de referencia mediante un muestreo con bootstrapping. Con estas muestras se entrena un autoencoder en cada una de ellas y se guarda la distribución del error de reconstrucción para cada autoencoder. Posteriormente, cuando tenemos el dataset de inferencia, calculamos la distribución del error de reconstrucción de este dataset y se compara con la distribución obtenida en el dataset de referencia. Mediante un test de Test U de Mann-Whitney se decide si existe drift o no.
- DensityDriftDetector: Este método se basa en calcular la probabilidad de que una muestra sea anómala con respecto a un dataset de referencia. Se basa en el uso de Variational AutoEncoders para construir embeddings y estimar una densidad, de manera que zonas del espacio donde existan muchos embeddings tengan una densidad alta, mientras que zonas con baja densidad de embeddings tengan una densidad baja. De esta manera, si el embedding de una muestra de inferencia está localizado en una zona con baja densidad de muestras, puede considerarse con mayor probabilidad de una anomalía.
B. Estimación de performance de un modelo sin etiquetas
En ocasiones, una vez desplegamos el modelo en producción y empieza a realizar predicciones, no tenemos la certeza de cuál es el desempeño del modelo sobre esos nuevos datos. Es decir, no poseemos información sobre las etiquetas reales.
Esto ocurre, por ejemplo, a la hora de ofrecer un producto a un cliente, ya que puede tardar un tiempo desde que se le ofrece hasta que lo adquiere. Otro caso podría ser a la hora de predecir el riesgo de impago de un préstamo: hasta que no se ha pagado, no es posible saber si el modelo ha hecho una predicción correcta o no.
¿Cómo resolverlo con mercury-monitoring?
Mercury-monitoring dispone de un componente para predecir el desempeño de un modelo cuando no conocemos las etiquetas. El método utilizado está basado en el paper Learning to Validate the Predictions of Black Box Classifiers on Unseen Data4. Dado un modelo entrenado, los pasos seguidos por este método son:
- Aplicar corrupciones a un dataset de prueba del cual obtenemos las etiquetas.
- Obtener percentiles de los outputs del modelo y del desempeño del modelo cuando se aplican esas corrupciones.
- Entrenar el regresor para predecir el desempeño de un modelo con las muestras obtenidas.
- Usar el regresor para estimar el desempeño de un modelo con los datos no etiquetados en tiempo de inferencia.
Aunque no siempre es capaz de predecir el desempeño de manera adecuada, experimentalmente hemos validado que el método es capaz de detectar caídas de rendimiento del modelo en múltiples circunstancias, lo que nos confirma su utilidad para realizar una estimación de su rendimiento.
¡Manos a la obra!
Mercury-monitoring está disponible en pypi y la manera más fácil de instalarlo es utilizando pip:
pip install -U mercury-monitoring
Tras la instalación, una buena manera para iniciarse con la librería es proceder a revisar alguno de los tutoriales o visitar la documentación. También es recomendable visitar el repositorio si se quiere entender más sobre cómo funcionan internamente los componentes.
Conclusiones
Monitorear los modelos que desplegamos en producción es algo crítico para comprender su desempeño real, obtener ese feedback e iterar en consecuencia. Situaciones como el data-drift pueden impactar en la mayoría de los sistemas de Machine Learning, por lo que disponer de herramientas para detectar caídas de rendimiento de nuestros modelos nos ayuda a ser proactivos para mantenerlos operativos correctamente en entornos productivos.
Referencias
- Moreno-Torres, J. G., Raeder, T., Alaiz-Rodríguez, R., Chawla, N. V., & Herrera, F. (2012). A unifying view on dataset shift in classification. Pattern recognition, 45(1), 521-530. ↩︎
- Webb et al., Characterizing concept drift, Data Mining and Knowledge Discovery, 2016. ↩︎
- Chip Huyen. Data Distribution Shifts and Monitoring ↩︎
- Schelter, Sebastian and Rukat, Tammo and Biessmann, Felix. Learning to Validate the Predictions of Black Box Classifiers on Unseen Data (2020). ↩︎