
Mejor prevenir que curar: así aplicamos Machine Learning para mitigar la deuda
El negocio principal del banco es prestar dinero. Mediante el pago de cuotas, la entidad financiera ofrece a las personas la posibilidad de comprar una casa, un coche o de crear sus propios comercios. Sin embargo, cuando los clientes afrontan adversidades y entran en mora, es decir, cuando se retrasan en el pago de sus cuotas, se puede generar una situación desfavorable tanto para el banco como para los mismos clientes.
En AI Factory desarrollamos modelos predictivos para la resolución temprana de la deuda frente a diversas casuísticas. El objetivo es que el cliente salga pronto de esa situación desfavorable, o que dicha situación no empeore. Gracias a estos modelos, el banco puede ofrecer soluciones tempranas, como refinanciaciones y adecuación a cuotas asequibles.
Hoy queremos contar cómo desarrollamos modelos destinados a la recuperación (pago) de deuda. Para ello, usamos técnicas punteras de Machine Learning (ML, por sus siglas en inglés), en el contexto del aprendizaje supervisado con datos tabulares, es decir, datos estructurados.
Concretamente, hemos desarrollado un pipeline o flujo de trabajo en el que automatizamos varios procesos comunes en los distintos modelos de gestión de deuda que desarrollamos. Este combina métodos tradicionales del mundo del análisis de riesgos con lo último en librerías de aprendizaje supervisado.
Nuestros casos de uso: diferentes modelos para afrontar diferentes estados de deuda
Los clientes pueden encontrarse en diferentes estados respecto al pago de sus deudas, para los que aplicamos diferentes modelos de datos. Todos estos modelos ayudan a los gestores de BBVA a decidir qué acciones tomar lo antes posible.
| Estado respecto a la deuda | Al corriente de pago | En inversión irregular, cuando tiene alguna cuota atrasada durante un periodo menor de tres meses | En mora, cuando el cliente ha dejado de pagar una o más cuotas durante tres meses o más. |
| Modelos | 1. Modelo de predicción de entrada en inversión irregular | 2. Modelo de salida de inversión irregular | 3. Modelo de predicción de salida de mora en un periodo corto de tiempo (45 días) 4. Modelo de predicción de no salida de mora en un largo periodo (dos años). |
| Estado respecto a la deuda | Modelos |
| Al corriente de pago | 1. Modelo de predicción de entrada en inversión irregular |
| En inversión irregular, cuando tiene alguna cuota atrasada durante un periodo menor de tres meses | 2. Modelo de salida de inversión irregular |
| En mora, cuando el cliente ha dejado de pagar una o más cuotas durante tres meses o más. | 3. Modelo de predicción de salida de mora en un periodo corto de tiempo (45 días) 4. Modelo de predicción de no salida de mora en un largo periodo (dos años). |
¿Por qué un pipeline de ML para gestión de deuda?
En el ámbito de análisis de riesgos se utilizan modelos matemáticos tradicionales como son las regresiones logísticas. Estos modelos son sencillos y muy interpretables; pero, a veces no alcanzan los valores de rendimiento de otros métodos de ML no lineales. En AI Factory encontramos un balance entre las metodologías más tradicionales estandarizadas en riesgos, las cuales nos ayudan a tener una referencia de la cual partir, y la innovación, que nos permite crear modelos productivizables y con mayor poder predictivo.
Al abordar diferentes problemas relacionados con la gestión de deuda y aplicar modelos de ML para resolverlos, nos dimos cuenta de que había una serie de pasos que se repetían continuamente, como es habitual en este tipo de proyectos. Para poder ser más ágiles, decidimos unificar estas fases en lo que llamamos nuestro pipeline de modelización, el cual nos permite reutilizar código y automatizar procesos en diferentes proyectos.
Partimos de algunas premisas:
| Nuestros modelos se centran en el aprendizaje supervisado con conjuntos de datos tabulares para predecir variables, generalmente de tipo binario. | |
| Manejamos una cantidad considerable de variables – más de 1800 en algunos casos – que incluyen datos comportamentales, sociodemográficos, transaccionales y niveles de deuda. Esta diversidad y volumen de datos exigen un proceso de reducción de dimensionalidad consistente. | |
| Nos enfrentamos a fechas de entrega ajustadas, para las cuales debemos construir modelos efectivos y validarlos previamente. Un pipeline automatizado acelera significativamente este proceso. | |
| Es imprescindible crear modelos explicables que nos permitan interpretar sus resultados para así trasladarlos a las unidades de negocio. | |
| La tramificación del score, aspecto que será detallado más adelante, es necesaria para una evaluación precisa y adaptada a diferentes contextos. |
La estandarización que establece nuestro pipeline también nos ayuda a reducir el Time To Value, es decir, el tiempo que tardamos en aportar valor, cuando comenzamos un nuevo proyecto con la misma área de negocio. Asimismo, conforme vamos desarrollando nuevos productos y reutilizando este pipeline, encontramos puntos de mejora y lo actualizamos.
Nuestra propuesta: desmenuzando nuestro pipeline de ML
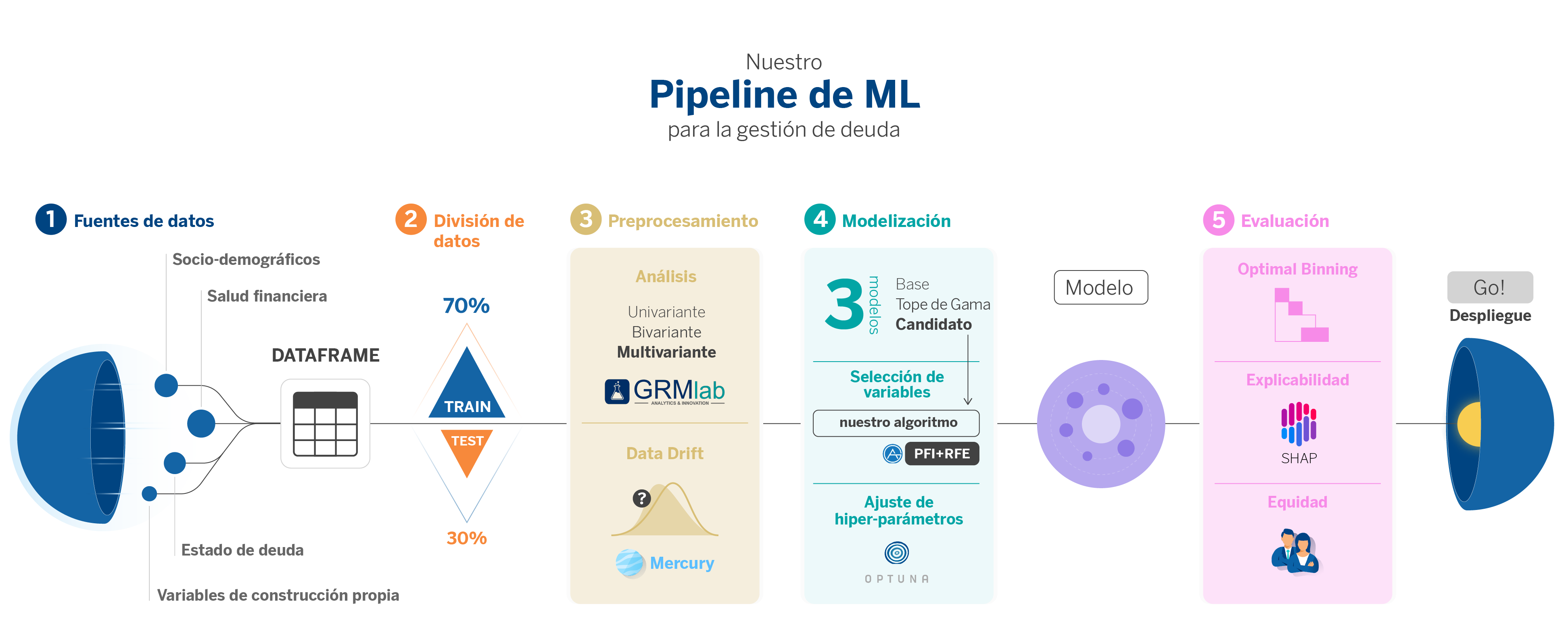
A partir de aquí, proponemos recorrer todas las fases de nuestro pipeline, que cubre el ciclo de vida completo de la construcción de un modelo, comenzando con el tablón de datos generado en la fase de Extracción, Transformación y Carga (ETL) y culminando con la implementación del modelo ya optimizado y listo para su despliegue en producción.
A lo largo de este camino, nos enfocaremos especialmente en aquellas fases que presentan una mayor complejidad técnica y en las que hemos investigado nuevas librerías menos conocidas que facilitan el trabajo, o mejoran las ya conocidas.
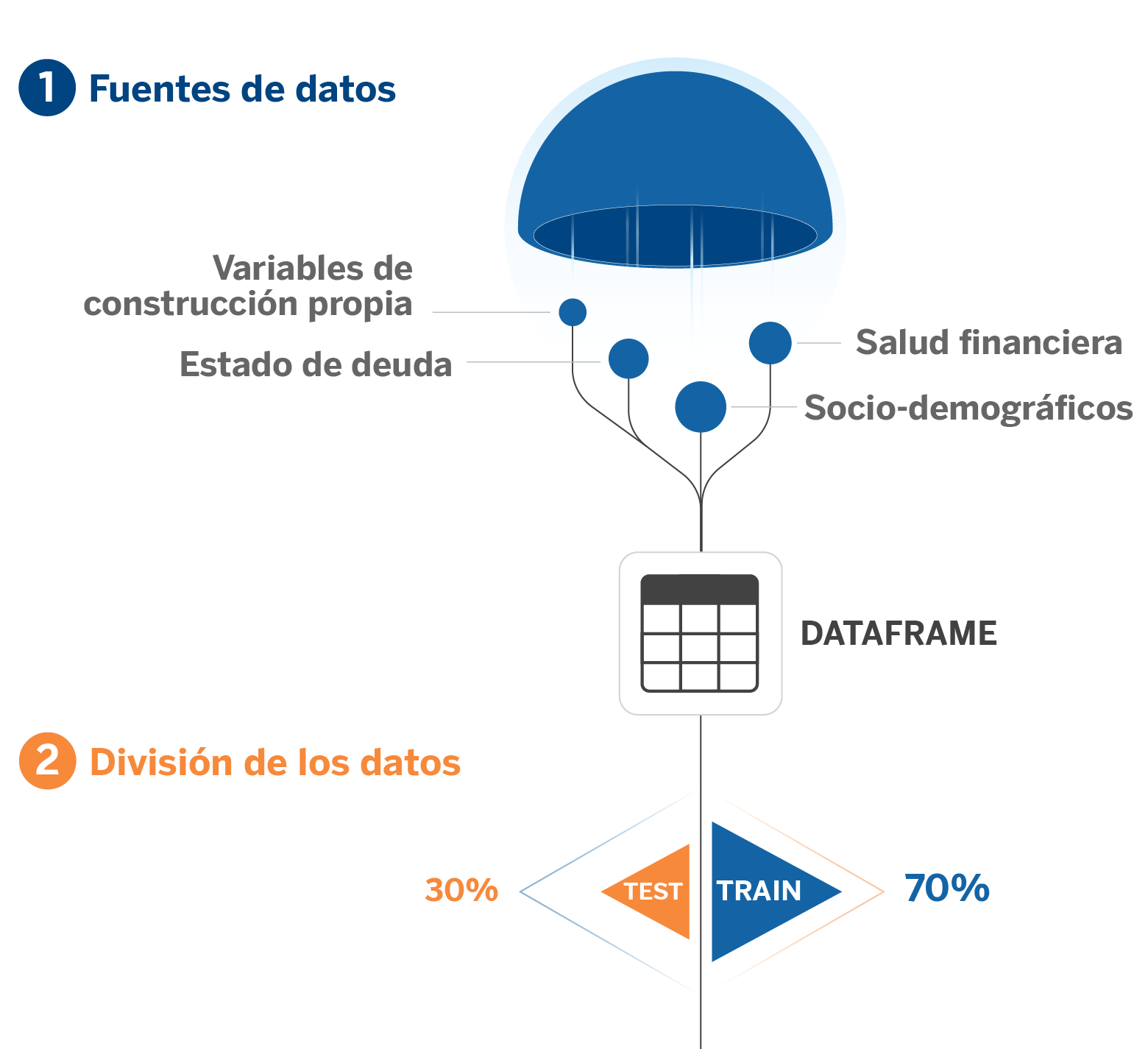
1. Construcción del dataset: ETL (Extract, transform, load)
El primer paso siempre es la construcción del tablón. Como hemos dicho, la mayoría de problemas que resolvemos son con datos tabulares y esto implica la construcción de una tabla mediante una ETL usando las distintas fuentes de datos disponibles.
Hacemos uso de variables sociodemográficas, de comportamiento financiero, de situación de la deuda y algunas otras generadas con feature engineering, esto en función de cuál es nuestra variable objetivo. Todo esto resulta en un tablón final donde tenemos el target (objetivo) y todas las variables que queremos usar para predecirlo.
2. División de los datos
Seguidamente, como en todo proyecto de ML, realizamos una división de los datos y selección de variables. En nuestro caso realizamos una primera división (comúnmente conocido como split en inglés) entre datos destinados a las fases de entrenamiento, validación y test. La muestra de test corresponde a una división temporal de los datos más recientes, para así tener una referencia clara de cómo el modelo funcionará en producción al simular un escenario de inferencia.
3. Preprocesamiento
Posteriormente, realizamos una preselección de variables a través de un análisis univariante, bivariante y multivariante utilizando GRMLab, una herramienta interna para el desarrollo de modelos del área de Riesgos de BBVA. Así, acotamos la cantidad de variables y optimizamos el conjunto de datos para la modelización.
El siguiente paso crucial en nuestro proceso es identificar y eliminar las variables cuyas distribuciones varían significativamente con el tiempo, lo que en inglés se denomina data drift. Esta acción es esencial para prevenir el deterioro del modelo en un entorno productivo y para reducir el riesgo de overfitting (sobreajuste); es decir, para garantizar que el modelo generalice bien. En resumen, para desarrollar un modelo estable y robusto.

Para abordar este desafío, utilizamos algoritmos avanzados de la biblioteca open-source Mercury, desarrollada por algunos de nuestros compañeros de AI Factory. Mercury destaca por proporcionar herramientas eficientes para agilizar el proceso de creación de modelos de aprendizaje automático.
Mercury-monitoring incluye dos algoritmos específicos que detectan cambios en la distribución de las variables tanto a nivel univariante como multivariante. Esto nos permite identificar y descartar aquellas variables cuya distribución cambia significativamente antes de proceder a la construcción del modelo.
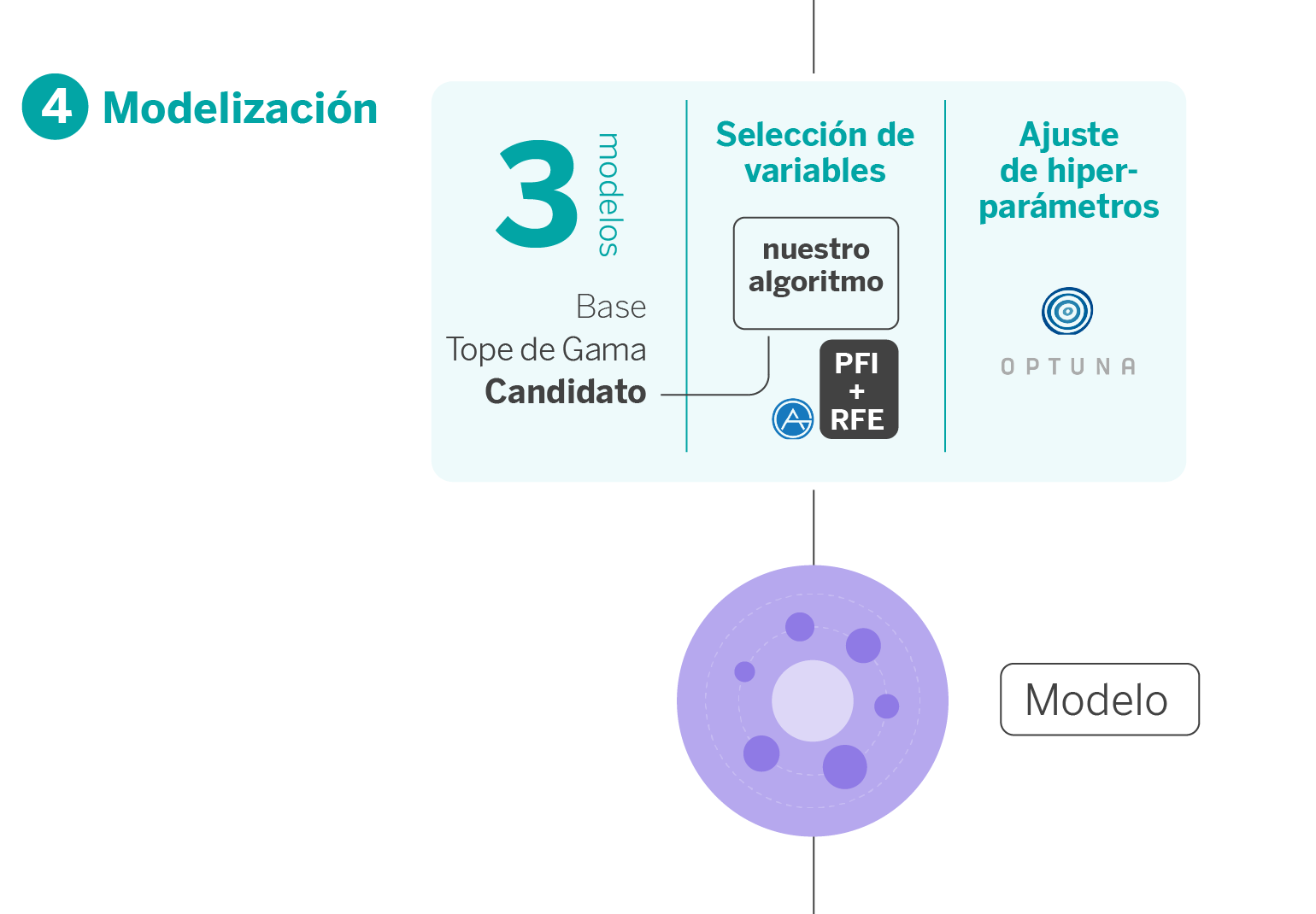
4. Modelización
En la etapa de modelización, nuestro pipeline genera tres modelos, cada uno con un propósito específico.
- Modelo Baseline: Este modelo se basa en la metodología tradicional de riesgos y sirve como referencia de rendimiento mínimo. Simulamos el enfoque que se hubiera aplicado con técnicas convencionales como regresiones logísticas.
- Modelo complejo no productivizable: Este modelo lo construimos usando AutoGluon1, una librería de AutoML open-source creada por AWS que destaca por ser de ayuda para generar modelos de manera muy ágil y hacerlos altamente predictivos, esto con pocas líneas de código a partir de los datos “crudos”. Este modelo actúa como un techo de rendimiento, mostrándonos el máximo potencial predictivo. Aunque es altamente eficaz, su naturaleza intrincada lo hace complejo para su implementación en la infraestructura estratégica de Riesgos, principalmente debido a su falta de transparencia e interpretabilidad, aspectos críticos para la comunicación con negocio.
- Modelo candidato productivizable: Este es el modelo que utilizamos. La selección del modelo candidato implica encontrar el equilibrio entre tipo de algoritmo, selección de variables y optimización de hiperparámetros. Dadas las restricciones de tiempo y recursos computacionales, desarrollamos una solución secuencial que aborda estos tres aspectos de manera eficiente. Comenzamos con una lista de algoritmos compatibles con nuestro entorno y procedemos con una validación cruzada de series temporales (conocido en inglés como time series cross-validation) para asegurar un rendimiento sólido y realista.
Cada uno de estos modelos cumple un rol crucial en nuestra estrategia de modelización, asegurando que el modelo final sea robusto, interpretable y adecuado para su implementación en un entorno bancario real.
Selección de variables finalistas
La selección de variables (Feature Selection) es fundamental, especialmente cuando trabajamos con conjuntos de datos grandes. El objetivo aquí es identificar y descartar aquellas variables redundantes que no aportan información significativa al modelo.
Partimos del hecho de que tenemos muchísimas variables. Como computacionalmente es imposible ir eliminando las variables una a una en distintas iteraciones y optimizar los hiperparámetros del modelo en cada paso, utilizamos una técnica llamada PFI+RFE2, desarrollada por AutoGluon para eliminar las variables redundantes de una forma más eficiente.
Optimización de hiperparámetros
Optimizar los hiperparámetros es esencial para garantizar un rendimiento óptimo del modelo cuando se despliegue en producción. Dentro de nuestro proceso de modelización, hemos explorado varias metodologías y frameworks del estado del arte para mejorar la eficiencia de nuestros modelos:
- AutoGluon. Como se explicó anteriormente, este framework de AutoML desarrollado por Amazon AWS ha sido entrenado con muchos datasets. Comienza la búsqueda de hiperparámetros desde unos valores iniciales que generalizan muy bien (transfer learning). Dado que el punto de partida es bueno, la búsqueda de hiperparámetros óptimos es más rápida. Además, ofrece varios algoritmos de búsqueda distintos. Entre ellos, Random Searcher, Bayesian Optimization y Reinforcement Learning Searcher.
- FLAML: Es una librería de AutoML desarrollada por Microsoft que genera diversas combinaciones de hiperparámetros dentro del espacio de búsqueda definido. Comienza la búsqueda desde una combinación poco compleja y de menor tiempo de entrenamiento. Seguidamente, empieza a entrenar con combinaciones cada vez más complejas y computacionalmente costosas, ajustándose a un presupuesto de tiempo predeterminado y añadiendo complejidad según sea posible. En resumen, es un método eficiente que reduce los costes computacionales sin afectar a la convergencia hacia la solución óptima.
- Optuna. Es un framework centrado en la optimización de hiperparámetros. Permite una customización completa del objetivo a optimizar y del espacio de búsqueda de hiperparámetros. Además, nos ayuda a seleccionar una división aleatoria de train/test o temporal (time series cross-validation). Se comienza definiendo una función objetivo customizable, un espacio de búsqueda y se elige un algoritmo de hiperparámetros que itera el mismo número de veces que intentos seleccionados. Una de sus mayores ventajas es la capacidad de optimización multiobjetivo.
Dada la naturaleza de nuestro caso de uso, nos decantamos por este último framework para nuestro pipeline porque nos permite maximizar el AUC (Area Under the ROC Curve) y minimizar el overfitting3. También lo elegimos por permitir time series cross-validation que, por ejemplo, AutoGluon y FLAML no permiten.
Con estas metodologías, una vez seleccionado el algoritmo óptimo, realizada la Permutation Feature Importance y completada la optimización de hiperparámetros, obtenemos como resultado un modelo candidato sólidamente configurado y listo para su implementación práctica. Pero, antes es necesario evaluarlo.
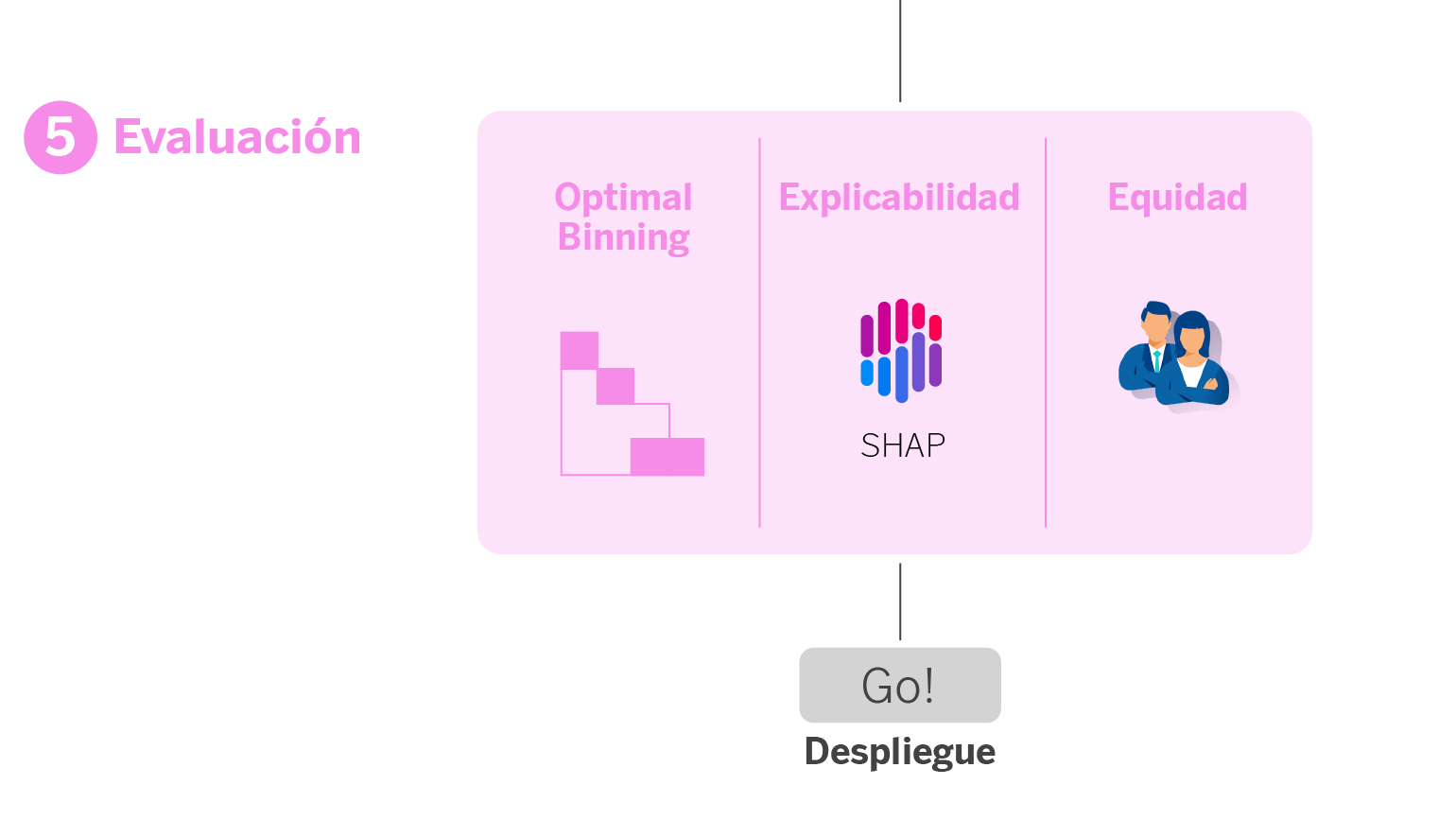
5. Módulo de evaluación
Este módulo es una etapa vital en nuestro proceso de modelización, donde evaluamos el modelo para asegurarnos que sea preciso, comprensible y justo, adecuándose a las necesidades y diversidad de nuestros clientes, además de alinearse con nuestros estándares éticos y de negocio.
Es un módulo de evaluación exhaustivo, que nos permite identificar cualquier tipo de problema que pueda tener el modelo y retroceder a tiempo en alguno de los pasos anteriores. En esta fase:
- Realizamos una evaluación global del modelo. Utilizamos métricas como el índice Gini4, el recall y la matriz de confusión para evaluar el rendimiento general del modelo.
- Segmentamos las métricas. No todos los clientes son iguales, por lo que también evaluamos el modelo por segmentos, como tipo de producto financiero o historial de refinanciación del cliente. Esto nos ayuda a entender cómo funciona el modelo para diferentes grupos de clientes.
- Medimos la estabilidad temporal y deriva (drift). Verificamos que el modelo mantenga su rendimiento a lo largo del tiempo y que no haya desviaciones significativas (drift) en los datos, lo cual es crucial para su aplicabilidad a largo plazo.
- Aplicamos Optimal Binning para la gestión de riesgos. En lugar de usar un solo umbral para decisiones de riesgo, empleamos Optimal Binning para discretizar el score del modelo en intervalos. Esto permite a negocio ofrecer acciones específicas según la criticidad del cliente.
- Interpretamos a través de técnicas de explicabilidad. Utilizamos la librería SHAP para entender el impacto de las variables en el modelo. Esto nos ayuda a interpretar el comportamiento del modelo y a comunicar de manera efectiva su funcionamiento tanto internamente como con los stakeholders del negocio.
- Evaluamos la equidad o fairness. Realizamos un análisis de fairness para asegurarnos de que el modelo no incurra en discriminación de género.
6. ¡Despliegue!
Si todos los análisis diseñados en el módulo de evaluación anterior son correctos, podemos decir que ya tenemos el modelo listo para ponerlo en producción. A continuación, quedaría monitorizar este modelo para hacer seguimiento de su rendimiento con el paso del tiempo y que no haya drift en los datos; en este caso, tocará reentrenarlo.
Takeaways: ¿dónde reside el valor diferencial de nuestro pipeline?
Si nos fijamos en las fases de nuestro pipeline, parece un pipeline como cualquier otro. Lo que marca la diferencia es la inclusión de diferentes librerías del estado del arte, tanto externas como internas (GRMLab y Mercury), que pueden ayudarte a agilizar el proceso de desarrollo, además de ganar en precisión y así maximizar su poder predictivo. A continuación, compartimos una lista de las librerías de código abierto utilzadas en cada fase de nuestro pipeline.
Selección del algoritmo
AutoGluon, para crear modelos con un alto nivel predictivo en menos tiempo, a partir de datos crudos y con pocas líneas de código. Esto permite comparar el performance y overfitting de diferentes algoritmos para escoger un ganador.
Selección de variables finalistas
PFI+RFE, de AutoGluon, para eliminar variables redundantes o que añaden poca información de forma eficiente.
Optimización de hiperparámetros
Flaml, para adecuar los tiempos de búsqueda de hiperparámetros a tus necesidades.
AutoGluon, para encontrar los hiperparámetros óptimos mucho más rápido.
Optuna, para personalizar la búsqueda de acuerdo a tu objetivo, pudiendo definir más de uno.
Módulo de evaluación
SHAP, para obtener una comprensión más amplia del impacto de las variables en el modelo y poder explicárselo mucho mejor a negocio.
Monitorización
Mercury-monitoring, para asegurar que los modelos en producción conservan su desempeño a lo largo del tiempo y alertar en caso de deterioro del modelo de la necesidad de reentrenar.
Conclusiones: simbiosis tradición-innovación para crear modelos productivizables
El pipeline que os hemos contado nos ha permitido agilizar el proceso de desarrollo de modelos de gestión de deuda; pero, este pipeline puede usarse en cualquier caso de uso en el que se aplique aprendizaje supervisado.
Al aplicarse las nuevas librerías del estado del arte en las tradicionales fases de un ciclo de desarrollo de productos de ML conseguimos una mayor precisión y eficiencia: simbiosis perfecta entre tradición e innovación.
Notas
- Its modeling methodology consists of training layers of models and assembling them by means of multilayer stackings. It trains several models in the first layer, from which it obtains some predictions that will be the features that go to the next layer and with which the following models will be trained. And so on until the predefined number of layers is reached. At the same time it does bagging, that is, it trains each of the models with a k-fold CV and passes the out-of-fold predictions to the next layer to try to mitigate the overfitting generated by passing the predictions of the training set. To all this, we must add the hyperparameter optimization performed in each model. ↩︎
- This approach starts by permuting the variables one by one, several times, and evaluates how each permutation affects the performance of the model. If the performance does not change significantly after permuting a variable, we conclude that that variable contributes little information. Conversely, if the permutation causes a large loss in performance, it means that the variable is important. The variables are then ranked according to their importance and progressively eliminated in blocks, evaluating at each step the impact on performance. This process is repeated until no more variables can be discarded without negatively impacting the model. In this way, we manage to significantly reduce the number of variables while maintaining the efficiency of the model.↩︎
- Most models with better validation metrics tend to have higher overfitting, in addition to quite complex parameterizations that can lead to robustness problems and performance degradation over time.↩︎
- The Gini index is the benchmark metric used for its ability to measure the model’s ordering power, which helps determine how effectively the model can identify predetermined observations based on the order of its predictions. This allows us to compare the performance of various models.↩︎